






此为网上整理,感谢dxy
创建数据表如下:
CREATE TABLE `test` (
`id` INT(10) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL,
`category_id` INT(10) NOT NULL,
`date` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
ENGINE=MyISAM
ROW_FORMAT=DEFAULT;
INSERT INTO `test` (`id`, `name`, `category_id`, `date`)
VALUES
(1, 'aaa', 1, '2010-06-10 19:14:37'),
(2, 'bbb', 2, '2010-06-10 19:14:55'),
(3, 'ccc', 1, '2010-06-10 19:16:02'),
(4, 'ddd', 1, '2010-06-10 19:16:15'),
(5, 'eee', 2, '2010-06-10 19:16:35');
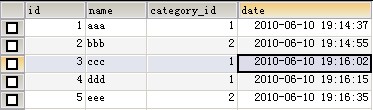
以category_id分组:
/*查询每个分组最新的一条记录*/
(1)select a.category_id,a.name,a.id ,max(a.date) rq from test a group by a.category_id;
(2)select * from test t where t.id in (select SUBSTRING_INDEX(group_concat(a.id order by a.date desc),',',1) from test a group by a.category_id);
(3)select * from (select * from test t order by t.date desc) a group by a.category_id;
/*查询每个分组最新的n个记录 (没有n个取最多个)*/
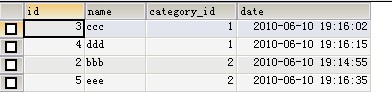
(1)SELECT * FROM test a WHERE 2> (SELECT COUNT(*) FROM test b WHERE b.category_id =a.category_id AND b.date>a.date) ORDER BY a.category_id,a.date;
(2)SELECT a.* FROM test a WHERE EXISTS (SELECT COUNT(*) FROM test b WHERE b.category_id=a.category_id AND b.date > a.date HAVING COUNT(*) < 2) ORDER BY a.category_id;
上面这2句的理解:
对TEST表 的每一行适用WHERE条件,如果对于当前遍历行,TEST表中不存在或只存在一行其时间比当前行大,则取出。















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









