







简介:本项目聚焦于使用C语言编写Web服务器源码,详细说明了其工作原理与C语言编程实践,包括文件I/O、套接字编程、多线程或多进程、内存管理和错误处理。同时,涵盖加密技术的应用,如SSL/TLS和AES,以及通过源码深入理解网络编程、文件操作和加密机制。 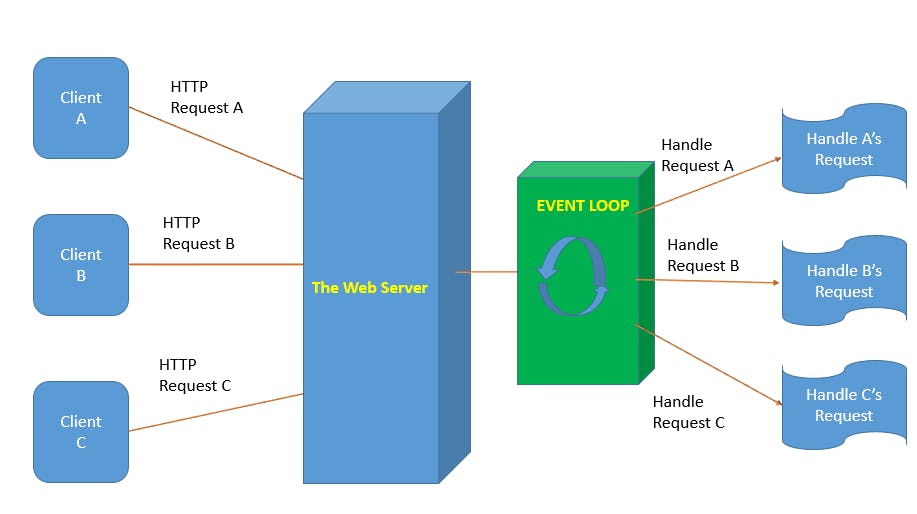
1. C语言Web服务器源码实现
简介
在本章中,我们将引领读者走进C语言编写的Web服务器的源码世界。在深入探讨实现细节之前,让我们先概述这个过程涉及的基本概念与步骤。Web服务器的工作是响应客户端的HTTP请求,并提供相应的HTML页面或数据。使用C语言来实现一个Web服务器需要对网络编程有深刻的理解,尤其是对TCP/IP协议栈和套接字编程的掌握。
源码概述
在开始编写服务器代码之前,我们需要考虑以下几个关键组件: - 监听端口: 服务器需要在特定端口上监听HTTP请求。 - 请求处理: 接收到请求后,服务器需要解析请求内容,如URI和HTTP头等。 - 内容响应: 根据请求内容,服务器将决定是提供静态文件还是生成动态内容。 - 响应发送: 服务器构建HTTP响应,包括状态码和内容数据,并将其发送回客户端。
实现步骤
实现一个基础的Web服务器涉及以下步骤: 1. 初始化服务器: 设置套接字选项,绑定IP地址和端口号,并开始监听。 2. 接收请求: 接收来自客户端的连接请求,并建立连接。 3. 解析请求: 读取并解析HTTP请求,提取请求行、头和可能的体。 4. 处理请求: 根据请求类型和路径,处理请求并决定响应内容。 5. 生成响应: 构造HTTP响应,包括设置正确的状态码和内容类型。 6. 发送响应: 将构建的响应数据包发送给客户端。 7. 资源清理: 关闭连接并释放所有分配的资源。
通过这种方式,我们从一个高层次开始理解Web服务器的工作原理,并为后续章节深入讨论各个组成部分打下基础。随着章节的推进,我们将逐步深入每个步骤,探究如何使用C语言实现这些复杂的网络操作。
2. 网络请求接收与解析
要创建一个功能完备的Web服务器,核心任务之一就是能够正确地接收和解析来自客户端的网络请求。这要求我们对网络编程有一定的了解,特别是网络通信协议以及套接字编程。接下来,我们将深入探讨如何捕获请求数据,并对请求内容进行解析。
2.1 网络编程基础
2.1.1 网络通信协议概述
在互联网上,数据的传输遵循特定的通信协议,以确保数据包能被正确地发送和接收。最基础和广泛使用的网络协议是 TCP/IP(传输控制协议/互联网协议),它定义了数据在网络中的传输方式。TCP/IP 协议栈从低到高包括链路层、网络层、传输层和应用层。
- 链路层负责物理网络接口的数据帧传输。
- 网络层主要负责数据包的寻址和路由。
- 传输层提供端到端的数据传输服务,例如 TCP 为数据提供可靠传输服务。
- 应用层负责处理特定的应用程序细节,例如 HTTP 协议。
我们的 Web 服务器将主要与 TCP 协议打交道,因为 HTTP 协议本质上是建立在 TCP 协议之上的。通过 TCP,我们能够实现数据的可靠传输。
2.1.2 套接字编程基础
套接字(Socket)是通信的端点,是网络通信的基本操作单元。在C语言中,套接字编程允许我们创建和使用套接字来建立网络连接,发送和接收数据。套接字编程涉及以下基本概念:
- 套接字类型,如 TCP 套接字和 UDP 套接字。
- 套接字地址族,通常使用的是 IPv4 和 IPv6。
- 端口号,用于标识服务器上不同的网络服务。
接下来,我们将通过示例代码来展示如何使用套接字进行基本的网络通信。
2.2 请求数据的捕获
2.2.1 端口监听和连接建立
为了让 Web 服务器能够接收到来自客户端的请求,我们首先需要让服务器在特定端口上进行监听。以下是一个简单的 C 语言代码示例,演示了如何创建一个套接字并监听 8080 端口:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define PORT 8080
int main() {
int server_fd, new_socket;
struct sockaddr_in address;
int opt = 1;
int addrlen = sizeof(address);
char buffer[1024] = {0};
// 创建套接字
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
perror("socket failed");
exit(EXIT_FAILURE);
}
// 设置套接字选项,允许重用地址和端口
if (setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt))) {
perror("setsockopt");
exit(EXIT_FAILURE);
}
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
// 绑定套接字到指定 IP 和端口
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address))<0) {
perror("bind failed");
exit(EXIT_FAILURE);
}
// 开始监听端口
if (listen(server_fd, 3) < 0) {
perror("listen");
exit(EXIT_FAILURE);
}
// 接受客户端连接
if ((new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t*)&addrlen))<0) {
perror("accept");
exit(EXIT_FAILURE);
}
// 接收数据
read(new_socket, buffer, 1024);
printf("Message from client: %s\n", buffer);
// 发送响应
send(new_socket, "Hello from server", strlen("Hello from server"), 0);
printf("Hello message sent\n");
// 关闭套接字
close(server_fd);
return 0;
}
在这段代码中,我们首先创建了一个 TCP 套接字,并设置了可重用地址和端口的选项。接着我们将套接字绑定到了 IP 地址 INADDR_ANY 和端口 PORT (在这里为 8080)。之后,我们开始监听端口,等待客户端的连接。一旦客户端连接,我们就读取数据,打印出来,再向客户端发送一条消息,最后关闭套接字。
2.2.2 数据包的接收与处理
数据包的接收通常通过套接字 API recv 或 read 函数完成。在服务器接收到客户端发来的请求后,需要对这些数据进行处理,以便从中提取出有用的信息。常见的数据包处理方式包括:
- 解析 HTTP 请求头,获取 HTTP 方法、URI、HTTP 版本等信息。
- 检查请求的完整性和格式的正确性。
- 捕获 HTTP 消息体中的数据(对于 POST 请求等)。
为实现以上步骤,我们将通过代码逐步解析 HTTP 请求的结构。下面展示了如何从连接套接字中接收数据,并进行初步的处理。
2.3 请求内容的解析
2.3.1 HTTP请求格式解析
HTTP 请求格式是 Web 服务器必须理解和处理的核心数据。一个典型的 HTTP 请求格式如下:
GET /index.html HTTP/1.1
Host: ***
User-Agent: Mozilla/5.0 (compatible; MyBot/1.0; +***
要解析 HTTP 请求,我们通常关注以下部分:
- 请求行(例如:
GET /index.html HTTP/1.1),其中包含了 HTTP 方法、请求的资源路径和 HTTP 版本。 - 请求头,以键值对的形式提供了关于请求的元信息。
- 空行,标志着请求头的结束。
- 请求体,包含了附加的数据信息(对于
POST、PUT等方法)。
通过解析这些部分,服务器能理解客户端的请求类型以及需要返回何种数据。
2.3.2 URI解析与处理
统一资源标识符(Uniform Resource Identifier, URI)是用于标识资源的字符串,例如 Web 页面、图片、视频等。URI 解析是将请求行中的请求路径部分进行分解,从中提取出需要的信息,如路径、查询字符串等。处理完这些信息后,服务器就可以确定应该向客户端返回哪个资源或执行哪种处理。
以下是一个简单的 URI 解析函数示例:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void parse_uri(const char* uri) {
const char* path = strchr(uri, '/');
if (path != NULL) {
path = &path[1];
char* query = strchr(path, '?');
if (query != NULL) {
*query = '\0'; // 截断字符串,只保留路径部分
printf("Path: %s\n", path);
printf("Query: %s\n", query + 1);
} else {
printf("Path: %s\n", path);
printf("Query: None\n");
}
} else {
printf("Invalid URI\n");
}
}
int main() {
parse_uri("/index.html?page=home");
return 0;
}
通过这段代码,我们可以解析 URI 并分别输出路径和查询字符串。服务器会根据解析出来的路径来定位资源或执行相应的逻辑。
在完成请求内容解析之后,服务器就能针对不同的请求类型进行进一步处理,如查询静态资源、执行服务器端脚本或者查询数据库,并返回相应的响应数据。
3. 静态文件处理
3.1 文件系统的访问与管理
在Web服务器中,静态文件处理是核心功能之一。静态文件指的是不需要服务器端脚本处理,直接就可以发送给客户端的文件,如HTML页面、图片、CSS样式表和JavaScript脚本等。
3.1.1 文件的读写操作
在C语言中,文件读写操作通常通过标准I/O库函数 fopen , fread , fwrite , fclose 等来完成。打开文件时,需要指定文件的打开模式,如只读模式( "r" ),读写模式( "r+" ),追加模式( "a" )等。
#include <stdio.h>
int main() {
FILE *file;
char buffer[1024];
// 打开文件用于读取
file = fopen("example.txt", "r");
if (file == NULL) {
perror("Error opening file");
return -1;
}
// 读取文件内容
while (fgets(buffer, sizeof(buffer), file)) {
puts(buffer);
}
// 关闭文件
fclose(file);
return 0;
}
在上述代码示例中,首先通过 fopen 函数以只读模式( "r" )打开一个文件,然后使用 fgets 函数逐行读取文件内容并输出到控制台,最后通过 fclose 函数关闭文件。这个过程涉及到的错误检查也是不可忽视的一部分,确保文件操作能够正确地执行。
3.1.2 目录的遍历和文件查找
在Web服务器中,我们经常需要对目录下的文件进行遍历和查找。这可以通过 opendir , readdir , closedir 等函数实现。以下是一个简单的示例,展示了如何遍历一个目录下的所有文件:
#include <stdio.h>
#include <dirent.h>
void print_directory_content(const char *dir) {
DIR *dp;
struct dirent *entry;
dp = opendir(dir);
if (dp == NULL) {
perror("Unable to open directory");
return;
}
while ((entry = readdir(dp)) != NULL) {
if (entry->d_type == DT_REG) {
printf("%s\n", entry->d_name);
}
}
closedir(dp);
}
int main() {
print_directory_content("./static");
return 0;
}
在这段代码中,使用 opendir 函数打开目录, readdir 函数读取目录内容,并检查每个目录项的类型(通过 d_type 字段)。如果是常规文件( DT_REG ),则打印文件名。最后,使用 closedir 函数关闭目录。
3.2 静态文件的响应
当Web服务器接收到一个请求,需要提供静态文件的内容时,服务器必须读取文件内容,将其放入HTTP响应体中,并设置正确的HTTP状态码和响应头。
3.2.1 文件状态码的设置
HTTP状态码表明了HTTP请求/响应的处理结果。静态文件通常使用 200 OK 表示请求成功,如果文件不存在,则返回 404 Not Found 。
#include <stdio.h>
#include <httpd.h> // Apache HTTPD服务器的HTTP响应头定义库
void send_not_found_response() {
printf("HTTP/1.1 404 Not Found\r\n");
printf("Content-Type: text/plain\r\n");
printf("Content-Length: 11\r\n");
printf("\r\n");
printf("Not Found\n");
}
在这个函数中,我们发送了 404 Not Found 状态码, Content-Type 和 Content-Length 响应头,并附带一条简单的错误信息。
3.2.2 文件内容的读取和传输
完成状态码的发送后,接下来是文件内容的读取和传输。这通常涉及到将文件内容直接复制到套接字的输出缓冲区。
void send_file_content(FILE *file) {
char buffer[1024];
size_t bytes_read;
while ((bytes_read = fread(buffer, 1, sizeof(buffer), file)) > 0) {
fwrite(buffer, 1, bytes_read, stdout); // 假设标准输出连接到客户端套接字
}
}
上面的代码中, send_file_content 函数从给定的文件指针中读取数据,并直接输出到标准输出(在实际的Web服务器中,应该是输出到与客户端连接的套接字)。这个过程会一直进行,直到文件读取完毕。
对于下一章的内容,我们将讨论动态内容处理。这涉及到服务器端脚本的执行以及数据库的交互,是Web开发中非常重要的部分。
4. 动态内容处理
4.1 动态内容生成机制
4.1.1 服务器端脚本执行环境
在Web服务器中,动态内容生成机制是提供交互性和个性化用户体验的关键。这一机制通常涉及到服务器端脚本语言的运行环境。在C语言中,虽然原生并不支持脚本执行,但我们可以通过集成解释器来实现这一功能。例如,集成Lua解释器或使用CGI(Common Gateway Interface)来执行外部脚本。
服务器端脚本环境的设置通常需要考虑以下方面:
- 安全性 :脚本环境应与主服务器进程隔离,以防止恶意代码对服务器造成伤害。
- 性能 :脚本执行应尽可能高效,减少对服务器性能的影响。
- 灵活性 :能够支持多种脚本语言,并能够方便地添加新的语言支持。
在实现上,这通常涉及到子进程的创建和管理。每个客户端请求动态内容时,主服务器进程会启动一个子进程来运行脚本,然后将脚本的输出发送给客户端。
4.1.2 动态内容与模板渲染
动态内容的生成往往伴随着模板渲染技术的使用。模板允许开发者定义网页的基本结构,并使用变量和控制结构来插入动态生成的数据。在C语言中实现模板渲染,我们可以预先定义好模板文件,然后在服务器端脚本运行时,将需要动态生成的数据填充进模板中。
例如,考虑一个简单的HTML模板,它可能包含一些占位符:
<html>
<head>
<title>欢迎页面</title>
</head>
<body>
<h1>欢迎, <%= user_name %>!</h1>
<p>我们很高兴见到你。</p>
</body>
</html>
在这个HTML模板中, <%= user_name %> 是一个占位符,将会在渲染时被动态替换为用户的名字。在C语言中,可以通过字符串处理函数找到这个占位符,并替换为相应的值。
在实现模板渲染时,需要注意以下几点:
- 模板解析 :解析模板文件,识别变量和控制结构。
- 数据绑定 :将从数据库或其他数据源获取的数据与模板进行绑定。
- 渲染输出 :最终将处理后的模板输出为HTML或其他格式的字符串,发送给客户端。
4.2 数据库交互与动态内容
4.2.1 数据库连接与查询操作
数据库是Web应用中存储和检索数据的重要组件。与数据库的交互是动态内容生成中的一个关键步骤。在C语言中,我们通常会使用如libpq(用于PostgreSQL数据库)或MySQL C API这样的数据库客户端库来进行数据库连接与查询。
数据库连接通常遵循以下步骤:
- 连接数据库 :通过指定的数据库URL或连接字符串创建到数据库的连接。
- 执行查询 :发送SQL查询语句到数据库,并获取查询结果。
- 处理结果 :对查询结果进行处理,以便用于动态内容的生成。
- 关闭连接 :完成操作后关闭数据库连接。
下面是一个使用MySQL C API连接数据库并执行查询的示例代码:
#include <mysql.h>
#include <stdio.h>
int main() {
MYSQL *conn;
MYSQL_RES *res;
MYSQL_ROW row;
// 初始化连接
conn = mysql_init(NULL);
if (conn == NULL) {
fprintf(stderr, "mysql_init() failed\n");
return 1;
}
// 连接到数据库
if (mysql_real_connect(conn, "host", "user", "password", "database", 0, NULL, 0) == NULL) {
fprintf(stderr, "mysql_real_connect() failed\n");
mysql_close(conn);
return 1;
}
// 执行查询
if (mysql_query(conn, "SELECT * FROM users")) {
fprintf(stderr, "mysql_query() failed\n");
mysql_close(conn);
return 1;
}
res = mysql_use_result(conn);
while ((row = mysql_fetch_row(res)) != NULL) {
printf("%s \n", row[0]);
}
// 清理
mysql_free_result(res);
mysql_close(conn);
return 0;
}
4.2.2 动态数据的模板填充与输出
当从数据库获取数据后,下一步就是将这些数据填充到模板中,并生成最终的动态内容。这一过程涉及到模板引擎的使用,或者通过C语言手动拼接字符串的方式。
例如,若使用C语言进行字符串拼接,我们可能会有如下代码:
char *username = "Alice";
char *template = "欢迎, %s!";
char *message = malloc(strlen(template) + strlen(username) + 1);
sprintf(message, template, username);
// 然后将message作为动态内容输出
虽然这种方式在简单场景下可行,但为了更好的灵活性和可维护性,推荐使用模板引擎。模板引擎负责将模板和数据相结合,生成最终的内容。许多模板引擎支持C语言绑定,或者可以嵌入C语言应用程序中。
在Web开发中,模板通常包含一些控制结构,例如循环和条件判断,它们允许生成更复杂和个性化的输出。通过模板引擎,这些结构可以被正确解析并基于数据进行执行。
动态内容的生成是一个涉及多个层面的过程,它不仅包括了数据库与应用程序之间的交互,还有模板的处理以及最终内容的输出。这些操作通常需要良好的错误处理机制,以确保在出现数据错误或模板问题时能够给出准确的反馈,而不会影响到整个服务器的稳定运行。
5. HTTP响应生成与发送
5.1 响应头的构造
5.1.1 HTTP状态码的正确使用
在构建HTTP响应头时,状态码的使用至关重要,它告诉客户端服务器处理请求的结果。HTTP状态码由三位数字组成,分为五个类别:1xx表示信息性状态码,2xx表示成功状态码,3xx表示重定向状态码,4xx表示客户端错误状态码,5xx表示服务器错误状态码。
以下是几个常用的HTTP状态码及其实现示例:
void send_response(int fd, int status_code) {
char *status_line = NULL;
switch (status_code) {
case 200: // OK
status_line = "HTTP/1.1 200 OK\r\n";
break;
case 404: // Not Found
status_line = "HTTP/1.1 404 Not Found\r\n";
break;
case 500: // Internal Server Error
status_line = "HTTP/1.1 500 Internal Server Error\r\n";
break;
default:
status_line = "HTTP/1.1 501 Not Implemented\r\n";
}
write(fd, status_line, strlen(status_line));
// 继续添加其他头部信息...
}
在这个函数中,我们根据传入的状态码 status_code 选择了不同的响应行。例如,如果请求的资源不存在,我们返回404状态码;如果服务器内部发生错误,返回500状态码。
5.1.2 内容类型与字符集的设置
内容类型(Content-Type)是响应头中一个关键字段,它告诉客户端返回数据的MIME类型。例如,如果是文本文件,可能是 text/html 或 text/plain ;如果是图片,则可能是 image/jpeg 等。
字符集(Charset)通常与内容类型一起使用,指示文档所用的字符编码。如 UTF-8 , ISO-8859-1 等。通过设置字符集,客户端能够正确地解码返回的数据。
void send_content_type(int fd, const char *content_type, const char *charset) {
char *header = malloc(sizeof(char) * (strlen(content_type) + strlen(charset) + 40));
sprintf(header, "Content-Type: %s; charset=%s\r\n\r\n", content_type, charset);
write(fd, header, strlen(header));
free(header);
}
在这个函数中,我们将内容类型和字符集组合成一个完整的头部信息,并发送给客户端。
5.2 响应数据的封装与传输
5.2.1 数据包的构建过程
响应数据通常包含实际的文件内容。在构建响应数据包时,需要注意HTTP头部和正文内容之间需要一个空行来分隔。
void build_response_packet(int fd, char *header, char *body) {
write(fd, header, strlen(header)); // 发送HTTP头部信息
write(fd, "\r\n", 2); // 发送空行,分隔头部和正文
write(fd, body, strlen(body)); // 发送正文内容
}
5.2.2 响应数据的发送机制
发送数据时,可能会遇到网络缓冲、数据包切割等问题,所以发送操作需要循环执行,直到所有数据都发送完毕。
ssize_t send_all(int fd, const void *data, size_t size) {
size_t total_sent = 0;
while (total_sent < size) {
ssize_t sent_bytes = send(fd, data + total_sent, size - total_sent, 0);
if (sent_bytes < 0) {
// 错误处理
return -1;
}
total_sent += sent_bytes;
}
return total_sent;
}
send_all 函数负责确保所有数据都被发送,返回值是发送的总字节数,如果返回-1表示发送过程中发生了错误。
以上就是第五章“HTTP响应生成与发送”的全部内容。在本章节中,我们深入探讨了如何构造响应头,包括状态码和内容类型的正确设置,以及如何构建和发送响应数据包。通过具体代码示例,我们展示了这些过程是如何在C语言的Web服务器实现中具体操作的,希望对您有所帮助。
6. C语言Web服务器高级技巧与优化
6.1 文件I/O操作优化
6.1.1 高效文件读写技术
在Web服务器中,文件I/O操作是频繁且耗时的,因此优化文件读写技术可以显著提升服务器性能。高效文件读写通常涉及以下几个方面:
- 预读取与后写入缓冲区 :在读取文件时,可以使用预读取技术,提前将文件内容加载到缓冲区中。在写入文件时,可以将数据先写入缓冲区,然后批量写入磁盘,从而减少磁盘I/O操作。
- 内存映射文件 :内存映射是一种高效的文件访问方法,它将磁盘文件内容映射到内存地址空间。当对内存中的数据进行读写操作时,实际上是对文件进行操作。这减少了数据在内核态与用户态之间的复制,提高了访问速度。
#include <sys/mman.h>
#include <stdio.h>
int main() {
int fd = open("example.txt", O_RDONLY); // 打开文件
if (fd == -1) {
perror("open");
return 1;
}
// 获取文件大小
off_t fsize = lseek(fd, 0, SEEK_END);
lseek(fd, 0, SEEK_SET);
// 映射文件到内存
char *addr = mmap(NULL, fsize, PROT_READ, MAP_SHARED, fd, 0);
if (addr == MAP_FAILED) {
close(fd);
perror("mmap");
return 1;
}
// 在这里可以像操作普通内存一样操作文件内容
printf("%s\n", addr);
// 取消映射
munmap(addr, fsize);
close(fd); // 关闭文件描述符
return 0;
}
6.1.2 缓存机制的应用
缓存是提升Web服务器性能的重要手段之一。合理的缓存策略可以减少对后端存储系统的访问,从而提高响应速度和并发处理能力。
- 缓存策略 :根据文件访问频率选择合适的缓存策略,如最近最少使用(LRU)、时间过期等。
- 缓存数据结构 :选择合适的数据结构来存储缓存数据,如使用哈希表来快速定位缓存项。
- 缓存一致性 :确保缓存内容与后端存储同步,避免读取到过时的数据。
6.2 套接字编程技巧与并发处理
6.2.1 高级套接字编程技术
套接字编程是网络通信的基础。高级套接字编程技术包括非阻塞I/O、IO复用技术(如select、poll、epoll)以及使用TCP选项提高性能。
- 非阻塞I/O :通过设置套接字为非阻塞模式,可以使得网络I/O操作不会挂起程序执行,从而提高程序的响应性和并发能力。
- IO复用 :使用IO复用技术可以在单个线程内同时监控多个文件描述符,适用于需要处理大量连接的服务器。
6.2.2 多线程或多进程并发模型
为了处理并发连接,Web服务器需要使用多线程或多进程模型。
- 多线程模型 :每个新连接创建一个线程来处理,简单直接。但是要注意线程同步和资源共享问题。
- 多进程模型 :每个新连接启动一个新的进程来处理。进程间独立,安全性能较好,但开销相对较大。
#include <pthread.h>
void* handle_client(void* arg) {
// 处理连接的代码
return NULL;
}
int main() {
pthread_t tid;
// 监听新连接并为每个连接创建线程
while (1) {
// 假设 connfd 是新连接的文件描述符
pthread_create(&tid, NULL, handle_client, (void*)&connfd);
}
// 等待所有线程结束
pthread_exit(NULL);
}
6.3 内存管理与错误处理
6.3.1 内存泄漏预防与检测
内存泄漏是C语言开发中的常见问题,需要在开发过程中采取措施预防,同时使用工具检测。
- 预防措施 :养成良好的编程习惯,例如及时释放不再使用的内存,使用智能指针管理内存。
- 检测工具 :使用Valgrind、AddressSanitizer等工具检测内存泄漏。
6.3.2 错误处理与异常管理
错误处理是程序健壮性的关键,良好的错误处理可以避免程序崩溃并提供有用的调试信息。
- 错误处理策略 :定义统一的错误处理框架,使用返回码或异常抛出错误信息。
- 日志记录 :记录错误日志,便于事后分析问题原因。
6.4 加密技术与性能优化
6.4.1 数据传输加密技术
随着网络安全要求的提高,Web服务器需要支持数据传输的加密技术,如SSL/TLS。
- SSL/TLS协议 :实现SSL/TLS可以保护数据传输过程中的安全,防止数据被窃取或篡改。
- 性能开销 :加密和解密数据会带来性能开销,需要合理配置以平衡安全与性能。
6.4.2 性能分析与瓶颈优化
性能分析是优化Web服务器性能的重要步骤,通过分析找出瓶颈并进行针对性优化。
- 性能分析工具 :使用gprof、perf等工具对程序进行性能分析。
- 优化策略 :根据分析结果调整算法、数据结构或系统配置,如增加缓存大小、优化I/O调度策略等。
通过上述章节内容,我们可以看到一个C语言编写的Web服务器在实现时需要考虑的诸多高级技巧与优化方法。这些方法的合理运用,可以显著提升服务器的性能和稳定性,确保在处理大量并发连接时仍能保持高效稳定的服务能力。
简介:本项目聚焦于使用C语言编写Web服务器源码,详细说明了其工作原理与C语言编程实践,包括文件I/O、套接字编程、多线程或多进程、内存管理和错误处理。同时,涵盖加密技术的应用,如SSL/TLS和AES,以及通过源码深入理解网络编程、文件操作和加密机制。















 76
76

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









