






一般我们说优化mysql,总是会将着眼点放在mysql的慢查询的优化上,或者字段的数据类型,mysql的分库/分表,读写分离,异或事务这些看上去高大上的东东上。但是,对于一些更加基础或者更加常识的地方,往往会加以忽视。就比如,本文将要提到的:mysql的查询本身的优化。
这次接到的优化任务出现的背景是:
我们有一个内部电话呼叫的系统,在下午使用客服相对较多的时候,在很随机的情况下,会出现突然的卡顿,这种现象维持的时间很短,检查的时候,往往发现cpu、内存、负载、网络,都很正常,查询错误日志也看不到异常。
系统用的是阿里云,2C4G,看负载的曲线也维持得很小很平稳,内存消耗也没有达到瓶颈。中间一度怀疑过对缓存的使用有问题,因为有很多临时数据都是通过cache在传输和保存的,调用频率也很高。于是,负责此项目的同学也做过很多方面的优化,想过很多招数。比如:
1、临时数据的保存从全量改为增量,大大降低了数据传输的量。
2、将数据库改成长连接,减少连接使用量。
原来我们使用的数据库是由阿里云提供的,后来降配了,长连接经常出现连接数不够的时候,又改为普通连接了。最后,我们又把mysql改成了自建,连接数2000,还是够用的。不过,即使使用长连接的时候,依然会出现卡顿,索性,就一直维持着使用普通连接了。
## 问题浮出水面
最近,这个优化的任务转到我手头了,于是开始系统地对这个系统做了一些检查。各种看参数,也都正常,没有明显的问题。直到用`iftop`检查的时候,问题终于浮出水面来了。
```bash
iftop -n
```
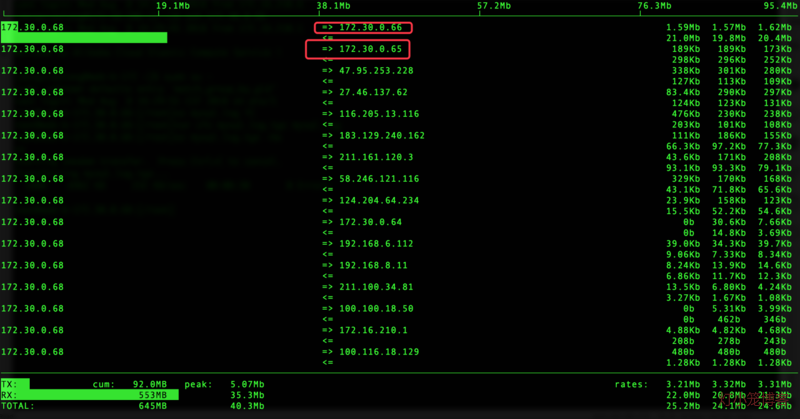
右侧第1列表示2s的平均值,同一个ip对应两行,第1行表示发送,第2行表示接收。
标红的地方,分别对应db(172.30.0.66)和cache(172.30.0.65)。
可以发现,db接收到的流量(21.0M)远大于cache的流量(298K)。
往客户端发送流量大致为:总发送量 3.21M - (db发送量1.59M+cache发送量189k) = 1.44M,而接收的数据量则高达22M,1.44/22=6.5%,也就是仅有6.5%的数据被利用起来了,这个利用率还真是低的可怕。
那么,什么原因导致这样的结果呢?来看一个查询量较大的页面的压测数据:
```bash
ab -c 7 -n 1000 -H https://xxxx.com/call/user/lists?leadin_id=1533534509
...
Concurrency Level: 7
Time taken for tests: 61.964 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 251424000 bytes
HTML transferred: 251108000 bytes
Requests per second: 16.14 [#/sec] (mean)
Time per request: 433.745 [ms] (mean)
Time per request: 61.964 [ms] (mean, across all concurrent requests)
Transfer rate: 3962.51 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 23 40 13.3 36 144
Processing: 236 392 61.0 394 560
Waiting: 163 295 54.8 299 447
Total: 276 432 64.4 434 627
...
```
这是我们能做到的最大的并发数——7,而此时的`iftop`界面已经让人抓狂不已。
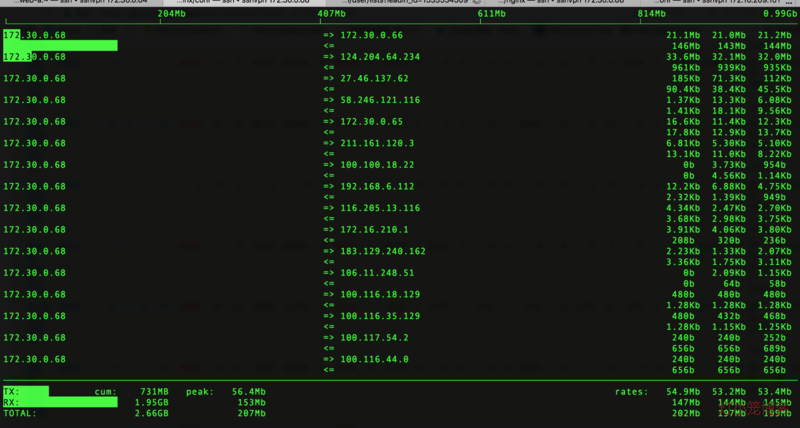
是的,没有看错,mysql数据发送量已经高达145M,1000M带宽已经完全被打满了,想要从mysql接收更多的数据已经不太可能。试想想,如果遇到这样的情况,怎么能不卡顿呢?
## 找出深层原因
问题找到了,接下来就要找原因了,最简单粗暴的办法就是抓包,看看sql执行的具体情况了。
```bash
tcpflow -i eth0 -cp port 3306 > sql.log
```
我们抓取了较长时间的sql,用sublime打开,发现大部分都是这样的场景:

咱们来看看划红线的三块:
- 典型的`select *`问题,没有对真正要查询的数据字段进行过滤。
- 查询条件过于复杂,当然,这和业务的复杂有关系。
- 数据查询量过大,这当然和第1点有直接的关系。
结合到业务的场景,我们最后形成了如下的结论:
1、没有对返回的表字段加以控制,直接select *,导致单次sql查询返回数据量过大。
2、业务逻辑复杂,同一个页面sql查询次数较多,导致通页面总的查询次数以及返回的数据量过大。
3、没有对一些不常变化的数据加上缓存,导致频繁查用同样的数据。
## 对症下药
找对了问题,找准了原因,接下来就是对症下药了。这个反而是水到渠成的事情,比前面的环节要简单地多了。我们做了这些针对性地处理:
- 优化`select *`语句,只返回必要的字段。
- 缓存部分查询结果,因为中间的过程sql省掉了,因此能减少大量的mysql带宽占用。
- 有的页面没有使用查询条件时,不显示结果,必须加上过滤条件,才查询数据,减少数据集的大小。
## 开花结果
经过几天的努力,我们的优化成果很快显现出来了。
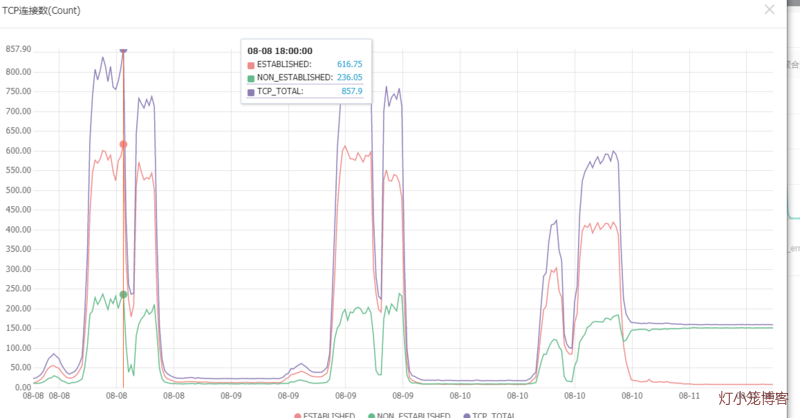
先来看一张mysql服务器的tcp连接图:
再来看一张对应的mysql服务器的流量图:
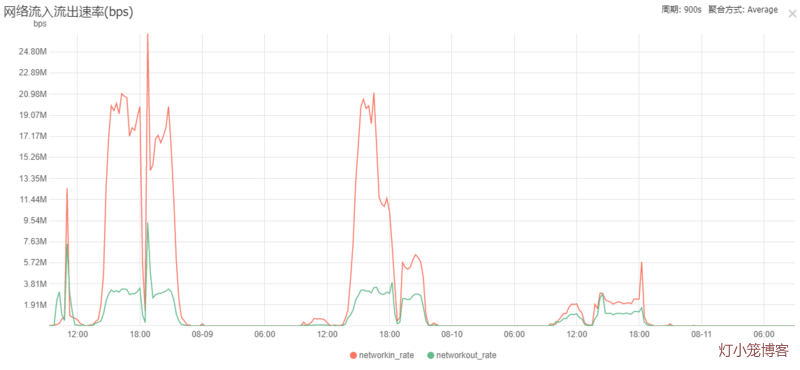
我们的优化上线的时间大概在8月9日下午4点左右,上线后,mysql的流量一泻千里,径直从原来的20多M降低到平均5M左右。
下面来做大致的推算。以流量图的流入速率作为基准,选取连接图的对应时刻点的已经established的连接数作为除数,计算单个established的连接数对应的网卡流入速率。
* 未优化前,以8月8日18:00左右计算:19.83M/620 = 32.75k
* 再以优化后的8月9日19:30左右计算:5.72M/550=10.65k
* 后面继续优化了,以8月10日12:00左右计算:1.91M/305=6.41k
| 时间 | 流入速度(M/s) | 绑定连接数(#/s) | 流入流量(k/#) | 降低 |
|------------|--------------|----------------|-------------|--------|
| 8月8日18:00 |19.83 | 620 | 32.75 | - |
| 8月9日19:30 |5.72 | 550 | 10.65 | 67.5% |
| 8月10日12:00 |1.91 | 305 | 6.41 | 80.4% |
这个80.4%的优化还是来得相当给力的!!!而从实际的效果来看,后面也没有人再因为网站卡顿的问题而抱怨过了。
## 结论
优化首先讲究的是对症下药,找准了方向,结合业务场景分析,剖析对了原因,如何解决问题就是水到渠成的事情了。因此,我们也需要掌握一些更加系统更加基础的分析问题的方法和手段,能帮我们更好地驾驭各种问题,提升解决问题的能力。














 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









