







前言
最近在做专有云输出时遇到了一个棘手的问题,客户需要将我们两年前发布的版本升级到最新版。由于跨度较长,产品代码和数据库 schema 都发生了巨大变化。产品代码部分因为采用了版本管理策略,拥有明确的升级路径,但数据库部分由于未采用代码化方案,导致升级路径缺失,整个升级过程非常艰难。为了让以后的版本升级能顺利进行,需要制定出一套统一的数据库代码化方案。
What we needed to do was to change our mindset of how we treated our database. We had to stop treating it like some special artifact or some unique scenario, and we started looking at it through the same perspective that we were treating our web code.
State based VS Migrations based
State based 和 Migrations based 是来实现数据库代码化的两种常用方法,下面分别进行介绍。
State based
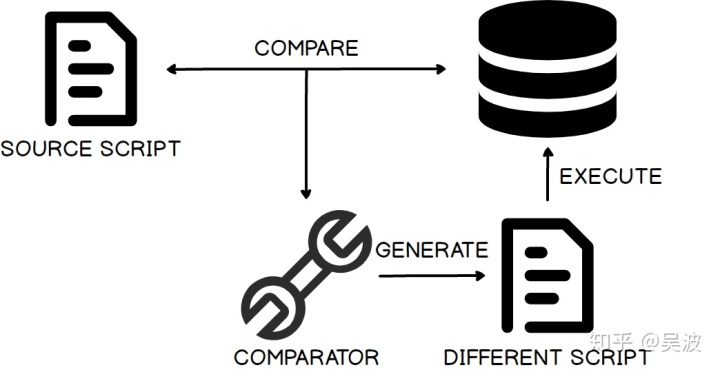
在 state based 模式下,我们仅需要维护数据库的目标状态。每个表、存储过程、视图、触发器都将保存为单独的 SQL 文件,这些文件将是数据库对象状态的真实表示。而升级数据库所需的脚本会由工具自动生成,从而大大减轻维护成本。
但这种模式并不能很好地处理数据迁移场景,例如,将 user 表的 name 列拆分成 first name 和 last name 两个字段。这是因为数据表里的数据往往是上下文相关的,这意味着工具无法对数据进行可靠的假设以生成升级脚本。
Migrations based
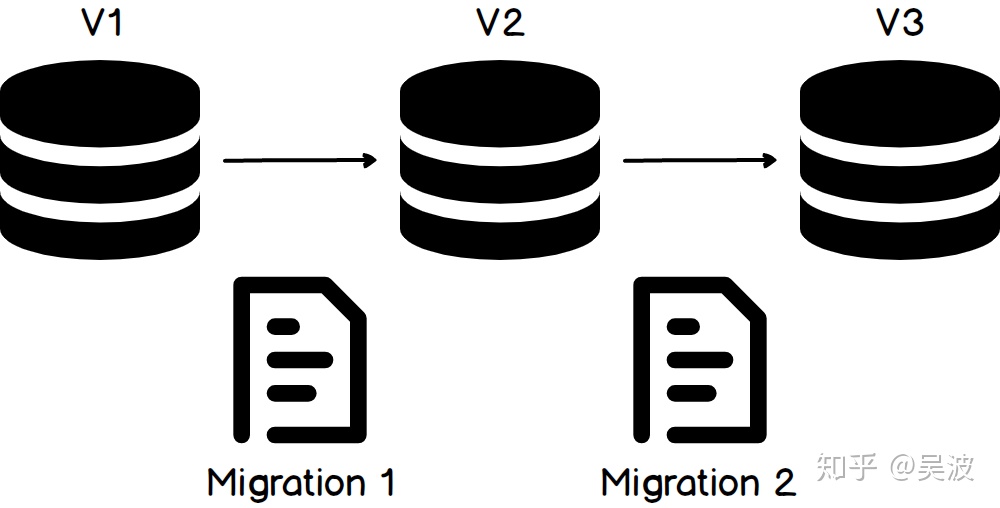
在 migrations based 模式下,我们需要自行维护数据库从一个版本到另一个版本的变更脚本。相比 state based,该模式增加了维护的成本和复杂性,但它能让我们更直接地控制迁移过程,从而能够处理诸如数据迁移这样上下文相关的场景。并且由于变更通过命令式的方式描述,我们可以更早地对其进行评审。实现了 migration based 的代表性工具有 Liquibase、Flyway 等。
Flyway 简介
本章将介绍 migrations based 模式下的代表性工具之一 Flyway,文中使用的版本为6.0.8。
Flyway 是什么
Flyway 是一款开源的数据库迁移工具,它可以方便地帮我们完成数据库的全新部署和增量升级。它有如下功能特点:
1. 可以嵌入到应用程序里或作为单独的工具执行。
2. 追踪已执行的迁移。
3. 执行新的迁移。
4. 验证数据库状态。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









