






三种链表的介绍
原谅我拙劣的绘图能力,花了半天终于还是决定从网上找来了这三张图,因为环形链表的弧形箭头难以完美的展现出来。
以下3张图片来自Wikipedia。



大家看着图片应该也都知道这分别是哪种链表了。那么链表到底是什么呢?
它和前面的栈和队列一般,都是基本的数据结构,其中的各个对象按线性顺序排列。大家应该注意到了图中的大黑点,有些C/C++编程基础的同学肯定能够猜到链表是通过各个对象里的指针来指向下一个对象的,相比,数组则是通过下标来进行索引。
为了让大家加深印象,我们来联系到生活中的实例。
首先是单向链表(singly linked),我第一个联想到的就是下面这种铅笔,满满的儿时回忆呀!找了好久才找到这张图,却不知道它的名字。

然后是双向链表(doublely linked list),动车组则可以很好的诠释它。

循环链表(circular linked list)的应用是比较多的,从小接触的自行车链条就是其中之一。

大家要是还有什么例子欢迎在评论中留下哦。
链表是如何指引的
单链表
前面已经说到了,链表通过指针来指向下一个对象。单链表中有一个关键字key和指针next,当然了,对象中还可以有其他的卫星数据。我们可以这样想象它,前面的图中是一行对吧,然后在行中的链表节点中向下延伸,每个节点都延伸成一列,简单的说,从一维变成了二维(类比二维数组)。
将链表中的一个元素设为x,那么x.key就是它的值,x.next就是链表中的后继元素。如果x.next=NIL,那么就说明没有后继元素了,因此x就是链表的尾(tail)。
双向链表
将单链表升级到双向链表来考虑,无非就是多了一个前驱,用x.prev来表示。同样的,x.prev=NIL,表示没有前驱,那么x就是链表的头(head)。而如果头都为空了,那么整个链表也就是空的了。
循环链表
相应的,循环链表也由双向链表升级而来,就是将链表尾部的元素x的next指向链表的头部y,元素头部的元素y的prev指向链表的尾部x。
链表的搜索、插入、删除
搜索
我们的目的是要搜索出链表L中第一个关键字为k的元素,函数返回的将是指向该元素的指针。
如果不幸的是链表中不存在这个元素,那么就返回NIL。
LIST-SEARCH(L,k)
1 x=L.head
2 while x!=NIL and x.key!=k
3 x=x.next
4 return x由于这个搜索是线性的,在最坏的情况下它会搜索整个链表,因此该情况下LIST-SEARCH的运行时间为Θ(n)。
循环
接下来我们将元素x(已经设置好关键字key)插入到链表中,这个相比搜索就有些复杂,因为它要修改的东西较多一些。L.head.prev的意思是去链表的头节点元素,然后取它的prev属性。
LIST-INSERT(L,x)
1 x.next=L.head
2 if L.head!=NIL
3 L.head.prev=x
4 L.head=x
5 x.prev=NIL它仅仅是在开头插入一个元素而已,因此耗时仅仅是Θ(1)。
删除
我们有了一个指向x的指针,然后要将x从列表中删除掉。具体的思路也非常的简单,例如有依次链接的A、B、C三个节点,如果要将B删除掉,只需要将A的next指向C即可,如果是双线链表也请记得将C的prev指向A。
LIST-DELETE(L,x)
1 if x.prev!=NIL
2 x.prev.next=x.next
3 else L.head=x.next
4 if x.next!=NIL
5 x.next.prev=x.prev由于这里的x已经是指针了,因此删除操作只需要Θ(1)的时间,而如果给定的不是指针而是关键字,那么就要调用LIST-SEARCH先搜索到指针x,这样的话时间就是Θ(n)。
哨兵

今天我忽然觉得在博客上多加点图片,即便是现在这个“哨兵”图像,虽然和链表没太大关系,但也许可以帮助记忆呢,因为记忆真的非常非常重要。
废话不多说,哨兵是什么呢,能够做什么呢?
哨兵节点常常被用在链表和遍历树中,它并不拥有或引用任何被数据结构管理的数据。常常用哨兵节点来代替null,这样的好处有以下3点:
1)增加操作的速度
2)降低算法的复杂性和代码的大小
3)增加数据结构的鲁棒性
补充:鲁棒性(robustness)是指的稳健性或稳定性,也就是说,当某个事物受到干扰时,这个东西的性质依旧稳定。网上有一个例子,在统计中,均值受到极端值的影响可谓非常之大,而在这种情况下中位数就要稳定得多。
补充:还有一个哨兵值的定义(也被称为标志值、信号值和哑值),它是在特定算法中的一个特殊值,常用它来让条件终止,由此可见它被普遍用于循环和递归之中。
简而言之,哨兵就是为了简化边界条件的处理而存在。回头看看链表的删除过程,用了两个if来判断,而用了哨兵值就大可不必这么麻烦。
LIST-DELETE'(L,x)
1 x.prev.next=x.next
2 x.next.prev=x.prev既然是哨兵了,那么它站岗的位置自然也是在边界了,对于链表而言,那就是头部和尾部之间。
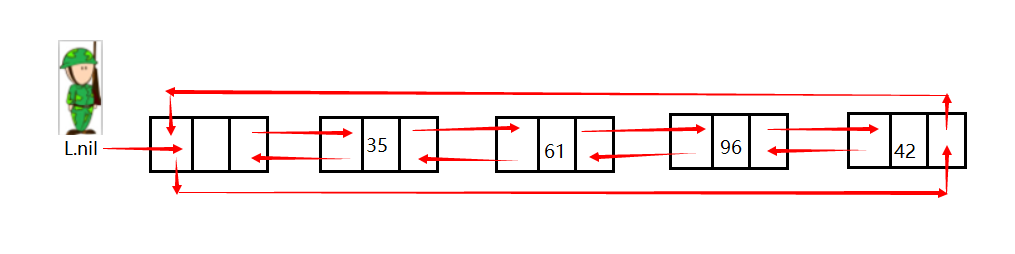
图片上下的3个箭头请大家自行脑补成一个箭头。
在有哨兵之前,我们必须通过L.head来访问表头,现在可以通过L.nil.next来访问表头了。
L.nil就是守卫链表疆土的哨兵,那么L.nil.prev就自然的指向表尾了,相应的L.nil.prev指向表头。
上面已经对删除做了修改,下面也来看看搜索和插入。
搜索
相比删除而言,搜索中原本就对边界的使用不多,此处只需将第一行的L.head换成L.nil.next和将NIL换成L.nil即可。
LIST-SEARCH'(L,k)
1 x=L.nil.next
2 while x!=L.nil and x.key!=k
3 x=x.next
4 return x插入
和删除一样,边界的判断再也不需要了!
LIST-INSERT'(L,x)
1 x.next=L.nil.next
2 L.nil.next.prev=x
3 L.nil.next=x
4 x.prev=L.nil哨兵的作用和注意事项
通过上面有无哨兵的3个操作也可以看出来,哨兵并没有减少算法的渐进时间界,不过可以降低常数因子,例如LIST-DELETE’和LIST-INSERT’都节约了O(1)。当然,在某些情况下,哨兵能够降低的更多。但它更多的作用是在于使代码更加简洁和紧凑。
然而哨兵也需要慎用,正所谓”是药三分毒”,如果存在很多的短小链表,那么再给每一个链表配上一个哨兵就不划算了,因为哨兵要占用额外的存储空间,而短小的年表很多时,就造成了严重的浪费。
那么这篇博客就到此为止咯,最近都在考试,算法系列更新的比较少,不过依旧感谢大家对我的支持!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









