






这个系列包括算法导论学习过程的记录。
最初学习归并算法,对不会使其具体跑在不同的核上报有深深地怨念,刚好算倒重温了这个算法,闲来无事,利用java的thread来体验一下并行归并算法。理论上开的thread会被分配在不同的核上(核没用完的情况下)。当然利用c++来实现更好,这里主要体验一下思路。
=========================================================
- 基本Merge Sort
Merge Sort的具体思路不再详诉,将其包装为MergeSort类.
public class MergeSort {
public static void sort(int[] numbers){
sort(numbers,0,numbers.length);
}
public static void sort(int[] numbers,int pos,int end){
if ((end - pos) > 1) {
int offset = (end + pos) / 2;
sort(numbers, pos, offset);
sort(numbers, offset, end);
merge(numbers, pos, offset, end);
}
}
public static void merge(int[] numbers,int pos,int offset,int end){
int[] array1 = new int[offset - pos];
int[] array2 = new int[end - offset];
System.arraycopy(numbers, pos, array1, 0, array1.length);
System.arraycopy(numbers, offset, array2, 0, array2.length);
for (int i = pos,j=0,k=0; i < end ; i++) {
if (j == array1.length) {
System.arraycopy(array2, k, numbers, i, array2.length - k);
break;
}
if (k == array2.length) {
System.arraycopy(array1, j, numbers, i, array1.length - j);
break;
}
if (array1[j] <= array2[k]) {
numbers[i] = array1[j++];
} else {
numbers[i] = array2[k++];
}
}
}
}
- 并行Merge Sort
并行实现Merge Sort的大体思路为将原来递归拆分其中的一部分换成新开的线程来接管,也就是拆分成一些子串,给不同的核心来处理。
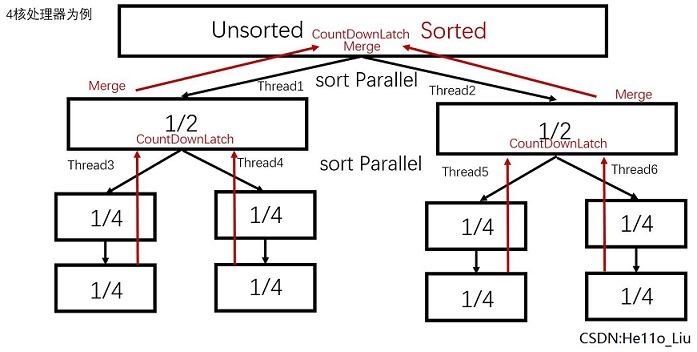
以我的电脑(RMBP Late2013 i5 4258u)为例,其有4个可用核。 递归拆分2次,也就是拆分成4个子串。然后分别在四个核上利用Merge sort对这些子串进行排序。完成后利用同步工具CountDownLatch来提示完成任务,父进程Merge两个已经排好的子串。
示意图如下:
将其包装为MergeParallelSort类如下:
import java.util.Random;
import java.util.concurrent.CountDownLatch;
public class MergeParallelSort {
// 最大可并行深度,为log处理器数
private static final int maxParallelDepth = (int) (Math.log(Runtime.getRuntime().availableProcessors())
/ Math.log(2));
public static void sort(int[] numbers) {
sort(numbers, 0, numbers.length, maxParallelDepth);
}
public static void sort(int[] numbers , int parallelDepth) {
sort(numbers, 0, numbers.length, parallelDepth);
}
public static void sort(int[] numbers, int start, int end) {
sort(numbers, start, end, maxParallelDepth);
}
public static void sort(int[] numbers, int start, int end, int parallelDepth) {
sortParallel(numbers, start, end, parallelDepth > maxParallelDepth ? maxParallelDepth : parallelDepth, 1);
}
/**
* Do Merge Sort in parallel way
*
* @param numbers
* @param start
* @param end
* @param parallelDepth 当前并行深度
* @param depth 当前拆分深度
*/
public static void sortParallel(final int[] numbers, final int start, final int end, final int parallelDepth,
final int depth) {
if ((end - start) > 1) {
//同步工具,等待其两个子线程完成任务后归并
final CountDownLatch mergeSignal = new CountDownLatch(2);
final int offset = (end + start) / 2;
new SortThread(depth, parallelDepth, numbers, mergeSignal, start, offset).start();
new SortThread(depth, parallelDepth, numbers, mergeSignal, offset, end).start();
//等待两个子线程完成其工作
try {
mergeSignal.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
MergeSort.merge(numbers, start, offset, end);
}
}
static class SortThread extends Thread {
private int depth;
private int parallelDepth;
private int[] numbers;
private CountDownLatch mergeSignal;
private int start;
private int end;
/**
* @param depth
* @param parallelDepth
* @param numbers
* @param mergeSignal
* @param start
* @param end
*/
public SortThread(int depth, int parallelDepth, int[] numbers, CountDownLatch mergeSignal, int start, int end) {
super();
this.depth = depth;
this.parallelDepth = parallelDepth;
this.numbers = numbers;
this.mergeSignal = mergeSignal;
this.start = start;
this.end = end;
}
@Override
public void run() {
if (depth < parallelDepth) {
sortParallel(numbers, start, end, parallelDepth, (depth + 1));
} else {
MergeSort.sort(numbers, start, end);
}
mergeSignal.countDown();
}
}
public static void main(String[] args) {
System.out.println("Parallel Merge Sort test");
System.out.println("Processor number:" + Runtime.getRuntime().availableProcessors());
System.out.println("Array Size:10000000");
long time_start, time_end;
long time_para, time_single;
int array[] = new int[10000000];
int array1[] = new int[10000000];
int array2[] = new int[10000000];
Random random = new Random();
for (int i = 0; i < 1000; i++) {
array[i] = random.nextInt(1000000);
}
System.arraycopy(array, 0, array1, 0, array1.length);
System.arraycopy(array, 0, array2, 0, array2.length);
// parallelSort
time_start = System.currentTimeMillis();
MergeParallelSort.sort(array1);
time_end = System.currentTimeMillis();
time_para = time_end - time_start;
// orginalSort
time_start = System.currentTimeMillis();
MergeSort.sort(array2);
time_end = System.currentTimeMillis();
time_single = time_end - time_start;
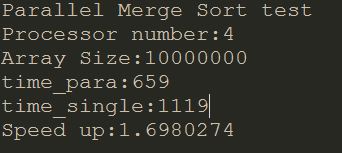
System.out.println("time_para:" + time_para);
System.out.println("time_single:" + time_single);
System.out.println("Speed up:"+(float)time_single/time_para);
}
}
- 输出示例&总结
尝试过数组大小的几组例子,当输入规模过小(size小于100000),并行化效率会低于直接单核处理,可能是开Thread以及等待其他Thread完成导致。当输入规模大起来,加速比也并非理想的4倍。本身基于JVM写并行化并没有明确地将线程分配到具体的核心,待以后有机会研究,此次只是当作并行化初体验罢。















 7220
7220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









