







什么是Kafka
- Kafka是一款分布式消息发布和订阅系统,
- 具有高性能、高吞吐量的特点
- 而被广泛应用与大数据传输场景。
- 它是由LinkedIn公司开发,
- 使用Scala语言编写,
- 之后成为Apache基金会的一个顶级项目。
- kafka提供了类似JMS的特性,
- 但是在设计和实现上是完全不同的,
- 而且他也不是JMS规范的实现。
kafka产生背景:
- kafka作为一个消息系统,
- 早起设计的目的是用作
- LinkedIn的活动流(Activity Stream)
- 和运营数据处理管道(Pipeline)。
- 活动流数据
- 是所有的网站对用户的使用情况做分析的时候要用到的最常规的部分,
- 活动数据包括
- 页面的访问量(PV)、
- 被查看内容方面的信息
- 以及搜索内容。
- 这种数据通常的处理方式是
- 先把各种活动以日志的形式写入某种文件,
- 然后周期性的对这些文件进行统计分析。
- 运营数据指的是
- 服务器的性能数据(CPU、IO使用率、请求时间、服务日志等)。
- 早起设计的目的是用作
Kafka 的应用场景
- 由于kafka具有更好的
- 吞吐量、
- 内置分区、
- 冗余
- 及容错性的优点(kafka每秒可以处理几十万消息),
- 让kafka成为了一个很好的大规模消息处理应用的解决方案。
- 所以在企业级应用长,
- 主要会应用于如下几个方面:
Ø 行为跟踪:
- kafka可以用于跟踪用户浏览页面、搜索及其他行为。
- 通过发布-订阅模式实时记录到对应的topic中,
- 通过后端大数据平台接入处理分析,
- 并做更进一步的实时处理和监控
Ø 日志收集:
- Kafka常用作日志聚合:
- 从各个服务器收集日志存储到一个集中的平台进行处理
- 很多公司的套路是:把日志集中到Kafka ,然后分发到es和 hdfs
- 做日志实时检索和离线统计数据备份
- ELKK 框架
- Kafka也提供 api 来做日志日志收集
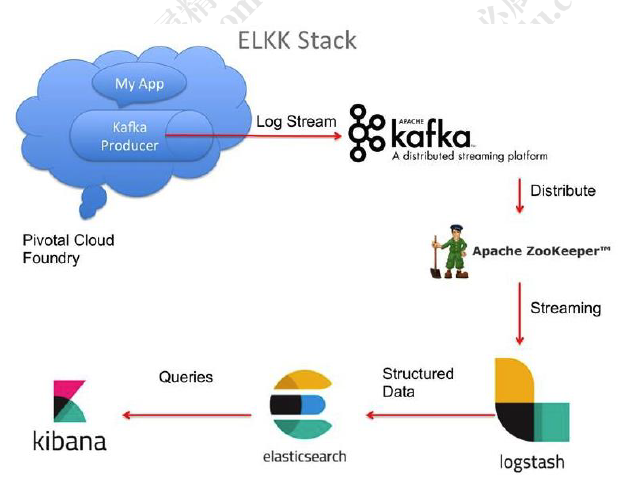
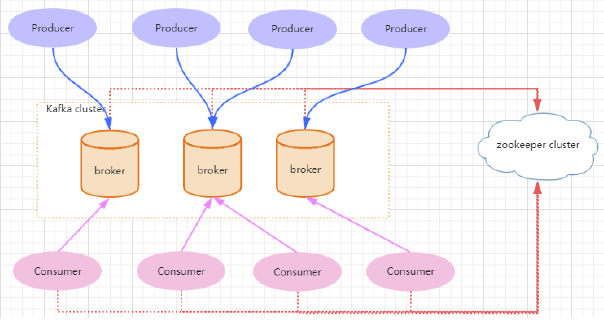
Kafka 本身的架构
- Kafka 通过 ZooKeeper 集群配置和服务协同
- producer 通过push 发送消息到 broker
- consumer pull 消息
- 多个 broker 协同工作
- producer 和 consumer 部署在各个业务逻辑中
- 三者通过ZooKeeper 管理协调请求和转发
- 这样就组成了一个高性能的分布式消息订阅系统















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









