






I'm currently faced with the problem of finding a way to cluster around 500,000 latitude/longitude pairs in python. So far I've tried computing a distance matrix with numpy (to pass into the scikit-learn DBSCAN) but with such a large input it quickly spits out a Memory Error.
The points are stored in tuples containing the latitude, longitude, and the data value at that point.
In short, what is the most efficient way to spatially cluster a large number of latitude/longitude pairs in python? For this application, I'm willing to sacrifice some accuracy in the name of speed.
Edit:
The number of clusters for the algorithm to find is unknown ahead of time.
解决方案
I don't have your data so I just generated 500k random numbers into three columns.
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.vq import kmeans2, whiten
arr = np.random.randn(500000*3).reshape((500000, 3))
x, y = kmeans2(whiten(arr), 7, iter = 20) #
plt.scatter(arr[:,0], arr[:,1], c=y, alpha=0.33333);
out[1]:
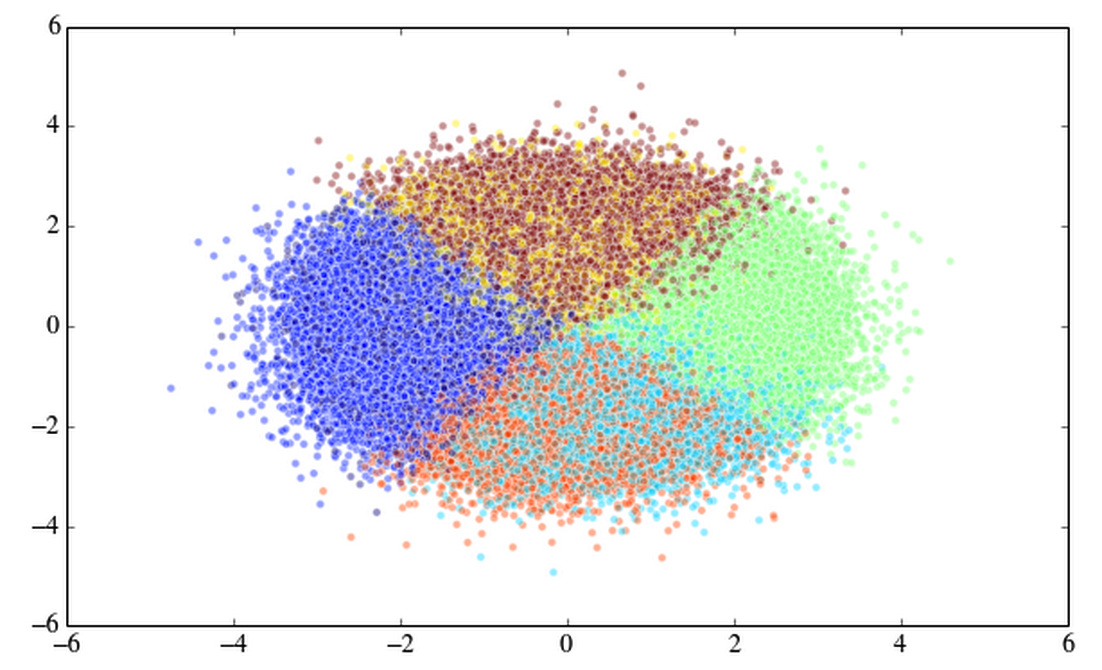
I timed this and it took 1.96 seconds to run this Kmeans2 so I don't think it has to do with the size of your data. Put your data in a 500000 x 3 numpy array and try kmeans2.















 6206
6206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









