






目录
全虚拟化
不需要对GuestOS操作系统软件的源代码做任何的修改,就可以运行在这样的VMM中
在全虚拟化的虚拟平台中,GuestOS并不知道自己是一台虚拟机,它会认为自己就是运行在计算机物理硬件设备上的HostOS。因为全虚拟化的VMM会将一个OS所能够操作的CPU、内存、外设等物理设备逻辑抽象成为虚拟CPU、虚拟内存、虚拟外设等虚拟设备后,再交由GuestOS来操作使用。这样的GuestOS会将底层硬件平台视为自己所有的,但是实际上,这些都是VMM为GuestOS制造了这种假象。
全虚拟化又分为:软件辅助的全虚拟化 & 硬件辅助的全虚拟化。
软件辅助的全虚拟化
软件辅助全虚拟化架构图:
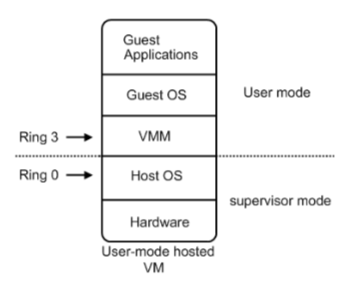
在Intel等CPU厂商还没有发布x86 CPU虚拟化技术之前,完全虚拟化都是通过软件辅助的方式来实现的。而软件辅助的全虚拟化主要是应用了两种机制:
1. 特权解除(优先级压缩):从上述的软件辅助全虚拟化架构图中可以看出,VMM、GuestOS、GuestApplications都是运行在Ring 1-3用户态中的应用程序代码。当在GuestOS中执行系统内核的特权指令时,一般都会触发异常。这是因为用户态代码不能直接运行在核心态中,而且系统内核的特权指令大多都只能运行在Ring 0核心态中。在触发了异常之后,这些异常就会被VMM捕获,再由VMM将这些特权指令进行虚拟化成为只针对虚拟CPU起作用的虚拟特权指令。其本质就是使用若干能运行在用户态中的非特权指令来模拟出只针对GuestOS有效的虚拟特权指令,从而将特权指令的特权解除掉。
缺点:但是特权解除的问题在于当初设计标准x86架构CPU时,并没有考虑到要支持虚拟化技术,所以会存在一部分特权指令运行在Ring 1用户态上,而这些运行在Ring 1上的特权指令并不会触发异常然后再被VMM捕获。从而导致在GuestOS中执行的特权指令直接对HostOS造成了影响(GuestOS和HostOS没能做到完全隔离)。
针对这个问题,再引入了陷入模拟的机制。
陷入模拟(二进制翻译):就是VMM会对GuestOS中的二进制代码(运行在CPU中的代码)进行扫描,一旦发现GuestOS执行的二进制代码中包含有运行在用户态上的特权指令二进制代码时,就会将这些二进制代码翻译成虚拟特权指令二进制代码或者是翻译成运行在核心态中的特权指令二进制代码从而强制的触发异常。这样就能够很好的解决了运行在Ring 1用户态上的特权指令没有被VMM捕获的问题,更好的实现了GuestOS和HostOS的隔离。
简而言之,软件辅助虚拟化能够成功的将所有在GuestOS中执行的系统内核特权指令进行捕获、翻译,使之成为只能对GuestOS生效的虚拟特权指令。但是退一步来说,之所以需要这么做的前提是因为CPU并不能准确的去判断一个特权指令到底是由GuestOS发出的还是由HostOS发出的,这样也就无法针对一个正确的OS去将这一个特权指令执行。
直到后来CPU厂商们发布了能够判断特权指令归属的标准x86 CPU之后,迎来了硬件辅助全虚拟化。
硬件辅助的全虚拟化
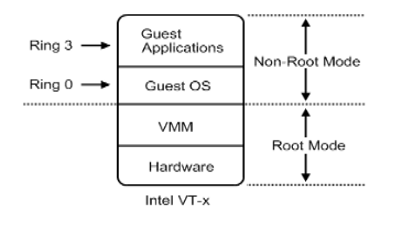
硬件辅助全虚拟化主要使用了支持虚拟化功能的CPU进行支撑,CPU可以明确的分辨出来自GuestOS的特权指令,并针对GuestOS进行特权操作,而不会影响到HostOS。
从更深入的层次来说,虚拟化CPU形成了新的CPU执行状态 —— * Non-Root Mode& Root Mode* 。从上图中可以看见,GuestOS运行在Non-Root Mode 的Ring 0核心态中,这表明GuestOS能够直接执行特却指令而不再需要 特权解除 和 陷入模拟 机制。并且在硬件层上面紧接的就是虚拟化层的VMM,而不需要HostOS。这是因为在硬件辅助全虚拟化的VMM会以一种更具协作性的方式来实现虚拟化 —— 将虚拟化模块加载到HostOS的内核中,例如:KVM,KVM通过在HostOS内核中加载KVM Kernel Module来将HostOS转换成为一个VMM。所以此时VMM可以看作是HostOS,反之亦然。这种虚拟化方式创建的GuestOS知道自己是正在虚拟化模式中运行的GuestOS,KVM就是这样的一种虚拟化实现解决方案。
半虚拟化
需要对GuestOS的内核代码做一定的修改,才能够将GuestOS运行在半虚拟化的VMM中。
半虚拟化通过在GuestOS的源代码级别上修改特权指令来回避上述的虚拟化漏洞。
修改内核后的GuestOS也知道自己就是一台虚拟机。所以能够很好的对核心态指令和敏感指令进行识别和处理,但缺点在于GuestOS的镜像文件并不通用。
具体的x86架构CPU解析,请参考虚拟化的发展历程和实现方式















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









