






自定义损失函数:根据问题的实际情况,定制合理的损失函数。
例如:
对于预测酸奶日销量问题,如果预测销量大于实际销量则会损失成本;如果预测销量小于实际销量则会损失利润。在实际生活中,往往制造一盒酸奶的成本和销售一盒酸奶的利润是不等价的。因此,需要使用符合该问题的自定义损失函数。
自定义损失函数为:loss = ∑??(y_,y)
其中,损失定义成分段函数: 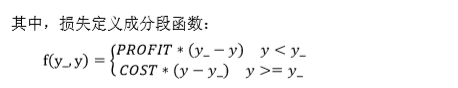
损失函数表示,若预测结果 y 小于标准答案 y_,损失函数为利润乘以预测结果 y 与标准答案 y_之差;
若预测结果 y 大于标准答案 y_,损失函数为成本乘以预测结果 y 与标准答案 y_之差。
用 Tensorflow 函数表示为: loss = tf.reduce_sum(tf.where(tf.greater(y,y_),COST(y-y_),PROFIT(y_-y)))
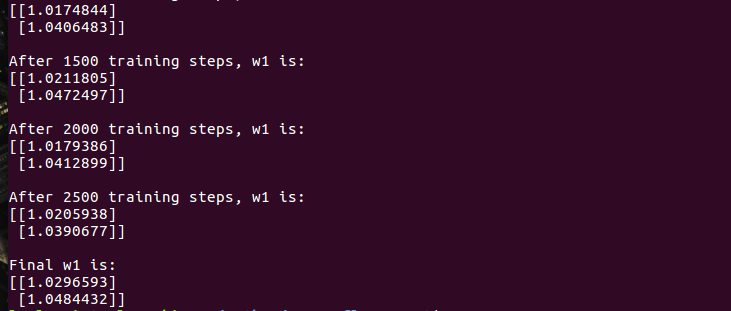
① 若酸奶成本为 1 元,酸奶销售利润为 9 元,则制造成本小于酸奶利润,因此希望预测的结果 y 多一些。采用上述的自定义损失函数,训练神经网络模型
y=w1*x1+w2*x2;若成本低于利润,则应该y稍稍大于标准值。
标准值是:y_=x1+x2;
代码:
#coding:utf-8 #tensorflow学习笔记(北京大学) #酸奶成本1元, 酸奶利润9元 #预测少了损失大,故不要预测少,故生成的模型会多预测一些 #0导入模块,生成数据集 import tensorflow as tf import numpy as np BATCH_SIZE = 8 SEED = 23455#随机种子 COST = 1#花费 PROFIT = 9#成本 rdm = np.random.RandomState(SEED)#基于seed产生随机数 X = rdm.rand(32,2)#随机数返回32行2列的矩阵 表示32组 体积和重量 作为输入数据集 Y = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] #1定义神经网络的输入、参数和输出,定义前向传播过程。 x = tf.placeholder(tf.float32, shape=(None, 2))#占位 y_ = tf.placeholder(tf.float32, shape=(None, 1))#占位 w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))#正态分布 y = tf.matmul(x, w1)#点积 #2定义损失函数及反向传播方法。 # 定义损失函数使得预测少了的损失大,于是模型应该偏向多的方向预测。 #tf.where:如果condition对应位置值为True那么返回Tensor对应位置为x的值,否则为y的值. #where(condition, x=None, y=None,name=None) loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_)*COST, (y_ - y)*PROFIT)) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)#随机梯度下降 #3生成会话,训练STEPS轮。 with tf.Session() as sess: init_op = tf.global_variables_initializer()#初始化 sess.run(init_op)#初始化 STEPS = 3000 for i in range(STEPS):#三千轮 start = (i*BATCH_SIZE) % 32 #8个数据 为一个数据块输出 end = (i*BATCH_SIZE) % 32 + BATCH_SIZE #[i:i+8] sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})#训练 if i % 500 == 0:#每500轮打印输出 print "After %d training steps, w1 is: " % (i)#打印i print sess.run(w1), "\n"#打印w1 print "Final w1 is: \n", sess.run(w1)#最终打印w1
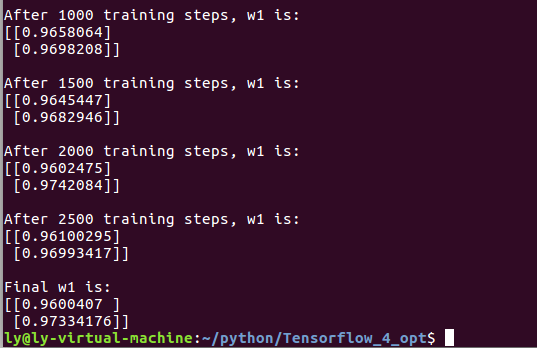
②若酸奶成本为 9 元,酸奶销售利润为 1 元,则制造成本大于酸奶利润,因此希望预测结果 y 小一些。采用上述的自定义损失函数,训练神经网络模型。
同理,成本大于利润,则希望y相对小一些
代码:
#coding:utf-8 #酸奶成本9元, 酸奶利润1元 #预测多了损失大,故不要预测多,故生成的模型会少预测一些 #0导入模块,生成数据集 import tensorflow as tf import numpy as np BATCH_SIZE = 8 SEED = 23455 COST = 9 PROFIT = 1 rdm = np.random.RandomState(SEED) X = rdm.rand(32,2) Y = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] #1定义神经网络的输入、参数和输出,定义前向传播过程。 x = tf.placeholder(tf.float32, shape=(None, 2)) y_ = tf.placeholder(tf.float32, shape=(None, 1)) w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1)) y = tf.matmul(x, w1) #2定义损失函数及反向传播方法。 #重新定义损失函数,使得预测多了的损失大,于是模型应该偏向少的方向预测。 loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_)*COST, (y_ - y)*PROFIT)) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss) #3生成会话,训练STEPS轮。 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 3000 for i in range(STEPS): start = (i*BATCH_SIZE) % 32 end = (i*BATCH_SIZE) % 32 + BATCH_SIZE sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 500 == 0: print "After %d training steps, w1 is: " % (i) print sess.run(w1), "\n" print "Final w1 is: \n", sess.run(w1)















 7764
7764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









