







背景:
spring cloud的重试机制是指:负载均衡客户端Ribbon发现远程请求实例不可到达之后,去重试其他实例的过程。
菜鸟对账项目基于spring cloud架构,由于导入的文件过于庞大(当时开启4个线程导入130MB的数据大约需要20分钟),在feign调用的过程中出现超时,因此触发重试机制。
下面是feign重试机制的内部代码,可见feign默认是通过自己包下的Retryer进行重试配置,超时时间为1秒,默认为5次:
package feign;
import static java.util.concurrent.TimeUnit.SECONDS;
/**
* Cloned for each invocation to {@link Client#execute(Request, feign.Request.Options)}.
* Implementations may keep state to determine if retry operations should continue or not.
*/
public interface Retryer extends Cloneable {
/**
* if retry is permitted, return (possibly after sleeping). Otherwise propagate the exception.
*/
void continueOrPropagate(RetryableException e);
Retryer clone();
public static class Default implements Retryer {
private final int maxAttempts;
private final long period;
private final long maxPeriod;
int attempt;
long sleptForMillis;
public Default() {
this(100, SECONDS.toMillis(1), 5);
}
public Default(long period, long maxPeriod, int maxAttempts) {
this.period = period;
this.maxPeriod = maxPeriod;
this.maxAttempts = maxAttempts;
this.attempt = 1;
}
}
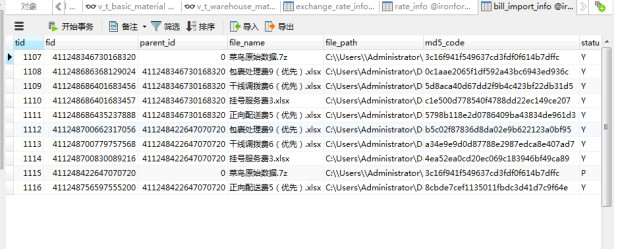
}导入文件的时候触发重试,导致的结果是:导入的请求触发两次,导入两份相同文件进数据库:

尝试解决:
博主尝试过以下方法,然而问题都没有得到解决:
方法一:延长hystrix超时时间(hystrix默认超时为1秒)
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 100000000方法二:禁用hystrix超时
hystrix:
command:
default:
execution:
timeout:
enabled: false方法三:关闭重试机制开关
spring:
cloud:
loadbalancer:
retry:
enabled: false方法四:不对所有操作都重试和不允许Ribbon去重试其他实例
ribbon:
OkToRetryOnAllOperations: false
MaxAutoRetriesNextServer: 0方法五:feign取消重试
@Bean
Retryer feignRetryer() {
return Retryer.NEVER_RETRY;
}方法六:feign异步调用
@HystrixCommand(observableExecutionMode=ObservableExecutionMode.EAGER)
public Observable<String> postAccountObserve(){
return Observable.create(new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> sub) {
String url = client.getInstances("account").get(0).getUri().toString()+"account";
String result = temp.getForObject(url, String.class);
sub.onNext(result);
sub.onCompleted();
}
});
}
最终解决方法:
最终,博主在张建斌博客中找到解决方法:feign请求超时设置,延长Ribbon超时时间。这里主要是延长Ribbon读取超时时间(ReadTimeout):
@Bean
Request.Options requestOptions(ConfigurableEnvironment env){
int ribbonReadTimeout = env.getProperty("ribbon.ReadTimeout", int.class, 1000000000);
int ribbonConnectionTimeout = env.getProperty("ribbon.ConnectTimeout", int.class, 500000000);
return new Request.Options(ribbonConnectionTimeout, ribbonReadTimeout);
}问题引入:延长超时终究不是最佳解决方案,如果文件数据量达到几千万甚至更多,则请求时间可能超过1000000000毫秒,依然会出现重试的问题,该怎么解决?
后期博主将尝试开启多线程,并用分布式锁来避免多次触发调用。
参考链接:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









