







在 Lua 和 Python 等脚本语言中,经常提到一个概念: 协程。也经常会有同学对协程的概念及其作用比较疑惑,本文今天就来探讨下协程的前世今生。
0、首先回答两个大家最关心的问题:
0.1 什么是协程?
本质上协程就是用户空间下的线程。
0.2 协程的好处是什么?
通俗易懂的回答:
-
让原来要使用 异步 + 回调 方式写的非人类代码,可以用看似同步的方式写出来。
-
无需线程上下文切换、原子操作锁定及同步的开销。
先回顾下传统的 Java 生产者消费者模型:
import java.util.LinkedList;
class Mytask implements Runnable {// 任务接口
public void run() {
String name = Thread.currentThread().getName();
try {
Thread.sleep(100);// 模拟任务执行的时间
} catch (InterruptedException e) {
}
System.out.println(name + " executed OK");
}
}
public class WorkQueue {
private final int nThreads;// 线程池的大小
private final PoolWorker[] threads;// 用数组实现线程池
private final LinkedList queue;// 任务队列
private class PoolWorker extends Thread {// 工作线程类
public void run() {
Runnable r;
while (true) {
synchronized (queue) {
while (queue.isEmpty()) {// 如果任务队列中没有任务,等待
try {
queue.wait();
} catch (InterruptedException ignored) {
}
}
r = (Runnable) queue.removeFirst();// 有任务时,取出任务
}
try {
r.run();// 执行任务
} catch (RuntimeException e) {
// You might want to log something here
}
}
}
}
public WorkQueue(int nThreads) {
this.nThreads = nThreads;
queue = new LinkedList();
threads = new PoolWorker[nThreads];
for (int i = 0; i < nThreads; i++) {
threads[i] = new PoolWorker();
threads[i].start();// 启动所有工作线程
}
}
public void execute(Runnable r) {// 执行任务
synchronized (queue) {
queue.addLast(r);
queue.notify();
}
}
public static void main(String args[]) {
WorkQueue wq = new WorkQueue(10);// 10个工作线程
Mytask r[] = new Mytask[20];// 20个任务
for (int i = 0; i < 20; i++) {
r[i] = new Mytask();
wq.execute(r[i]);
}
}
}
1、回顾同步与异步编程
同步编程即线性化编程,代码按照既定顺序执行,上一条语句执行完才会执行下一条,否则就一直等在那里。
但是许多实际操作都是CPU 密集型任务和 IO 密集型任务,比如网络请求,此时不能让这些任务阻塞主线程的工作,于是就会采用异步编程。
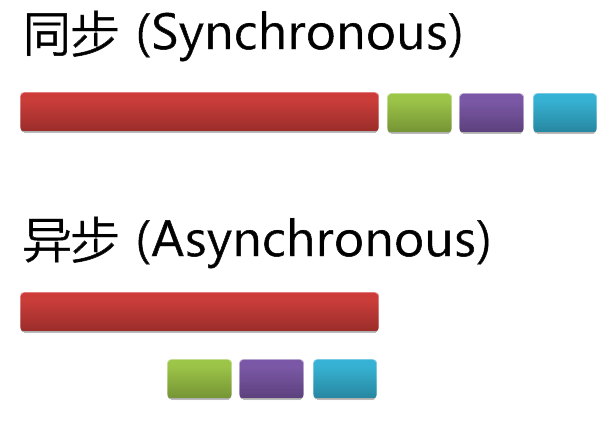
异步的标准元素就是回调函数(Callback, 后来衍生出Promise/Deferred概念),主线程发起一个异步任务,让其自己到一边去工作,当其完成后,会通过执行预先指定的回调函数完成后续任务,然后返回主线程。在异步任务执行过程中,主线程无需等待和阻塞,可以继续处理其他任务。
下例大家并不陌生,是jQuery标准发送http异步请求的方式。
$.ajax({
url:"/echo/json/",
success: function(response)
{
console.info(response.name);
}
});而并发的核心思想在于,大的任务可以分解成一系列的子任务,后者可以被调度成 同时执行或异步执行,而不是一次一个地或者同步地执行。两个子任务之间的 切换也就是上下文切换。
2、回顾多线程编程
当主线程发起异步任务,这个任务跑到哪里去工作了呢?这就说到多线程(包括多进程)编程,一个主线程可以主动创建多个子线程,然后将任务交给子线程,每个子线程拥有自己的堆栈空间。操作系统可以通过分时的方式让同一个CPU轮流调度各个线程,编程人员无需关心操作系统是如何工作的。
但是如果需要在多个线程之间通信,则需要编程人员自己写代码来控制线程之间的协作(利用锁或信号量)以及通信(利用管道、队列等)。
2.1 经典的Producer-Consumer问题

这个问题说的是有两方进行通信和协作,一方只负责生产内容,另一方只负责消费内容。消费者并不知道,也无需知道生产者何时生产,只是当有内容生产出来负责消费即可,没有内容时就等待。这是一个经典的异步问题。
2.1.1 Threading/Queue方案
传统的解决方案即是采用多线程来实现,生产者和消费者分别处于不同的线程或进程中,由操作系统进行调度。来看一篇经典的多线程教程中的例子,是不是很像Java风格?——啰嗦。
import threading
import time
import logging
import random
import Queue
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-9s) %(message)s',)
BUF_SIZE = 10
q = Queue.Queue(BUF_SIZE)
class ProducerThread(threading.Thread):
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, verbose=None):
super(ProducerThread,self).__init__()
self.target = target
self.name = name
def run(self):
while True:
if not q.full():
item = random.randint(1,10)
q.put(item)
logging.debug('Putting ' + str(item)
+ ' : ' + str(q.qsize()) + ' items in queue')
time.sleep(random.random())
return
class ConsumerThread(threading.Thread):
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, verbose=None):
super(ConsumerThread,self).__init__()
self.target = target
self.name = name
return
def run(self):
while True:
if not q.empty():
item = q.get()
logging.debug('Getting ' + str(item)
+ ' : ' + str(q.qsize()) + ' items in queue')
time.sleep(random.random())
return
if __name__ == '__main__':
p = ProducerThread(name='producer')
c = ConsumerThread(name='consumer')
p.start()
time.sleep(2)
c.start()
time.sleep(2)2.1.2 MessageQueue方案
基于多线程方案,这个问题已经演变成消息中介模式(有些公司喜欢称之为”邮局”),有各种的商业MQ方案可以直接使用。
这里以RabbitMQ开源方案为例,Producer一方向名为队列中发送”Hello World!”内容,而Consumer一方则监听队列,当有内容进入队列时,就执行callback函数来收取并处理内容。发送与收取的动作是异步执行的,互不干扰。
###### Producer ########
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print " [x] Sent 'Hello World!'"
connection.close()
####### Consumer ########
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
channel.start_consuming()3、yield与协程
3.1 何为协程(Coroutine)及yield
python采用了GIL(Global Interpretor Lock,全局解释器锁),默认所有任务都是在同一进程中执行的。(当然,可以借助多进程多线程来实现并行化。)我们调用一个普通的Python函数时,一般是从函数的第一行代码开始执行,结束于return语句、异常或者函数结束(可以看作隐式的返回None)。一旦函数将控制权交还给调用者,就意味着全部结束。函数中做的所有工作以及保存在局部变量中的数据都将丢失。再次调用这个函数时,一切都将从头创建。
实现一个用户态线程有两个必须要处理的问题:一是碰着阻塞式 I/O 会导致整个进程被挂起;二是由于缺乏时钟阻塞,进程需要自己拥有调度线程的能力。如果一种实现使得每个线程需要自己通过调用某个方法,主动交出控制权。那么我们就称这种用户态线程是协作式的,即是协程。
本质上协程就是用户空间下的线程。
在 Python 中,所谓协程(Coroutine)就是在同一进程/线程中,利用生成器(generator)来”同时”执行多个函数(routine)。
Python的中yield关键字与Coroutine说的是一件事情,先看看yield的基本用法。
任何包含yield关键字的函数都会自动成为生成器(generator)对象,里面的代码一般是一个有限或无限循环结构,每当第一次调用该函数时,会执行到yield代码为止并返回本次迭代结果,yield指令起到的是return关键字的作用。然后函数的堆栈会自动冻结(freeze)在这一行。当函数调用者的下一次利用next()或generator.send()或for-in来再次调用该函数时,就会从yield代码的下一行开始,继续执行,再返回下一次迭代结果。通过这种方式,迭代器可以实现无限序列和惰性求值。
看一个用生成器来计算100以内斐波那契数列的例子。我们先用普通递归方式来进行计算。
a = b = 1
while a < 100:
a, b = b, a + b
print a,再来用yield和生成器来计算斐波那契数列,该函数形成一个无限循环的生成器,由函数调用者显式地控制迭代次数。
#!/usr/bin/env python
# coding=utf-8
# 测试utf-8编码
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def fibonacci():
a = b = 1
# yield则像是generator函数的返回结果
yield a
yield b
while True:
a, b = b, a+b
# yield唯一所做的另一件事就是保存一个generator函数的状态,
# generator就是一个特殊类型的迭代器(iterator)
yield b
num = 0
fib = fibonacci()
while num < 100:
# 和迭代器相似,我们可以通过使用next()来从generator中获取下一个值,也可以通过隐式地调用next()来忽略一些值
num = next(fib)
print num,
# 1 1 2 3 5 8 13 21 34 55 89 144总而言之,生成器(以及yield语句)最初的引入是为了让程序员可以更简单的编写用来产生值的序列的代码。 以前,要实现类似随机数生成器的东西,需要实现一个类或者一个模块,在生成数据的同时保持对每次调用之间状态的跟踪。引入生成器之后,这变得非常简单。
-
yield则像是generator函数的返回结果
-
yield唯一所做的另一件事就是保存一个generator函数的状态
-
generator就是一个特殊类型的迭代器(iterator)
-
和迭代器相似,我们可以通过使用next()来从generator中获取下一个值
-
通过隐式地调用next()来忽略一些值
3.2 用yield实现协程调度的原理
我们现在利用yield关键字会自动冻结函数堆栈的特性,想象一下,假如现在有两个函数f1()和f2(),各自包含yield语句,见下例。主线程先启动f1(), 当f1()执行到yield的时候,暂时返回。这时主线程可以将执行权交给f2(),执行到f2()的yield后,可以再将执行权交给f1(),从而实现了在同一线程中交错执行f1()和f2()。f1()与f2()就是协同执行的程序,故名协程。
我们尝试用yield建立协程,来解决Producer-Consumer问题。
# -*- coding: utf-8 -*-
import random
def get_data():
"""返回0到9之间的3个随机数,模拟异步操作"""
return random.sample(range(10), 3)
def consume():
"""显示每次传入的整数列表的动态平均值"""
running_sum = 0
data_items_seen = 0
while True:
print('Waiting to consume')
data = yield
data_items_seen += len(data)
running_sum += sum(data)
print('Consumed, the running average is {}'.format(running_sum / float(data_items_seen)))
def produce(consumer):
"""产生序列集合,传递给消费函数(consumer)"""
while True:
data = get_data()
print('Produced {}'.format(data))
consumer.send(data)
yield
if __name__ == '__main__':
consumer = consume()
consumer.send(None)
producer = produce(consumer)
for _ in range(10):
print('Producing...')
next(producer)如果你没看明白,那还可以把上面的例子再写的通熟易懂些, 不做任何逻辑处理:
#!/usr/bin/env python
# coding=utf-8
# 测试utf-8编码
import sys, time
reload(sys)
sys.setdefaultencoding('utf-8')
"""
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高。
"""
# 注意到consumer函数是一个generator(生成器):
# 任何包含yield关键字的函数都会自动成为生成器(generator)对象
def consumer():
r = ''
while True:
# 3、consumer通过yield拿到消息,处理,又通过yield把结果传回;
# yield指令具有return关键字的作用。然后函数的堆栈会自动冻结(freeze)在这一行。
# 当函数调用者的下一次利用next()或generator.send()或for-in来再次调用该函数时,
# 就会从yield代码的下一行开始,继续执行,再返回下一次迭代结果。通过这种方式,迭代器可以实现无限序列和惰性求值。
n = yield r
if not n:
return
print('[CONSUMER] ←← Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
# 1、首先调用c.next()启动生成器
c.next()
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] →→ Producing %s...' % n)
# 2、然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
cr = c.send(n)
# 4、produce拿到consumer处理的结果,继续生产下一条消息;
print('[PRODUCER] Consumer return: %s' % cr)
# 5、produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
c.close()
if __name__=='__main__':
# 6、整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
c = consumer()
produce(c)
# 运行结果:
# [PRODUCER] →→ Producing 1...
# [CONSUMER] ←← Consuming 1...
# [PRODUCER] Consumer return: 200 OK
# [PRODUCER] →→ Producing 2...
# [CONSUMER] ←← Consuming 2...
# [PRODUCER] Consumer return: 200 OK
# [PRODUCER] →→ Producing 3...
# [CONSUMER] ←← Consuming 3...
# [PRODUCER] Consumer return: 200 OK
# [PRODUCER] →→ Producing 4...
# [CONSUMER] ←← Consuming 4...
# [PRODUCER] Consumer return: 200 OK
# [PRODUCER] →→ Producing 5...
# [CONSUMER] ←← Consuming 5...
# [PRODUCER] Consumer return: 200 OK下图将控制流形象化,就像在调试器中单步执行整个程序,以说明上下文切换如何发生。

注意:
-
在任何时刻,只有一个协程在运行。
-
协程就是用户态线程(逻辑流是共享一个地址空间的,不用特别麻烦的切换页表、刷新TLB,避免反复系统调用,还有进程切换造成的开销),比内核线程低廉(核心的操作需要陷入内核(kernel),切换到操作系统),切换阻塞成本低; 单调度器下,访问共享资源无需上锁,用于提高cpu单核的并发能力。
以经典的生产者消费者场景为例,细节原理如下:
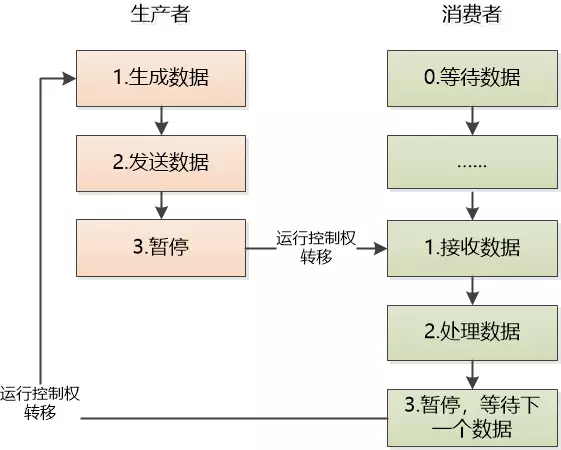
-
生产者发送数据,暂停运行,不进行下一轮循环
-
消费者其实一直在value = yield 那里等待,直到数据到来,现在数据来了,取出处理(value就是生产者发送过来的数据)。
-
消费者在循环中再次yield, 暂停执行。
-
生产者继续下一轮的循环,生成新的消息,发送给消费者。
4、异步编程同步化
4.1 不再需要回调
看一下Python官方的例子,利用一个@gen.coroutine装饰器来简化代码编写,原本调用-回调两段逻辑,现在被放在了一起,yield充当了回调的入口。这就是异步编程同步化!
原始的回调编程模式:
class AsyncHandler(RequestHandler):
@asynchronous
def get(self):
http_client = AsyncHTTPClient()
http_client.fetch("http://example.com",
callback=self.on_fetch)
def on_fetch(self, response):
do_something_with_response(response)
self.render("template.html")同步化编程后的结果:
class GenAsyncHandler(RequestHandler):
@gen.coroutine
def get(self):
http_client = AsyncHTTPClient()
response = yield http_client.fetch("http://example.com")
do_something_with_response(response)
self.render("template.html")关于这个装饰器的实现方式,可以参见 http://my.oschina.net/u/877348/blog/184058
4.2 Gevent 与 Greenlet 库
看了上述代码,你是不是觉得利用协程就可以将并发编程全部同步化了?错!
仔细想想,即使用了协程,同一时间仍然只能有一段代码得到执行,此时如果有同步的I/O任务,则仍会存在阻塞想象。除非…除非将I/O任务自动并发掉,才有可能真正利用协程来将大量异步并发任务同步化!注意这里的http_client是异步网络库,非同步阻塞库。一般是需要回调,但利用协程对get()函数同步化以后,当执行到yield时,相当于发出了多个网络请求,然后挂起这个get()函数,其他协程将得到调度。当异步网络请求都已返回且协程调度有空闲时,会调用get.send(),继续这个协程,以同步化编程的方式继续完成原先放在回调函数中的逻辑。上例中网络请求如果采用普通的urllib.urlopen()就不行了。
慢着,如果urllib.urlopen()能够异步执行,那不就行了?
这就是Greenlet库所做的,它是以C扩展模块形式接入Python的轻量级协程,将一些原本同步运行的网络库以mockey_patch的方式进行了重写。Greenlets全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
而Gevent库则是基于Greenlet,实现了协程调度功能。将多个函数spawn为协程,然后join到一起,如此简单!
看一个Gevent的官方例子:
import gevent.monkey
gevent.monkey.patch_socket()
import gevent
import urllib2
import simplejson as json
def fetch(pid):
response = urllib2.urlopen('http://json-time.appspot.com/time.json')
result = response.read()
json_result = json.loads(result)
datetime = json_result['datetime']
print('Process %s: %s' % (pid, datetime))
return json_result['datetime']
def synchronous():
for i in range(1,10):
fetch(i)
def asynchronous():
threads = []
for i in range(1,10):
threads.append(gevent.spawn(fetch, i))
gevent.joinall(threads)
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()4.3 multiprocessing.dummy.ThreadPool 库
实现异步编程同步化还有一个方法,就是利用的map()函数。这个函数我们并不陌生,它可以在一个序列上实现某个函数之间的映射。
results = map(urllib2.urlopen, ['http://www.yahoo.com', 'http://www.reddit.com'])上述代码对会依次访问每个url,不过因为只有一个进程,后一个urlopen仍然需要等待前一个urlopen完成后才会进行,仍然是一种串行的方式。但是,只要借助正确的库,map()也可以轻松实现并行化操作,那就是multiprocessing库。
这个库以及其鲜为人知的子库multiprocessing.dummy,一个用于多进程,一个用于多线程。后者提供改良的map()函数,可以自动将多个异步任务,分配到多个线程上,编程人员无需关注,也就自然地把异步编程转为了同步编程的风格。IO 密集型任务选择multiprocessing.dummy,CPU 密集型任务选择multiprocessing。
前述那个教科书式的例子,可以改写为:
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [ 'http://www.python.org', 'http://www.python.org/about/', 'http://www.python.org/doc/', 'http://www.python.org/download/']
# Make the Pool of workers
pool = ThreadPool()
# Open the urls in their own threads and return the results
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
print results
pool.close()
pool.join()关于map()函数和yield关键字的解释,请参考 @申导 的另一篇文章《Python函数式编程》
5、Refer:
[1] 利用python yielding创建协程将异步编程同步化
[2] 协程
[3] Python 中的进程、线程、协程、同步、异步、回调
http://segmentfault.com/a/1190000001813992
[4] 淺談coroutine與gevent
http://blog.ez2learn.com/2010/07/17/talk-about-coroutine-and-gevent/
[5] gevent程序员指南
http://xlambda.com/gevent-tutorial/
[6] 协程的好处是什么?
http://www.zhihu.com/question/20511233
[7] python中的协程(yield)内部是怎么实现的?python和lua在yield的实现原理上有什么区别?
http://www.zhihu.com/question/30133749
[8] Python中多继承与super()用法
http://www.jackyshen.com/2015/08/19/multi-inheritance-with-super-in-Python/
[9] Python 并行任务技巧
http://my.oschina.net/leejun2005/blog/194270
[10] Python 3.5正式发布,支持async/await异步编程
http://www.infoq.com/cn/news/2015/09/python-3.5-released
[11] Python Realtime
http://pyzh.readthedocs.org/en/latest/python-realtime.html
[12] Tornado 4.3文档翻译: 用户指南-协程示例-一个并发网络爬虫
http://segmentfault.com/a/1190000004240871
[13] Python并发编程之协程/异步IO
https://segmentfault.com/a/1190000007851357
[14] 从0到1,Python异步编程的演进之路
https://zhuanlan.zhihu.com/p/25228075
[15] 一个故事讲完进程、线程和协程
https://mp.weixin.qq.com/s/zuWRx1FGuBC-_HwuA7jK3w















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









