







1.前言
有时候你会遇到这样的需求,根据数据中的某一个字段进行输出,将相同key的数据输出到一个文件夹下的一个文件中。
2.实现方式
2.1 如何实现
使用saveAsHadoopFile对数据进行输出。
1. 保证同一个Key的数据在同一个分区
2. 自定义MultipleTextOutputFormat类
2.2 代码
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/**
* Created on 16/6/3 13:22
*
* @author Daniel
*/
public class SparkMultipleTextOutput {
public static class RDDMultipleTextOutputFormat extends MultipleTextOutputFormat<String, String> {
public String generateFileNameForKeyValue(String key, String value,
String name) {
//输出格式 /ouput/key/key.csv
return key + "/" + key+".csv";
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Test").setMaster("local[2]");
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
JavaSparkContext sc = new JavaSparkContext(conf);
//加载文件
JavaRDD<String> rdd1 = sc.textFile("/Users/Daniel/test/test_file.csv");
//将data转化为K,V
JavaPairRDD<String,String> rdd2 = rdd1.mapToPair(new PairFunction<String, String, String>() {
public Tuple2<String, String> call(String s) throws Exception {
String[] data = s.split(",");
String key = data[0];
String value = data[1];
return new Tuple2<String, String>(key, value);
}
//这里是关键点,只要保证同一个Key的数据在同一个分区即可
//上边的要求一般有2种方式实现
//第一种 .repartition(1); 测试功能的时候可以使用,现网自己看着办吧.
//第二种 .partitionBy(); 保证同一个key到一个分区.
}).partitionBy(new HashPartitioner(2));
//将JavaPairRDD类型的RDD输出.
rdd2.saveAsHadoopFile("/Users/Daniel/test2", String.class, String.class, RDDMultipleTextOutputFormat.class);
}
}3. 测试
测试数据如下图:
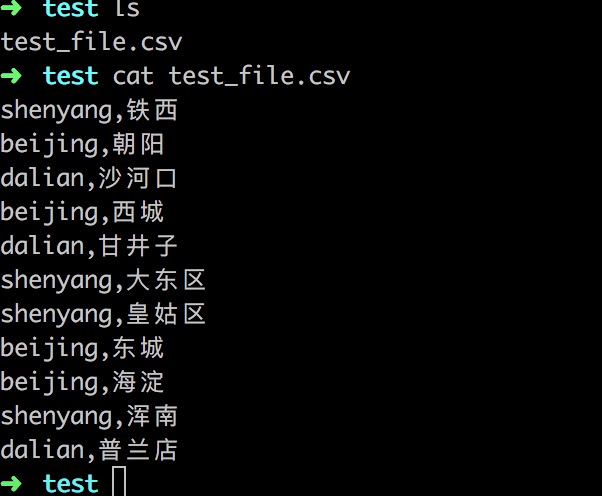
测试结果如下图:
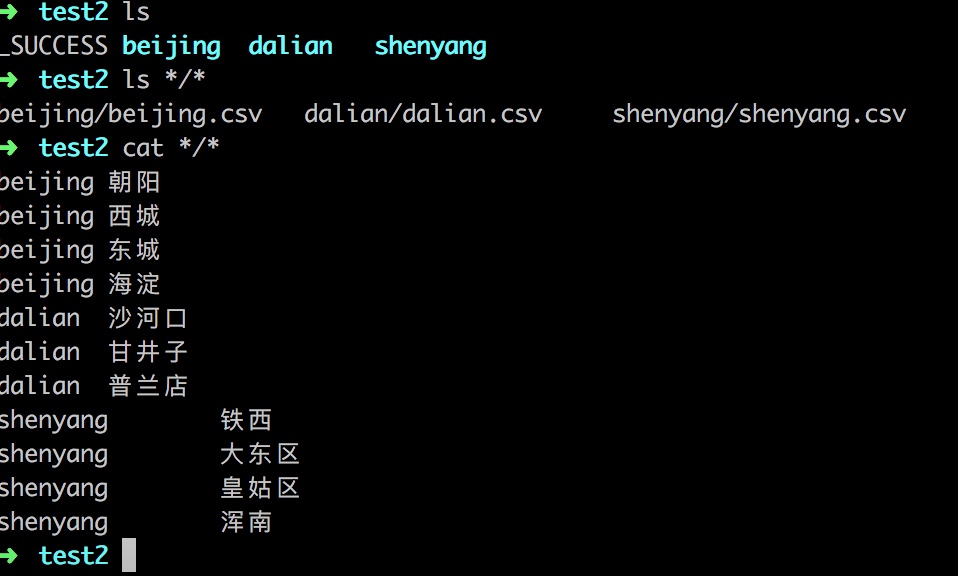
不足的地方就是输出的KV 很多情况下大家都是只需求V,这个我稍后会二次开发一下。然后再发博客哈















 7249
7249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









