







Python 的Web 应用:简单的Web 客户端
urlparse 和 urllib 模块
高级的 Web 客户端
网络爬虫/蜘蛛/机器人
CGI:帮助 Web 服务器处理客户端数据
创建 CGI 应用程序
在 CGI 中使用Unicode
高级 CGI
创建 Web 服务器
相关模块
20.1 介绍
本章有关Web 编程,可以帮助你对出Python 在因特网上的各种基础应用有个概要了解,例如通过Web 页面建立用户反馈表单,通过CGI 动态生成输出页面
20.1.1 Web 应用:客户端/服务器计算
Web 应用遵循客户端/服务器架构。Web 的客户端是浏览器,Web 服务器端,进程运行在信息提供商的主机上。这些服务器等待客户和文档请求,进行相应的处理,返回相关的数据。正如大多数客户端/服务器的服务器端一样,Web 服务器端被设置为“永远”运行。
一个用户执行一个像浏览器的这类客户端程序与Web 服务器取得连接,就可以在因特网上任何地方获得数据。客户端向服务器端发送一个请求,然后服务器端响应这个请求并将相应的数据返回给客户端。客户端可能向服务器端发出各种请求。这些请求可能包括获得一个网页视图或者提交一个包含数据的表单。请求经过服务器端的处理,会以特定的格式(HTML 等等)返回给客户端浏览。
Web 客户端和服务器端交互使用的“语言”,Web 交互的标准协议是HTTP(超文本传输协议)。HTTP协议是TCP/IP 协议的上层协议,这意味着HTTP 协议依靠TCP/IP 协议来进行低层的交流工作。它的职责不是路由或者传递消息(TCP/IP 协议处理这些),而是通过发送、接受HTTP 消息来处理客户端的请求。
HTTP 协议属于无状态协议,它不跟踪从一个客户端到另一个客户端的的请求信息,这点和我们现今使用的客户端/服务器端架构很像。服务器端持续运行,但是客户端的活动是按照这种结构独立进行的:一旦一个客户的请求完成后,活动将被终止。可以随时发送新的请求,但是他们会被处理成独立的服务请求。由于每个请求缺乏上下文背景,你可以注意到有些URL 会有很长的变量和值作为请求的一部分,以便提供一些状态信息。另外一个选项是“cookie”--保存在客户端的客户状态信息。本章的后面将会看到如何使用URL 和cookie 来保存状态信息。
20.1.2 因特网
因特网是一个连接全球客户端和服务器端的“迷雾”。客户端最终连接到服务器的通路,实际包含了不定节点的连通。作为一个客户端用户,所有这些实现细节都会被隐藏起来。抽象成为了从客户端到所访问的服务器端的直接连接。被隐藏起来的HTTP, TCP/IP 协议将会处理所有的繁重工作。中间的环节信息用户并不关心,所以将这些执行过程隐藏起来是有好处的。图20-2展示了因特网的扩展视图。
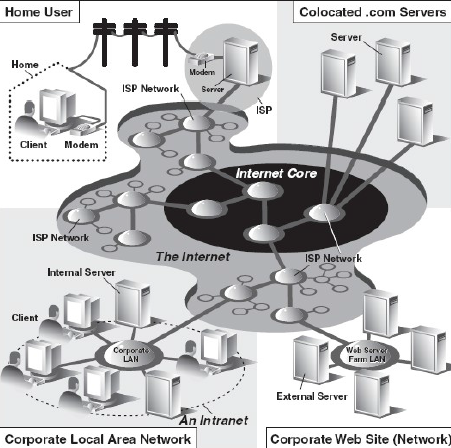
左侧指明了在哪里你可以找到Web 客户端,而右侧则暗示了Web 服务器的具体位置。如图所示:因特网是由多种工作在一定规则下的(也许非连贯的)相互连接的网络组成的。图表左侧的焦点是Web 客户端,在家上网的用户通过拨号连接到ISP(因特网供应商)上,上班族使用的则是公司的局域网。图表的右半部分关注的是Web 服务器端及位置所在。具有大型Web 站点的公司会将他们全部的“Web 服务器” 放在ISP 那里。这种物理安放被称为“整合”,这意味着你的服务器和其它客户的服务器一同放在ISP 处被“集中管理”。这些服务器或许为客户提供了不同的数据或者有一部分为应付重负荷(高数量用户群)而设计成了可以存储重复数据的系统。小公司的Web 站点或许不需要这么大的硬盘或者网络设备,也许仅有一个或者几个“整合”服务器安放在他们的ISP 处就可以了。
在任何一种情况下,大多数“整合”服务器被部署在大型ISP 提供的骨干网上,这意味着他们具有更高的“带宽”,如果你愿意,可以更接近因特网的核心点,从而可以更快的与因特网取得连接。这就允许客户端可以绕过许多网络直接快速的访问服务器,从而在指定的时间内可以使得更多的客户获得服务。
Web 应用是网络应用的一种最普遍的形式,但不是唯一的形式。Web 出现之前,因特网主要用于教学和科研目的。因特网上的大多数系统都是运行在Unix 平台上的—一个多用户操作系统,许多最初的因特网协议至今仍被沿用。这些协议包括telnet(允许用户在因特网上登录到远程的主机上,至今仍用),FTP 协议(文本传输协议,用户通过上传和下载文件可以共享文件和数据,至今仍用),Gopher(Web 搜索引擎的雏形—一个在互联网上爬动的小软件“gopher”可以自动寻找你感兴趣的数据),SMTP 或者叫做简单邮件传输协议(这个协议用于最古老的也是应用最广泛的电子邮件),NNTP(新闻对新闻传输协议)。
由于Python 的最初偏重就是因特网编程,除了其他一些东西外你还可以找到上边提及的所有协议。可以这样区分“因特网编程”和“Web 编程”,后者仅包括针对Web 的应用程序开发,也就是说Web 客户端和服务器是本章的焦点。因特网编程涵盖更多范围的应用程序:包括我们之前提及的一些因特网协议,例如:FTP, SMTP等,同时也包括我们前一章提到的网络编程和套接字编程。
20.2 使用Python 进行Web 应用:创建一个简单的Web 客户端
浏览器只是Web 客户端的一种。任何一个通过向服务器端发送请求来获得数据的应用程序都被认为是“客户端”。当然,也可以建立其他的客户端从而在因特网上检索出文档和数据。这样做的一个重要原因就是浏览器的能力有限,也就是说,它主要用于查看并同其他Web站点交互。另一方面,一个客户端程序,有能力做得更多—它不仅可以下载数据,同时也可以存储、操作数据,甚或可以将其传送到另外一个地方或者传给另外一个应用。
一个使用urllib 模块下载或者访问Web 上的信息的应用程序[使用urllib.urlopen() 或者urllib.urlre- trieve()]可以被认为是简单的Web 客户端。你所要做的就是提供一个有效的Web 地址。
20.2.1 统一资源定位符
简单的Web 应用包扩使用被称为URL(统一资源定位器)的Web 地址。这个地址用来在Web 上定位一个文档,或者调用一个CGI 程序来为你的客户端产生一个文档。URL 是大型标识符URI(统一资源标识)的一部分。这个超集是建立在已有的命名惯例基础上的。一个URL 是一个简单的URI,使用已存在的协议或规划(也就是 http,ftp 等)作为地址的一部分。为了进一步描绘这些,我们将会引入non-URL 的URI,有时这些被成为URN(统一资源名称),但是在今天我们唯一使用的一种URI是URL,至于URI 和URN 你也许没有听到太多,这或许已被保存成XML 标识符了。URL 使用这种格式:
prot_sch://net_loc/path;params?query#frag

net_loc 可以进一步拆分成多个部件,有些是必备的,其他的是可选部件,net_loc 字符串下:user:passwd@host :port
host 主机名是最重要的。端口号只有在Web 服务器运行其他非默认端口上时才会被使用。用户名和密码部分只有在使用FTP 连接时候才有可能用到,即使使用FTP,大多数的连接都是使用匿名这时是不需要用户名和密码的。

Python 支持两种不同的模块,分别以不同的功能和兼容性来处理URL。一种是urlparse,一种是urllib。
20.2.2 urlparse 模块
urlpasrse 模块提供了操作URL 字符串的基本功能。这些功能包括urlparse(), urlunparse()和urljoin().
urlparse()将URL 字符串拆分成如上所描述的一些主要部件。语法结构如下:
urlparse(urlstr, defProtSch=None, allowFrag=None)urlparse()将urlstr 解析成一个6-元组(prot_sch, net_loc,path, params, query,frag).如果urlstr 中没有提供默认的网络协议或下载规划时可以使用defProtSch。allowFrag 标识一个URL 是否允许使用零部件。
>>>urlparse.urlparse('http://www.python.org/doc/FAQ.html')
('http', 'www.python.org', '/doc/FAQ.html', '', '', '')urlparse.urlunparse()
urlunparse()的功能与urlpase()完全相反—它拼合一个6-元组(prot_sch, net_loc, path,params, query, frag)- urltup,它可能是一个URL 经urlparse()后的输出返回值:
urlunparse(urlparse(urlstr)) = urlstr
你或许已经猜到了urlunpase()的语法:
urlunparse(urltup)
urlparse.urljoin()
在需要多个相关的URL 时就需要使用urljoin()的功能了,如,在一个Web 页中生成的一系列页面的URL。Urljoin()的语法是:
urljoin(baseurl, newurl, allowFrag=None)
--------------------------------------------
urlparse 功能 描述
urlparse(urlstr,defProtSch=None,allowFrag=None) 将urlstr 解析成各个部件,如果在rulstr 中没有给定协议或者规划将使用defProtSch;allowFrag 决定是否允许有URL零部件。
urlunparse(urltup) 将URL数据(urltup)的一个元组反解析成一个URL 字符串。
urljoin(baseurl,newurl, allowFrag =None) 将URL 的基部件baseurl 和newurl 拼合成一个完整的URL;allowFrag 的作用和urlpase()中相同。
--------------------------------------------
urljoin()取得baseurl,并将其基路径(net_loc 附加一个完整的路径,但是不包括终端的文件)与newurl 连接起来。例如:
>>> urlparse.urljoin('http://www.python.org/doc/FAQ.html', \
... 'current/lib/lib.htm')
'http://www.python.org/doc/current/lib/lib.html'
在表20.3 中可以找到urlparse 的功能概述。
20.2.3 urllib 模块
核心模块:urllib
urllib 模块提供了所有你需要的功能,除非你计划写一个更加低层的网络客户端。urllib 提供了了一个高级的Web 交流库,支持Web 协议,HTTP, FTP 和Gopher 协议,同时也支持对本地文件的访问。urllib 模块的特殊功能是利用上述协议下载数据(从因特网、局域网、主机上下载)。使用这个模块可以避免使用httplib, ftplib 和gopherlib 这些模块,除非你想用更低层的功能。在那些情况下这些模块都是可选择的(注意:大多数以*lib 命名的模块用于客户端相关协议开发。并不是所有情况都是这样的,或许urllib 应该被命名为“internetlib”或者其他什么相似的名字)。
Urllib 模块提供了在给定的URL 地址下载数据的功能,同时也可以通过字符串的编码、解码来确保它们是有效URL 字符串的一部分。接下来要谈的功能包括urlopen(), urlretrieve(),quote(),unquote(), quote_plus(), unquote_plus(), 和 urlencode() 。可使用urlopen()方法返回文件类型对象。你会觉得这些方法不陌生,因为在第九章我们已经涉及到了文件方面的内容。
urllib.urlopen()
urlopen() 打开一个给定URL 字符串与Web 连接,并返回了文件类的对象。语法结构如下:
urlopen(urlstr, postQueryData=None)urlopen()打开urlstr 所指向的URL。如果没有给定协议或者下载规划,或者文件规划早已传入,urlopen()则会打开一个本地的文件。
对于所有的HTTP 请求,常见的请求类型是“GET”。在这些情况中,向Web 服务器发送的请求字符串(编码键值或引用,如urlencode()函数的字符串输出[如下])应该是urlstr 的一部分。如果要求使用“POST”方法,请求的字符串(编码的)应该被放到postQueryData 变量中。GET 和POST 请求是向Web 服务器上传数据的两种方法。
一旦连接成功,urlopen() 将会返回一个文件类型对象。例如,如果文件对象是f,那么“句柄”将会支持可读方法如:f.read(),f.readline(), f.readlines(), f.close(),和f.fileno().此外,f.info()方法可以返回MIME(Multipurpose Internet Mail Extension,多目标因特网邮件扩展)头文件。这个头文件通知浏览器返回的文件类型可以用哪类应用程序打开。例如,浏览器本身可以查看HTML,纯文本文件,生成PNG文件,JPEG或者GIF文件。其他的如多媒体文件,特殊类型文件需要通过扩展的应用程序才能打开。

最后,geturl()方法在考虑了所有可能发生的间接导向后,从最终打开的文件中获得真实的URL。
如果你打算访问更加复杂的URL 或者想要处理更复杂的情况如基于数字的权限验证,重定位,coockie 等问题,建议使用urllib2 模块。它同时还有一个urlopen()函数,但也提供了其他的可以打开各种URL 的函数和类。关于urllib2 的更多信息,将会在本章的下一部分介绍。
urllib.urlretrieve()
如果你对整个URL 文档的工作感兴趣,urlretrieve()可以帮你快速的处理一些繁重的工作:
urlretrieve(urlstr, localfile=None, downloadStatusHook=None)除了像urlopen()这样从URL 中读取内容,urlretrieve()可以方便地将urlstr 定位到的整个HTML 文件下载到你本地的硬盘上。可以将下载后的数据存成一个本地文件或者一个临时文件。如果该文件已经被复制到本地或者已经是一个本地文件,后续的下载动作将不会发生。如果可能,downloadStatusHook 这个函数将会在每块数据下载或传输完成后被调用。调用时使用下边三个参数:目前读入的块数,块的字节数和文件的总字节数。如果你正在用文本的或图表的视图向用户演示“下载状态”信息,这个函数将会是非常有用的。
urlretrieve()返回一个2-元组(filename, mime_hdrs)。filename 是包含下载数据的本地文件名,mime_hdrs 是对Web 服务器响应后返回的一系列MIME 文件头。要获得更多的信息,可以看mimetools 的Message 类。对本地文件来说mime_hdrs 是空的。
关于urlretrieve()的简单应用,可以看11.4(grabweb.py)中的例子。20.2 中将会介绍urlretrieve()更深层的应用。
urllib.quote() and urllib.quote_plus()
quote*()函数获取URL 数据,并将其编码,从而适用于URL 字符串中。尤其是一些不能被打印的或者不被Web 服务器作为有效URL 接收的特殊字符串必须被转换。这就是quote*()函数的功能。quote*()函数的语法如下:
quote(urldata, safe='/')逗号,下划线,句号,斜线和字母数字这类符号是不需要转化。其他的则均需要转换。另外,那些不被允许的字符前边会被加上百分号(%)同时转换成16 进制,例如:“%xx”,“xx”代表这个字母的ASCII 码的十六进制值。当调用quote*()时,urldata 字符串被转换成了一个可在URL 字符串中使用的等价值。safe 字符串可以包含一系列的不能被转换的字符。默认的是斜线(/)。quote_plus() 与quote()很像,另外它还可以将空格编码成+号。下边是一个使用quote()和quote_plus()的例子:
>>> name = 'joe mama'
>>> number = 6
>>> base = 'http://www/~foo/cgi-bin/s.py'
>>> final = '%s?name=%s&num=%d' % (base, name, number)
>>> final
'http://www/~foo/cgi-bin/s.py?name=joe mama&num=6'
>>>
>>> urllib.quote(final)
'http:%3a//www/%7efoo/cgi-bin/s.py%3fname%3djoe%20mama%26num%3d6'
>>> urllib.quote_plus(final)
'http%3a//www/%7efoo/cgi-bin/s.py%3fname%3djoe+mama%26num%3d6'urllib.unquote() 和 urllib.unquote_plus()
unquote*()函数与quote*()函数的功能安全相反—它将所有编码为“%xx”式的字母都转换成它们的ASCII 码值。Unquote*()的语法如下:unquote*(urldata)
调用unquote()函数将会把urldata 中所有的URL-编码字母都解码,并返回字符串。
Unquote_plus()函数会将加号转换成空格符。
urllib.urlencode()
在1.5.2 版的Python 中,urlopen()函数接收字典的键-值对,并将其编译成CGI 请求的URL 字符串的一部分。键值对的格式是“键=值”,以连接符(&)划分。更进一步,键和它们的值被传到quote_plus()函数中进行适当的编码。下边是urlencode()输出的一个例子:
>>> aDict = { 'name': 'Georgina Garcia', 'hmdir': '~ggarcia' }
>>> urllib.urlencode(aDict)
'name=Georgina+Garcia&hmdir=%7eggarcia'urllib 和urlparse 还有一些其他的功能,在这里我们就不一一概述了。阅读相关文档可以获得更多信息。
安全套接字层支持
在1.6 版中urllib 模块通过安全套接字层(SSL)支持开放的HTTP 连接.socket 模块的核心变化是增加并实现了SSL。 随后,urllib 和httplib 模块被上传用于支持URL 在“https”连接规划中的应用。除了那两个模块以外,其他的含有SSL 的模块还有: imaplib, poplib 和 smtplib。
本节讨论的urllib 函数的概要总结。

20.2.4 urllib2 模块
urllib2 可处理更复杂URL 的打开问题。比如有基本认证需求的Web 站点。最简单的“获得已验证参数”的方法是使用URL 部件net_loc,也就是说:http://user:passwd@www.python.org,这种解决方案的问题是不具有可编程性。然而使用urllib2,可以通过两种不同的方式来解决这个问题。
建立一个基础认证处理器(urllib2.HTTPBasicAuthHandler),同时在基本URL 或域上注册一个登录密码,这就意味着在Web 站点上定义了个安全区域。一旦完成这些,可以安装URL 打开器,通过这个处理器打开所有的URL。另一个可选的办法就是当浏览器提示的时候,输入用户名和密码 ,这样就发送了一个带有适当用户请求的认证头。
import urlib2
LOGIN='wesc'
PASSWD=""
URL=""
def handler_version(url):
'''
代码的“handler”版本分配了一个前面提到的基本处理器类,并添加了认证信息。之后
该处理器被用于建立一个URL-opener,并安装它以便所有已打开的URL 能用到这些认证信息
'''
from urlparse import urlparse as up
hdlr = urllib2.HTTPBasicAuthHandler()
hdlr.add_password('Archives', up(url)[1], LOGIN, PASSWD)
opener = urllib2.build_opener(hdlr)
urllib2.install_opener(opener)
return url
def request_version(url):
'''
“request”版本创建了一个Request 对象,并在HTTP 请求中添加了基本的base64编码认
证头信息。调用urlopen()时,该请求被用来替换其中的URL 字符串。注意原始URL 内
建在Requst 对象中,正因为如此在随后的urllib2.urlopen()中调用中替换URL 字符串
才不会产生问题。如果能直接用Harr 的HTTPRealmFinder 类就更好了,那样我们就没
必要在例子里使用硬编码了。
'''
from base64 import encodestring
req = urllib2.Request(url)
b64str = encodestring('%s:%s' % (LOGIN, PASSWD))[:-1]
req.add_header("Authorization", "Basic %s" % b64str)
return req
for funcType in ('handler', 'request'):
'''
剩余部分用两种技术分别打开了给定的URL,并显示服务器返回的HTML 页面第一行,当然前提是要通过认证。注意如果认证信息无效的话会返回一个HTTP 错误(并且不会有HTML)。
'''
print '*** Using %s:' % funcType.upper()
url = eval('%s_version')(URL)
f = urllib2.urlopen(url)
print f.readline()
f.close()还有一个很有用的文档可以在http://www.voidspace.org.uk/python/articles/urllib2.shtml 找到,你可以把它作为Python官方文档的补充。
20.3 高级Web 客户端
Web 浏览器是基本的Web 客户端。主要用来在Web 上查询或者下载文件。而Web 的高级客户端并不只是从因特网上下载文档。高级Web 客户端的一个例子就是网络爬虫(aka 蜘蛛和机器人)。这些程序可以基于不同目的在因特网上探索和下载页面,其中包括:
为 Google 和Yahoo 这类大型的搜索引擎建索引
脱机浏览—将文档下载到本地,重新设定超链接,为本地浏览器创建镜像。
下载并保存历史记录或框架
Web 页的缓存,节省再次访问Web 站点的下载时间。
我们下边介绍网络爬虫:crawl.py,抓取Web 的开始页面地址(URL),下载该页面和其它后续链接页面,但是仅限于那些与开始页面有着相同域名的页面。如果没有这个限制的话,你的硬盘将会被耗尽!crwal.py 的代码在例子20.2 中展示。
这个爬虫程序包括两个类,一个管理整个crawling 进程(Crawler),一个检索并解析每一个下载的Web 页面(Retriever)。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#coding=utf-8
from sys import argv
from os import makedirs, unlink, sep
from os.path import isdir, exists, dirname, splitext
from string import replace, find, lower
from htmllib import HTMLParser
from urllib import urlretrieve
import urllib
from urlparse import urlparse, urljoin
from formatter import DumbWriter, AbstractFormatter
from cStringIO import StringIO
class Retriever(object): # download Web pages
'''
从Web 下载页面,解析每个文档中的链接并在必要的时候把它们加入“to-do”队列,为
每个从网上下载的页面都创建一个Retriever 类的实例
'''
def __init__(self, url):
self.url = url
self.file = self.filename(url)
def filename(self, url, deffile='index.htm'):
'''
使用给定的URL 找出安全、有效的相关文件名并存储在本地。去掉URL 的“http://
”前缀,使用剩余的部分作为文件名,并创建必要的文件夹路径。那些没有文件名
前缀的URL 则会被赋予一个默认的文件名“index.htm”。(可以在调用filename()
时重新指定这个名字。)
'''
parsedurl = urlparse(url, 'http:', 0) # parse path
print "parsedurl", parsedurl
path = parsedurl[1] + parsedurl[2]
print "path", path
ext = splitext(path)
print "ext", ext
if ext[1] == '':
if path[-1] == '/':
path += deffile
else:
path += '/' + deffile
print "path", path
ldir = dirname(path) # local directory
print "ldir", ldir
if sep != '/': # os-indep. path separator
ldir = replace(ldir, ',', sep)
if not isdir(ldir): # create archive dir if nec.
if exists(ldir):
unlink(ldir)
makedirs(ldir)
return path
def download(self): # download Web page
'''
使用URL 调用urllib.urlretrieve()函数并把结果保存在filename 中(该值由filename()返回)
'''
try:
retval = urllib.urlretrieve(self.url, self.file)
print retval
except IOError:
retval = ('*** ERROR: invalid URL "%s"' % \
self.url, )
return retval
def parseAndGetLinks(self): # pars HTML, save links
self.parser = HTMLParser(AbstractFormatter( \
DumbWriter(StringIO())))
self.parser.feed(open(self.file).read())
self.parser.close()
return self.parser.anchorlist
class Crawler(object): # manage entire crawling process
count = 0 # static downloaded page counter
def __init__(self, url):
self.q = [url]
self.seen = []
self.dom = urlparse(url)[1]
def getPage(self, url):
r = Retriever(url)
retval = r.download()
'''
如果下载成功,parse()方法会被调用来解析刚从网络拷贝下来的页面;否则会返
回一个错误字符串
'''
if retval[0] == '*': # error situation, do not parse
print retval, '... skipping parse'
return
Crawler.count = Crawler.count + 1
print '\n(', Crawler.count, ')'
print 'URL:', url
print 'FILE:', retval[0]
self.seen.append(url)
'''
调用parseAndGetLinks()方法来解析新下载的页面并决定该页面中每个链接的后续
动作
'''
links = r.parseAndGetLinks() # get and process links
print links
for eachLink in links:
if eachLink[:4] != 'http' and \
find(eachLink, '://') == -1:
eachLink = urljoin(url, eachLink)
print '* ', eachLink,
if find(lower(eachLink), 'mailto:') != -1:
print '... discarded, mailto link'
continue
if eachLink not in self.seen:
if find(eachLink, self.dom) == -1:
print '... discarded, not in domain'
else:
if eachLink not in self.q:
self.q.append(eachLink)
print '... new, added to Q'
else:
print '... discarded, already in Q'
else:
print '... discarded, already processed'
def go(self): # process links in queue
while self.q:
url = self.q.pop()
self.getPage(url)
def main():
if len(argv) > 1:
url = argv[1]
else:
try:
url = raw_input('Enter starting URL: ')
except (KeyboardInterrupt, EOFError):
url = ''
if not url: return
robot = Crawler(url)
robot.go()
if __name__ == '__main__':
main()如果为应用程序添加线程,就可以为每个待抓爬的站点分别创建实例。
20.4 CGI:帮助Web 服务器处理客户端数据
20.4.1 CGI 介绍
随着因特网和Web 服务器的形成,产生了处理用户输入的需求,并成为了Web 站点可以从用户那里获得特殊信息的唯一形式。反过来,在客户提交了特定数据后,就要求立即生成HTML 页面。
现在Web 服务器仅有一点做的很不错,获取用户对文件的请求,并将这个文件(HTML文件)返回给客户端。它们现在还不具有处理字段类特殊数据的机制。
过程开始于Web 服务器从客户端接到了请求(GET 或者POST),并调用合适的程序。然后开始等待HTML 页面—与此同时,客户端也在等待。一旦程序完成,会将生成的动态HTML 页面返回到服务器端,然后服务器端再将这个最终结果返回给用户。服务器接到表单反馈,与外部应用程序交互,收到并返回新生成的HTML 页面都发生在一个叫做Web 服务器CGI(Common Gateway Interface)的接口上.图20-3 描述了CGI 的工作原理。

(CGI 代表了在一个Web 服务器和能够处理用户表单、生成并返回动态HTML 页的应用程序间的交互。)
创建HTML 的CGI 应用程序通常是用高级编程语言来实现的,可以接受、处理数据,向服务器端返回HTML 页面。目前使用的编程语言有Perl, PHP, C/C++,或者Python。在我们研究CGI 之前,我们必须告诉你典型的Web 应用产品已经不再使用CGI 了。
由于它词义的局限性和允许Web 服务器处理大量模拟客户端数据能力的局限性,CGI 几乎绝迹。
Web 服务的关键使命依赖于遵循像C/C++这样语言的规范。如今的Web 服务器典型的部件有Aphache和集成的数据库部件(MySQL 或者PostgreSQL),Java(Tomcat),PHP 和各种Perl 模块,Python 模块,以及SSL/security。然而,如果你工作在私人小型的或者小组织的Web 网站上的话就没有必要使用这种强大而复杂的Web 服务器, CGI 是一个适用于小型Web 网站开发的工具。更进一步来说,有很多Web 应用程序开发框架和内容管理系统,这些都弥补了过去CGI 的不足。为了开发更加高效的Web 服务有必要理解CGI 实现的基本原理。下一部分讲解在cgi 模块的协助下如何在Python 中建立一个CGI 应用程序。
20.4.2 CGI 应用程序
CGI 应用程序和典型的应用程序有些不同。主要的区别在于输入、输出以及用户和计算机交互方面。当一个CGI 脚本开始执行时,它需要检索用户-支持表单,但这些数据必须要从Web 的客户端才可以获得,而不是从服务器或者硬盘上获得。
这些不同于标准输出的输出将会返回到连接的Web 客户端,而不是返回到屏幕、CUI 窗口或者硬盘上。这些返回来的数据必须是具有一系列有效头文件的HTML。否则,如果浏览器是Web 的客户端,由于浏览器只能识别有效的HTTP 数据,那么返回的也只能是个错误消息(具体的就是因特网服务器错误)。
最后,可能和你想象的一样,用户不能与脚本进行交互。所有的交互都将发生在Web 客户端(用户的行为),Web 服务器端和CGI 应用程序间。
20.4.2 cgi 模块
在cgi 模块中有个主要类:FieldStorage 类,它完成了所有的工作。这个类将会被实例化,它会从Web 客户端读出用户信息。一旦这个对象被实例化,它将会包含一个类似字典的对象,具有一系列的键-值对,键就是通过表单传入的表单条目的名字,而值则包含相应的数据。
这些值本身可以是以下三种对象之一。
FieldStorage 对象(实例);
类似的名为MiniFieldStorage 类的实例,用在没有文件上传或mulitple-part 格式数据的情况。MiniFieldStorage 实例只包含名字和数据的键-值对;
这些对象的列表。这发生在表单中的某个域有多个输入值的情况下;
20.5 建立CGI 应用程序
20.5.1 建立Web 服务器
用Python 进行CGI 开发,需要安装一个Web 服务器,将其配置成可以处理PythonCGI 请求的模式,然后Web 服务器访问CGI 脚本。一个真正的Web 服务器,须下载并安装Aphache。Aphache 的插件或模块可以处理Python CGI,但例子里并不是必要的。如果你准备把自己的服务"带入真实世界",也许会想安装这些软件。为了学习的目的或者是建立小型的Web 站点,使用Python 自身带的Web 服务器就已经足够了。在第20.8 节,学习如何建立和配置简单的基于Python 的Web 服务器。
如果只是想建立一个基于Web 的服务器,可直接执行下边的Python 语句:
$ python -m CGIHTTPServer当前目录下建立一个端口号为8000 的Web 服务器。在该目录下建立一个文件夹Cgi–bin。将一些HTML 文件放到那个目录下,.py CGI 脚本在Cgi-bin 中,就可以在地址栏中输入这些地址来访问Web 站点啦。
http://localhost:8000/friends.htm http://localhost:8000/cgi-bin/friends2.py
20.5.2 建立表单页
friends.html 表单包括两个输入变量:person 和 howmany,这两个值将会被传到CGI 脚本friends1.py 中。将CGI 脚本初始化到主机默认的cgi-bin 目录下。(如果这个信息与你开发环境不一样的话,在测试Web 页面和CGI 之前请更新你的表单事件)。所有的请求将会采用默认的GET 方法。选择GET 方法是因为我们的表单没有太多的字段,同时我们希望我们的请求字段可以在“位置”(aka“Address”, “Go To”)条中显示,以便你可以看到被送到服务器端的URL。
<HTML><HEAD><TITLE>
Friends CGI Demo (static screen)
</TITLE></HEAD>
<BODY><H3>Friends list for: <I>NEW USER</I></H3>
<FORM ACTION="/cgi-bin/friends1.py">
<B>Enter your Name:</B>
<INPUT TYPE=text NAME=person VALUE="NEW USER" SIZE=15>
<P><B>How many friends do you have?</B>
<INPUT TYPE=radio NAME=howmany VALUE="0" CHECKED> 0
<INPUT TYPE=radio NAME=howmany VALUE="10"> 10
<INPUT TYPE=radio NAME=howmany VALUE="25"> 25
<INPUT TYPE=radio NAME=howmany VALUE="50"> 50
<INPUT TYPE=radio NAME=howmany VALUE="100"> 100
<P><INPUT TYPE=submit></FORM></BODY></HTML>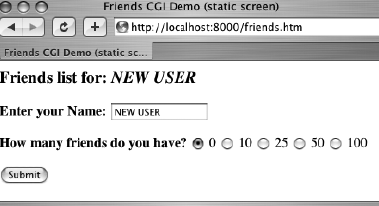
20.5.3 生成结果页
按下“Submit”按钮(也可以在该文本字段中按下回车键获得相同的效果。)当这些发生后, friends1.py 将会随CGI 一起被执行。
这个脚本包含了所有的编程功能,读出并处理表单的输入,同时向用户返回结果HTML 页面。表单的变量是FieldStorage 的实例,包含person 和howmanyh 字段的值。把这些值本分别存入Python 的who 和howmany 变量中。变量reshtml 包含需要返回的HTML 文本的正文,还有一些动态填好的字段,这些数据都是从表单中读入的。
#!/usr/bin/env python
import cgi
reshtml = '''Content-Type: text/html\n
<HTML><HEAD><TITLE>
Friends CGI Demo (dynamic screen)
</TITLE></HEAD>
<BODY><H3>Friends list for: <I>%s</I></H3>
Your name is: <B>%s</B><P>
You have <B>%s</B> friends.
</BODY></HTML>'''
form = cgi.FieldStorage()
who = form['person'].value
howmany = form['howmany'].value
print reshtml % (who, who, howmany)核心提示:HTML 头文件是从HTML 中分离出来的。
在向CGI 脚本返回结果时,须先返回一个适当的HTTP 头文件后才会返回结果HTML 页面。进一步说,为了区分这些头文件和结果HTML 页面,需要在friends1.py的第五行中插入几个换行符。注意GET 请求是如何将表单中的变量和值加载在URL 地址条中的。,结果页面的HTML 不是以文本文件的形式存在硬盘上的,而是由我们的CGI 脚本生成的,并且将其以本地文件的形式返回。
20.5.4 生成表单和结果页面
删除fiends.html 文件并将其合并到friends2.py 中。但是我们如何控制生成哪个页面呢?如果有表单数据被发送,那就意味着我们需要建立一个结果页面。如果我们没有获得任何的信息,这就说明我们需要生成一个用户可以输入数据的表单页面。例子20.5 展示的就是我们的新脚本friends2.py
#!/usr/bin/env python
import cgi
header = 'Content-Type: text/html\n\n'
formhtml = '''<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>Friends list for: <I>NEW USER</I></H3>
<FORM ACTION="/cgi-bin/friends2.py">
<B>Enter your Name:</B>
<INPUT TYPE=hidden NAME=action VALUE=edit>
<INPUT TYPE=text NAME=person VALUE="NEW USER" SIZE=15>
<P><B>How many friends do you have?</B>
%s
<P><INPUT TYPE=submit></FORM></BODY></HTML>'''
fradio = '<INPUT TYPE=radio NAME=howmany VALUE="%s" %s> %s\n'
def showForm():
friends = ''
for i in [0, 10, 25, 50, 100]:
checked = ''
if i == 0:
checked = 'CHECKED'
friends = friends + fradio % \
(str(i), checked, str(i))
print header + formhtml % (friends)
reshtml = '''<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>Friends list for: <I>%s</I></H3>
Your name is: <B>%s</B><P>
You have <B>%s</B> friends.
</BODY></HTML>'''
def doResults(who, howmany):
print header + reshtml % (who, who, howmany)
def process():
form = cgi.FieldStorage()
if form.has_key('person'):
who = form['person'].value
else:
who = 'NEW USER'
if form.has_key('howmany'):
howmany = form['howmany'].value
else:
howmany = 0
if form.has_key('action'):
doResults(who, howmany)
else:
showForm()
if __name__ == '__main__':
process()表单中action 处的“hidden”变量值为“edit”。显示哪个页面的途径是通过这个字段。
20.5.5 全面交互的Web 站点
在结果页面上加个链接允许返回到表单页面 ,但是我们返回的是含有用户输入信息的页面而不是一个空白页面。friends3.py 和friends2.py 没有太大的不同。把URL 从表单中抽出来是因为现在有2 个地方需要它,结果页面是它的新顾客。
错误页面的显示使用了JavaScript 的“后退”按钮。因为按钮都是输入类型的,所以需要一个表单,但不需要有动作因为我们只是简单的后退到浏览器历史中的上一个页面。尽管我们的脚本目前只支持(或者说探测、测试)一种类型的错误,但我们仍然使用了一个通用的error 变量,这是为了以后还可以继续开发这个脚本,给它增加更多的错误检测。
例20.6 全用于交互和错误处理(friends3.py)通过加上返回输入信息的表单页面的连接,我们实现了整个循环,给了用户一次完整的Web 应用体验。我们的应用程序现在也进行了一些简单的错误验证,在用户没有选择任何单选按钮时,可以通知用户。
#!/usr/bin/env python
import cgi
from urllib import quote_plus
from string import capwords
header = 'Content-Type: text/html\n\n'
url = '/cgi-bin/friends3.py'
errhtml = '''<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>ERROR</H3>
<B>%s</B><P>
<FORM><INPUT TYPE=button VALUE=Back
ONCLICK="window.history.back()"></FORM>
</BODY></HTML>'''
def showError(error_str):
print header + errhtml % (error_str)
formhtml = '''<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>Friends list for: <I>%s</I></H3>
<FORM ACTION="%s">
<B>Your Name:</B>
<INPUT TYPE=hidden NAME=action VALUE=edit>
<INPUT TYPE=text NAME=person VALUE="%s" SIZE=15>
<P><B>How many friends do you have?</B>
%s
<P><INPUT TYPE=submit></FORM></BODY></HTML>'''
fradio = '<INPUT TYPE=radio NAME=howmany VALUE="%s" %s> %s\n'
def showForm(who, howmany):
friends = ''
for i in [0, 10, 25, 50, 100]:
checked = ''
if str(i) == howmany:
checked = 'CHECKED'
friends = friends + fradio % \
(str(i), checked, str(i))
print header + formhtml % (who, url, who, friends)
reshtml = '''<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>Friends list for: <I>%s</I></H3>
Your name is: <B>%s</B><P>
You have <B>%s</B> friends.
<P>Click <A HREF="%s">here</A> to edit your data again.
</BODY></HTML>'''
def doResults(who, howmany):
newurl = url + '?action=reedit&person=%s&howmany=%s' % \
(quote_plus(who), howmany)
print header + reshtml % (who, who, howmany, newurl)
def process():
error = ''
form = cgi.FieldStorage()
if form.has_key('person'):
who = capwords(form['person'].value)
else:
who = 'NEW USER'
if form.has_key('howmany'):
howmany = form['howmany'].value
else:
if form.has_key('action') and \
form['action'].value == 'edit':
error = 'Please select number of friends.'
else:
howmany = 0
if not error:
if form.has_key('action') and \
form['action'].value != 'reedit':
doResults(who, howmany)
else:
showForm(who, howmany)
else:
showError(error)
if __name__ == '__main__':
process()这个脚本的一个目的是创建一个有意义的链接,以便从结果页面返回表单页面。当有错误发生时,用户可以使用这个链接返回表单页面去更新他/她填写的数据。新的表单页面只有当它包含了用户先前输入的信息时才有意义。(如果让用户重复输入这些信息会很令人沮丧!)
为了实现这一点,我们需要把当前值嵌入到更新过的表单中。在第27 行,我们给name 新增了一个值。这个值如果给出的话,会被插入到name 字段。显然地,在初始表单页面上它将是空值。第38-41 行,我们根据当前选定的朋友数目设置了单选按钮。最后,通过第49 行和52-55 行更新了的doResults()函数,我们创建了这个包含已有信息的链接,它会让用户“返回”到我们更改后的表单页面。
最后我们从美学角度上加了一个简单的特性。在friends1.py 和friends2.py 的截屏中,可以看到返回结果和用户的输入一字不差。在上述的截屏中,如果用户的名字没有大写这将影响返回的页面。我们加了一个对string.capwords()函数的调用从而自动的将用户名置成大写。capwords()函数可以将传进来的每个单词的第一个字母置成大写的。这也许是或许不是必要的特性,但是我们还是愿意一起分享它,以便你知道这个功能的存在。
20.6 在CGI 中使用Unicode 编码
演示一个具有Unicode输出的简单CGI 脚本,并给浏览器足够的提示,从而可以正确的生成这些字符。唯一的要求是你的计算机必须装有对应的东亚字体以便浏览器可以显示它们。为了看到Unicode 的作用,将会用CGI 脚本生成一个多语言功能的Web 页面。首先用Unicode 字符串定义一些消息。假设你的编辑器只能输入ASCII 编码。因此,非ASCII 编码的字符使用\u 转义符输入。实际上从文件或数据库中也能读取这些消息。
# Greeting in English, Spanish,
# Chinese and Japanese. UNICODE_HELLO = u""" Hello!
\u00A1Hola!
\u4F60\u597D!
\u3053\u3093\u306B\u3061\u306F!
"""CGI 产生的第一个头信息指出内容类型(content-type)是HTTP。此处还声明了消息是以UTF-8编码进行传输的,这点很重要,这样浏览器才可以正确的翻译它。
print 'Content-type: text/html; charset=UTF-8\r'
print '\r'例20.7 简单Unicode CGI 示例(uniCGI.py)这个脚本输出到你Web 浏览器端的是Unicode 字符串。
#!/usr/bin/env python
CODEC = 'UTF-8'
UNICODE_HELLO = u'''
Hello!
\u00A1Hola!
\u4F60\u597D!
\u3053\u3093\u306B\u3061\u306F!
'''
print 'Content-Type: text/html; charset=%s\r' % CODEC
print '\r'
print '<HTML><HEAD><TITLE>Unicode CGI Demo</TITLE></HEAD>'
print '<BODY>'
print UNICODE_HELLO.encode(CODEC)
print '</BODY></HTML>'然后输出真正的消息。事先用string 类的encode()方法先将这个字符串转换成UTF-8 序列。
20.7 高级CGI
包括cookie 的使用(保存在客户端的缓存数据),同一个CGI 字段的多重值,和用multipart 表单实现的文件上传。为了节省空间,会在同一个程序中向你展示这三个特性。首先让我们看下多次提交问题。
20.7.1 Mulitipart 表单提交和文件的上传
CGI 特别指出只允许两种表单编码,“ application/x-www-form-urlencoded ” 和“multipart/form-dat”,前者是默认的。
<FORM enctype="application/x-www-form-urlencoded" ...>对于multipart 表单,需要明确给出编码:
<FORM enctype="multipart/form-data" ...>在表单提交时你可以使用任一种编码,但在目前上传的文件仅能表现为multipart 编码。通过使用输入文件类型完成文件上传:
<INPUT type=file name=...>这个指令表现为一个空的文本字段,同时旁边有个按钮,可以让你浏览文件目录系统,找到要上传的文件。同时还需要有一个单独的编码,因为它还没有聪明到“通过URL 编码”的程度,尤其是对一个二进制文件。这些信息仍然会到达服务器,只是以一种不同的“封装”形式而已。
不论你使用的是默认编码还是multipart 编码,cgi 模块都会以同样的方式来处理它们,在表单提交时提供键和相应的值。你还可以像以前那样通过FieldStorage 实例来访问数据。
20.7.2 多值字段
除了上传文件,会展示如何处理具有多值的字段。最常见的情况就是你有一系列的复选框允许用户有多个选择。每个复选框都会标上相同的字段名,但是为了区分它们,会有不同的值与特定的复选框关联。
正如你所知道的,在表单提交时,数据从用户端以键-值对形式发送到服务器端。当提交不止一个复选框时,就会有多个值对应同一个键。在这种情况下,cgi 模块将会建立一个这类实例的列表,你可以遍历获得所有的值,而不是为你的数据指定一个MiniFielStorage 实例。
20.7.3 cookie
如果你对cookie 还不太熟悉的话,可以把它们看成是Web站点服务器要求保存在客户端(例如浏览器)上的二进制数据。
由于HTTP 是一个“无状态信息”的协议,是通过GET 请求中的键值对来完成信息从一个页面到另一个页面的传递。实现这个功能的另外一种方法如我们以前看到的一样,是使用隐藏的表单字段。这些信息必须被嵌入新生成的页面中并返回给客户端,所以这些变量和值由服务器来管理。还有一种可以保持对多个页面浏览连续性的方法就是在客户端保存这些数据。这就是引进cookie 的原因。服务器可以向客户端发送一个请求来保存cookie,而不必用在返回的Web 页面中嵌入数据的方法来保持数据。Cookie 连接到最初的服务器的主域上(这样一个服务器就不能设置或者覆盖其他服务器上的cookie),并且有一定的生存期限(因此你的浏览器不会堆满cookie)。
这两个属性是通过有关数据条目的键-值对和cookie 联系在一起的。cookie 还有一些其他的属性,如域子路径,cookie 安全传输请求。
有了coockies,我们不再需要为了跟踪用户而将数据从一页传到另一页了。虽然这在隐私问题上也引发了大量的争论,多数Web 站点还是合理地使用了cookie。为了准备代码,在客户端获得请求文件前,Web 服务器向客户端发送“SetCookie”头文件要求客户端存储cookie一旦在客户端建立了cookie,HTTP_COOKIE 环境变量会将那些cookie 自动放到请求中发送给服务器。cookie 是以分号分隔的键值对存在的。要访问这些数据,你的应用程序就要多次拆分这些字符串(也就是说,使用str.split()或者手动解析)。cookie 以分号(;)分隔,每个键-值对中间都由等号(=)分开。
20.7.4 使用高级CGI
现在我们来展示CGI 应用程序, advcgi.py,它的代码号功能和本章前部分讲到的friends3.py的差别不是很大。默认的第一页是用户填写的表单,它由四个主要部分组成:用户设置cookie 字符串,姓名字段,编程语言复选框列表,文件提交框。在图20-14 中可以看到示图。
图20-15 是在另一个浏览器看到的表单效果图,在这个表单中,我们可以输入自己的信息,如图20-16 中给的样式。注意查找文件的按钮在不同的浏览器中显示的文字是不同的,如,“Browse...”,“Choose”, “...”等。
这些数据以mutipart 编码提交到服务器端,在服务器端以同样的方式用FieldStorage 实例获取。唯一不同的就是对上传文件的检索。在我们的应用程序中,我们选择的是逐行读取,遍历文件。
如果你不介意文件的大小的话,也可以一次读入整个文件。
由于这是服务器端第一次接到数据,这时,当我们向客户端返回结果页面时,我们使用“SetCookie:”头文件来捕获浏览器端的cookie。
图20–14
--------------------------------------------
图20-14 上传及多值表单页 IE5 浏览器, MacOS X 系统
在图20-17 中,你可以看到数据提交后的结果展示。用户输入的所有数据都可以在页面中显示出来。在最后对话框中指定的文件也被上传到了服务器端,并显示出来。
你也会注意到在结果页面下方的那个链接,它使用相同的CGI 脚本,可以帮我们返回表单页。
如果我们单击下方的那个链接,没有任何表单数据提交给我们的脚本,因此会显示一个表单页面。然而,如你在图20-17 中看到的一样,所有的东西都可以显示出来,并非是一个空的表单!我们前边输入的信息都被显示出来了!在没有表单数据的情况下我们是怎样做到这一点的呢(将其隐藏或者作为URL 中的请求参数)?实际上秘密是这些数据都被保存在客户端的cookie 中了。
用户的cookie 将用户输入表单中的值都保存了起来,用户名,使用的语言,上传文件的信息都会存储在cookie 中。
当脚本检测到表单没有数据时,它会返回一个表单页面,但是在表单页面建立前,它们从客户端的cookie 中抓取了数据(当用户在单击了那个链接的时候将会自动传入)并且相应的将其填入表单中。因此当表单最终显示出来时,先前的输入便会魔术般的显示在用户面前(图20-18)。
图 20–15
--------------------------------------------
图20-15 同一个高级CGI 在Netscape4 浏览器,Linux 系统
我们相信你现在已经迫不及待的想看下这个程序了,详见例子20.8.
advcgi.py 和我们本章前部分提到的CGI 脚本friends3.py 相当的像。它有表单页、结果页、错误页可以返回。新的脚本中除了有所有的高级CGI 特性外,我们还在脚本中增加了更多的面向对象特征:用类和方法代替了一系列的函数。我们页面的HTML 文本对我们的类来说都是静态的了,这就意味着它们在实例中都是以常量出现的—虽然我们这里仅有一个实例。
图20–16
--------------------------------------------
图20-16 高级CGI 提交演示 Opera8 Win32 系统
逐行解释(以块划分)
1-7 行
普通的起始、和模块导入行出现在这里。唯一你可能不太熟悉的模块是cStringIO,我们曾在第
10 章简单讲解过它并在例20.1 中用过。cStringIO.StingIO()会在字符串上创建一个类似文件的对
象,所以访问这个字符串与打开一个文件并使用文件句柄去访问数据很相似。
图 20–17
--------------------------------------------
图 20–17 Results page generated and returned by the Web server in Opera4 on
Win32
9-12 行
在声明AdvCGI 类之后,header 和url(静态)变量被创建出来,在显示所有不同页面的方法中
会用到这些变量。
14-80 行
所有这个块中的代码都是用来创建、显示表单页面的。那些数据属性都是不言自明的。
getCPPcookie()取得Web 客户端发来的cookie 信息,而showForm()校对所有这些信息并把表单页面
返回给客户端。
Edit By Vheavens
Edit By Vheavens
图 20–18
--------------------------------------------
图 20–18 Form page with data loaded from the Client cookie
82-91 行
这个代码块负责错误页面。
93-144 行
结果页面的生成使用了本块代码。setCPPcookie()方法要求客户端为我们的应用程序存储
cookie,而doResults()方法聚集所有数据并把输出发回客户端。
--------------------------------------------
Example 20.8 Advanced CGI Application (advcgi.py)
这个脚本有一个处理所有事情的主函数,AdvCGI, 它有方法显示表单、错误或结果页面,同时
也可以从客户端(Web 浏览器)读写cookie。
Edit By Vheavens
Edit By Vheavens
1 #!/usr/bin/env python
2
3 from cgi import FieldStorage
4 from os import environ
5 from cStringIO import StringIO
6 from urllib import quote, unquote
7 from string import capwords, strip, split, join
8
9 class AdvCGI(object):
10
11 header = 'Content-Type: text/html\n\n'
12 url = '/py/advcgi.py'
13
14 formhtml = '''<HTML><HEAD><TITLE>
15 Advanced CGI Demo</TITLE></HEAD>
16 <BODY><H2>Advanced CGI Demo Form</H2>
17 <FORM METHOD=post ACTION="%s" ENCTYPE="multipart/form-data">
18 <H3>My Cookie Setting</H3>
19 <LI> <CODE><B>CPPuser = %s</B></CODE>
20 <H3>Enter cookie value<BR>
21 <INPUT NAME=cookie value="%s"> (<I>optional</I>)</H3>
22 <H3>Enter your name<BR>
23 <INPUT NAME=person VALUE="%s"> (<I>required</I>)</H3>
24 <H3>What languages can you program in?
25 (<I>at least one required</I>)</H3>
26 %s
27 <H3>Enter file to upload</H3>
28 <INPUT TYPE=file NAME=upfile VALUE="%s" SIZE=45>
29 <P><INPUT TYPE=submit>
30 </FORM></BODY></HTML>'''
31
32 langSet = ('Python', 'PERL', 'Java', 'C++', 'PHP',
33 'C', 'JavaScript')
34 langItem = \
35 '<INPUT TYPE=checkbox NAME=lang VALUE="%s"%s> %s\n'
36
37 def getCPPCookies(self): # read cookies from client
38 if environ.has_key('HTTP_COOKIE'):
39 for eachCookie in map(strip, \
Edit By Vheavens
Edit By Vheavens
40 split(environ['HTTP_COOKIE'], ';')):
41 if len(eachCookie) > 6 and \
42 eachCookie[:3] == 'CPP':
43 tag = eachCookie[3:7]
44 try:
45 self.cookies[tag] = \
46 eval(unquote(eachCookie[8:]))
47 except (NameError, SyntaxError):
48 self.cookies[tag] = \
49 unquote(eachCookie[8:])
50 else:
51 self.cookies['info'] = self.cookies['user'] = ''
52
53 if self.cookies['info'] != '':
54 self.who, langStr, self.fn = \
55 split(self.cookies['info'], ':')
56 self.langs = split(langStr, ',')
57 else:
58 self.who = self.fn = ' '
59 self.langs = ['Python']
60
61 def showForm(self): # show fill-out form
62 self.getCPPCookies()
63 langStr = ''
64 for eachLang in AdvCGI.langSet:
65 if eachLang in self.langs:
66 langStr += AdvCGI.langItem % \
67 (eachLang, ' CHECKED', eachLang)
68 else:
69 langStr += AdvCGI.langItem % \
70 (eachLang, '', eachLang)
71
72 if not self.cookies.has_key('user') or \
73 self.cookies['user'] == '':
74 cookStatus = '<I>(cookie has not been set yet)</I>'
75 userCook = ''
76 else:
77 userCook = cookStatus = self.cookies['user']
78
79 print AdvCGI.header + AdvCGI.formhtml % (AdvCGI.url,
Edit By Vheavens
Edit By Vheavens
80 cookStatus, userCook, self.who, langStr, self.fn)
81
82 errhtml = '''<HTML><HEAD><TITLE>
83 Advanced CGI Demo</TITLE></HEAD>
84 <BODY><H3>ERROR</H3>
85 <B>%s</B><P>
86 <FORM><INPUT TYPE=button VALUE=Back
87 ONCLICK="window.history.back()"></FORM>
88 </BODY></HTML>'''
89
90 def showError(self):
91 print AdvCGI.header + AdvCGI.errhtml % (self.error)
92
93 reshtml = '''<HTML><HEAD><TITLE>
94 Advanced CGI Demo</TITLE></HEAD>
95 <BODY><H2>Your Uploaded Data</H2>
96 <H3>Your cookie value is: <B>%s</B></H3>
97 <H3>Your name is: <B>%s</B></H3>
98 <H3>You can program in the following languages:</H3>
99 <UL>%s</UL>
100 <H3>Your uploaded file...<BR>
101 Name: <I>%s</I><BR>
102 Contents:</H3>
103 <PRE>%s</PRE>
104 Click <A HREF="%s"><B>here</B></A> to return to form.
105 </BODY></HTML>'''
106
107 def setCPPCookies(self):# tell client to store cookies
108 for eachCookie in self.cookies.keys():
109 print 'Set-Cookie: CPP%s=%s; path=/' % \
110 (eachCookie, quote(self.cookies[eachCookie]))
111
112 def doResults(self):# display results page
113 MAXBYTES = 1024
114 langlist = ''
115 for eachLang in self.langs:
116 langlist = langlist + '<LI>%s<BR>' % eachLang
117
118 filedata = ''
119 while len(filedata) < MAXBYTES:# read file chunks
Edit By Vheavens
Edit By Vheavens
120 data = self.fp.readline()
121 if data == '': break
122 filedata += data
123 else: # truncate if too long
124 filedata += \
125 '... <B><I>(file truncated due to size)</I></B>'
126 self.fp.close()
127 if filedata == '':
128 filedata = \
129 <B><I>(file upload error or file not given)</I></B>'
130 filename = self.fn
131
132 if not self.cookies.has_key('user') or \
133 self.cookies['user'] == '':
134 cookStatus = '<I>(cookie has not been set yet)</I>'
135 userCook = ''
136 else:
137 userCook = cookStatus = self.cookies['user']
138
139 self.cookies['info'] = join([self.who, \
140 join(self.langs, ','), filename], ':')
141 self.setCPPCookies()
142 print AdvCGI.header + AdvCGI.reshtml % \
143 (cookStatus, self.who, langlist,
144 filename, filedata, AdvCGI.url)
145
146 def go(self): # determine which page to return
147 self.cookies = {}
148 self.error = ''
149 form = FieldStorage()
150 if form.keys() == []:
151 self.showForm()
152 return
153
154 if form.has_key('person'):
155 self.who = capwords(strip(form['person'].value))
156 if self.who == '':
157 self.error = 'Your name is required. (blank)'
158 else:
159 self.error = 'Your name is required. (missing)'
Edit By Vheavens
Edit By Vheavens
160
161 if form.has_key('cookie'):
162 self.cookies['user'] = unquote(strip(\
163 form['cookie'].value))
164 else:
165 self.cookies['user'] = ''
166
167 self.langs = []
168 if form.has_key('lang'):
169 langdata = form['lang']
170 if type(langdata) == type([]):
171 for eachLang in langdata:
172 self.langs.append(eachLang.value)
173 else:
174 self.langs.append(langdata.value)
175 else:
176 self.error = 'At least one language required.'
177
178 if form.has_key('upfile'):
179 upfile = form["upfile"]
180 self.fn = upfile.filename or ''
181 if upfile.file:
182 self.fp = upfile.file
183 else:
184 self.fp = StringIO('(no data)')
185 else:
186 self.fp = StringIO('(no file)')
187 self.fn = ''
188
189 if not self.error:
190 self.doResults()
191 else:
192 self.showError()
193
194 if __name__ == '__main__':
195 page = AdvCGI()
196 page.go()
doResults()方法收集所有数据并把输出发回客户端。
Edit By Vheavens
Edit By Vheavens
146-196 行
脚本一开始就实例化了一个AdvCGI 页面对象,然后调用它的go()方法让一切运转起来,这和严
格的基于过程编写的程序不同。 go()方法中包含读取所有新到的数据并决定显示哪个页面的逻辑。
如果没有给出名字或选定语言,错误页面将会被显示。如果没有收到任何输入数据,将调用
showForm()方法来输出表单,否则将调用doResults()方法来显示结果页面。通过设置self.error
变量可以创建错误页面,这样做有两个目的。它不但可以让你把错误原因设置在字符串里,并且可
以作为一个标记表明有错误发生。如果该变量不为空,用户将会被导向到错误页面。
处理person 字段(第154-159 行)的方法和我们先前看到的一样,一个键-值对;然而,在收
集语言信息时却需要一点技巧,原因是我们必须检查一个(Mini)FieldStorage 对象或一个该对象
的列表。我们将使用熟悉的type()内建函数来达到目的。最终,我们会有一个单独或多个语言名的
列表,具体依赖于用户的选择情况。
使用cookie(第161-165 行)来保管数据展示了如何利用它们来避免使用任何类型的CGI 字段。
你一定注意到了代码里包含这些数据的地方没有调用CGI 处理,这意味着数据并非来自FieldStorage
对象。这些数据是由Web 客户端通过每一次请求和从cookie 取得的值(包括用户的选择结果和用来
填充后续表单的已有信息)传给我们的。
因为showResults()方法从客户那里取得了新的收入值,所以它负责设置cookie,通过调用
setCPPcookie()。而showForm()必须读出cookie 中的值才能用表单页显示用户的当前选项。这通
过它对getCPPcookie()的调用实现。
最后,我们看看文件上传处理(第178-187 行)。不论一个文件是否已经上传,FieldStorage 都
会从file 属性中获得一个文件句柄。在第180 行,如果没有指明文件名,那么我们只须把它设成空
字符串。如果访问过value 属性,那么文件的整个内容都会被放到value 里。还有一个更好的做法,
你可以去访问文件指针——file 属性——并且可以每次只读一行或者其他更慢一些的处理方法。
在我们的例子里,文件上传只是用户提交过程的一部分,所以我们可以简单的把文件指针传给
doResults()函数,从文件中抽取数据。由于空间限制doResults()将只显示文件的最前1K 内容,这
也表明显示一个4M 的二进制文件是不需要(或未必有效/有用)的。
20.8 Web(HTTP)服务器
到现在为止,我们已经讨论了如何使用Python 建立Web 客户端并用CGI 请求处理帮助Web 服务
器执行了一些工作。我们通过第20.2 和20.3 的学习知道了Python 可以用来建立简单和复杂的Web
客户端。而对复杂的CGI 请求没有说明。
然而,我们在这章的焦点是探索建立Web 服务器。如果说Firefox, Mozilla, IE, Opera,
Edit By Vheavens
Edit By Vheavens
Netscape, AOL, Safari, Camino, Epiphany, Galeon 和Lynx 浏览器是最流行的一些Web 客户
端,那么什么是最常用的Web 服务器呢?它们就是Apache,Netscape IIS, thttpd, Zeus,和Zope。
由于这些服务器都远远超过了你的应用程序要求,这里我们使用Python 建立简单但有用的Web 服务
器。
20.8.1 用Python 建立Web 服务器
由于已经打算建立这样的一个应用程序,你很自然的就需要创建个人素材,但是你将要用到的
所有的基础代码都在Python 的标准库中。要建立一个Web 服务,一个基本的服务器和一个“处理器”
是必备的。
基础的(Web)服务器是一个必备的模具。它的角色是在客户端和服务器端完成必要HTTP 交互。
在BaseHTTPServer 模块中你可以找到一个名叫HTTPServer 的服务器基本类。
处理器是一些处理主要“Web 服务”的简单软件。它们处理客户端的请求,并返回适当的文件,
静态的文本或者由CGI 生成的动态文件。处理器的复杂性决定了你的Web 服务器的复杂程度。Python
标准库提供了三种不同的处理器。
最基本,最普通的是 vanilla 处理器,被命名 BaseHTTPResquestHandler,这个可以在基本
Web 服务器的BaseHTTPServer 模块中找到。除了获得客户端的请求外,不再执行其他的处理工作,
因此你必须自己完成它们,这样就导致了出现了myhttpd.py 服务的出现。
用于SimpleHTTPServer 模块中的SimpleHTTPRequestHandler , 建立在
BaseHTTPResquestHandler 基础上,直接执行标准的GET 和HEAD 请求。这虽然还不算完美,但已经
可以完成一些简单的功能啦。
最后,我们来看下用于CGIHTTPServer 模块中的CGIHTTPRequestHandler 处理器,它可以获取
SimpleHTTPRequestHandler 并为POST 请求提供支持。它可以调用CGI 脚本完成请求处理过程,也可
以将生成的HTML 脚本返回给客户端。
这三个模块和他们的类在表20.6 中有描述。
为了能理解在SimpleHTTPServer 和CGIHTTPServer 模块中的其他高级处理器如何工作的,我们
将对BaseHTTPRequestHandler 实现简单的GET 处理功能。
Edit By Vheavens
Edit By Vheavens
Table 20.6 Web Server Modules and Classes
模块 描述
BaseHTTPServer 提供基本的Web 服务和处理器类, 分别是HTTPServer 和
BaseHTTPRequestHandler
SimpleHTTPServer 包含执行GET 和HEAD 请求的SimpleHTTPRequestHandler 类
CGIHTTPServer 包含处理POST 请求和执行CGICGIHTTPRequestHandler 类
--------------------------------------------
在例子20.9 中,我们展示了一个Web 服务器的全部工作代码, myhttpd.py.
这个服务的子类BaseHTTPRequestHandler 只包含do_GET()方法在基础服务器接到GET 请求时被
调用。
尝试打开客户端传来的路径,如果实现了,将会返回“OK”状态(200),并转发下载的Web 页
面,否则将会返回404 状态。
main()函数只是简单的将Web 服务器类实例化,然后启动它进入永不停息的服务循环,如果
遇到了^C 中断或者类似的键输入则会将其关闭。如果你可以访问并运行这个服务器,你就会发现它
会显示出一些类似这样的登录输出:
# myhttpd.py
Welcome to the machine... Press ^C once or twice to quit
localhost - - [26/Aug/2000 03:01:35] "GET /index.html HTTP/1.0" 200 -
localhost - - [26/Aug/2000 03:01:29] code 404, message File Not Found: /x.html localhost
- - [26/Aug/2000 03:01:29] "GET /dummy.html HTTP/1.0" 404 -
localhost - - [26/Aug/2000 03:02:03] "GET /hotlist.htm HTTP/1.0" 200 -
当然,我们的小Web 服务器是太简单了,它甚至不能处理普通的文本文件。我们将这部分给读
者,这部分可以在本章最后的练习题中找到。
正如你所看到的一样,建立一个Web 服务器并在纯Python 脚本中运行并不会花太多时间。为你
的特定应用程序定制改进处理器将需要做更多事情。请查看本部分的相关库来获得更多模块及其类
的信息。
--------------------------------------------
Example 20.9 Simple Web Server (myhttpd.py)
这个简单的Web 服务器可以读取GET 请求,获取Web 页面(.html 文件)并将其返回给客户端。
它通过使用BaseHTTPServer 的BaseHTTPRequestHandler 处理器执行do_GET()方法来处理GET 请求。
Edit By Vheavens
Edit By Vheavens
1 #!/usr/bin/env python
2
3 from os import curdir, sep
4 from BaseHTTPServer import \
5 BaseHTTPRequestHandler, HTTPServer
6
7 class MyHandler(BaseHTTPRequestHandler):
8
9 def do_GET(self):
10 try:
11 f = open(curdir + sep + self.path)
12 self.send_response(200)
13 self.send_header('Content-type',
14 'text/html')
15 self.end_headers()
16 self.wfile.write(f.read())
17 f.close()
18 except IOError:
19 self.send_error(404,
20 'File Not Found: %s' % self.path)
21
22 def main():
23 try:
24 server = HTTPServer(('', 80), MyHandler)
25 print 'Welcome to the machine...',
26 print 'Press ^C once or twice to quit.'
27 server.serve_forever()
28 except KeyboardInterrupt:
29 print '^C received, shutting down server'
30 server.socket.close()
31
32 if __name__ == '__main__':
33 main()















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









