







1,I/O及文件模式
I/O,是指数据的输入和输出。数据的输入和输出是相对于数据是从外部流向内存,还是从内存流向外部设备的过程。前者叫做数据的输入(input),后者叫做数据的输出(output)。
在打开一个文件的同时可以指定打开的模式,python中提供的文件模式有:
r -- 只读模式
w -- 只写模式
a -- 追加模式
b -- 以二进制模式打开文件,可以混用
+ -- 允许读/写模式,可以混用
2,文件基本操作:创建,写入,读取,删除,判断,清空文件,重命名,得到文件后缀名
文件对象的基本操作流程是:打开一个文件 ---> 操作文件 ---> 关闭文件
python 中的内置函数 open ,可以帮组我们实现打开一个文件并且返回可操作文件的资源句柄。
打开文件的时候,当文件不存在的时候需要先去创建它,在python中,当你采用“w”模式打开一个不存在的文件的时候,python会自动的为你去创建它,就像下面这样:
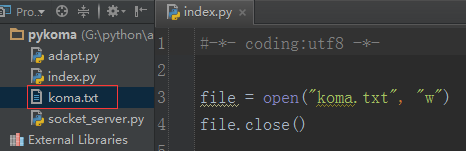
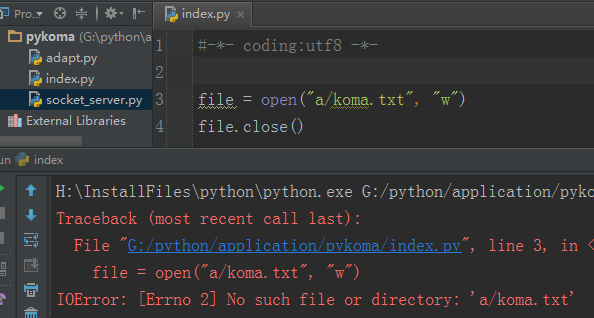
当然了,假如文件路径所对应的文件夹都不存在的话,这个时候python并不会帮你自动建立目录,而是直接报错:
当可以正确打开一个文件之后,我们就可以对文件进行一些操作,比如说向里面写一些东西,python中提供的向文件写入内容的方法有:write 函数 和 writelines 函数。
write:向文件中写入一个字符串,不包括换行符
writelines:向文件中写入多个字符串,writelines 接收一个可迭代的对象,例如列表、集合、字典等,同样 writelines 也不会向文件中自动写入换行符
当希望向文件中插入换行符的时候,需要借助于 os 模块中的 linesep 属性,该属性提供一个平台无关性的换行符。
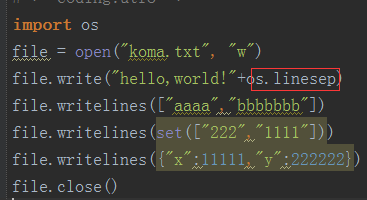
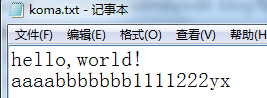
写入之后的效果如下:
当向文件中写入一定数据之后,就可以对文件进行读,python中提供的读取文件的方法有:
read:一次性把文件全部的内容读取到内存中,适用于读取小文件
readline:读取文件内容中的一行,一行以读到换行符或者文件尾结束
readlines:读取文件中的所有行,并将行内容构建成一个 list 返回
当然了,在读文件的时候,那么相应的,文件的打开模式就要变成“r”:

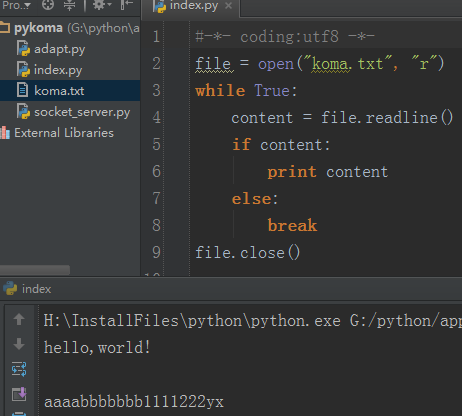
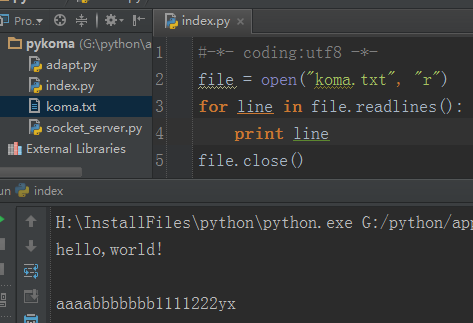
清空文件内容的方法有很多,你可以用“w”模式打开文件,然后什么都不做的再 close 掉,那么文件里面的内容就被清空了,这个也就是“w”模式和“a”模式的区别。那么我这里采用的是通过文件对象的方法:truncate 来清空一个文件,举例如下:
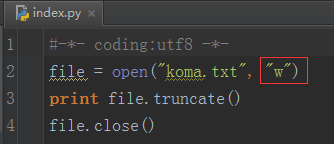
注意:这里打开文件的模式一定要变成“w”模式,否则会报错!
清空了这个文件,或许它就没什么用了,这个时候我们可以用 os 模块下的 remove 方法,来删除一个文件:
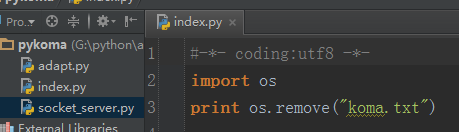
那同样的,当需要对一个文件重命名的时候就可以调用 os 模块下的 rename 方法,这里不做演示。
最后,我们来看怎么判断给定的一个文件是否存在,以及如何获取该文件的后缀名,这个可是常用的操作:
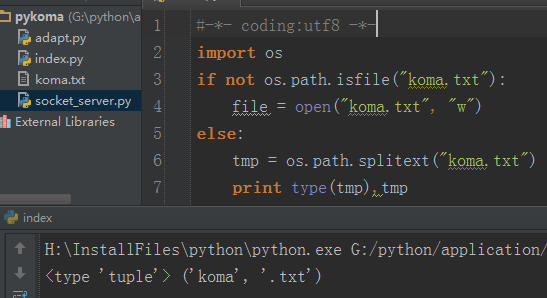
当第一次运行上面的代码的时候,因为文件不存在,因此 open 函数会创建对应的文件,当第二次运行的时候,文件已经存在,那么就可以得到文件的后缀名信息。
3,文件数据编码问题
上面案例的整个操作,我们都没有涉及到中文字符,那么假如现在有一个文本文件里面含有中文,那么当采用上面的方法读取出文件内容的时候会是什么样子的呢?请看下面的案例。
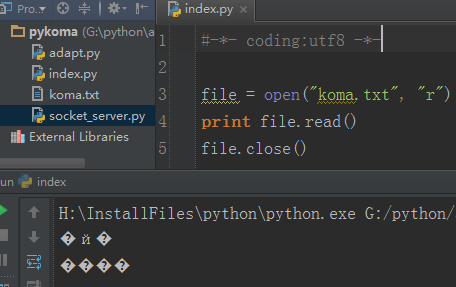
你看,是不是不出意外的就出现了数据乱码的问题呢?那么,乱码是由什么引起的,这个得清楚!
首先,在 python 中,如果你不显式的声明采用的是 unicode 编码,那么默认全部采用的是 ASCII 编码。另外,被打开文件本身的编码是 gbk 编码格式,而我们在编辑器中则声明的是 utf8 编码,这样编码的方式不统一也会出现乱码问题!
那么搞清楚了编码问题产生的原因,问题自然也就好解决了。因为读取出来的数据编码是 gbk 的,而我们则是用 utf8 编码来展示,因此我们需要对读取出来的数据进行重新编码,变成 gbk:
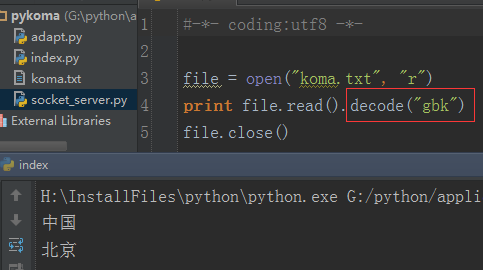
那么,读取数据的编码问题解决之后,对于写数据的编码问题则可以按照同样的思路来解决,如下:
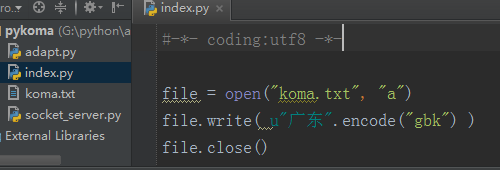
4,文件夹操作
学会了上面的对文件的操作,那么对于文件夹的操作则相对简单一些,因为对于所有的文件夹操作的函数基本上都包含了在 os 和 os.path 模块中,下面我以一个简单的例子做个演示。
案例一:列出指定目录下的所有文件夹及文件名称

可以看到,列出指定目录下的函数使用的是 listdir,判断一个路径是否是文件夹使用的是 isdir。同样的创建一个文件夹的函数有 mkdir 和 makedirs ,前者只能创建单层文件夹,而后者则可以创建嵌套的多层文件夹,那么其它的一些文件夹操作函数,在 os 模块或者 os.path 模块中你都可以自行找到它们并去尝试一下!
5,数据序列化
数据的序列化是为了方便后期数据的保存或者在网络上进行传输。python 提供的数据序列化的模块有 pickle 和 cPickle,以及 json 模块。其中 pickle 和 cPickle 的区别在于,前者使用的是纯python语言编写,速度较慢,而后者则是采用的 C 语言编写,速度较快。pickle 和 cPickle 与 json 模块的区别在于,前两者属于 python 语言特有的数据序列号方式,并不通用,而 json 则是把数据序列化成 json 格式字符串,以便通用。
以上三个模块均提供 dump 和 dumps 分别把数据序列化成“类文件对象”和字符串,同样的也提供 load 和 loads 分布把序列化后的数据反序列化成 “类文件对象”和 python 对象。
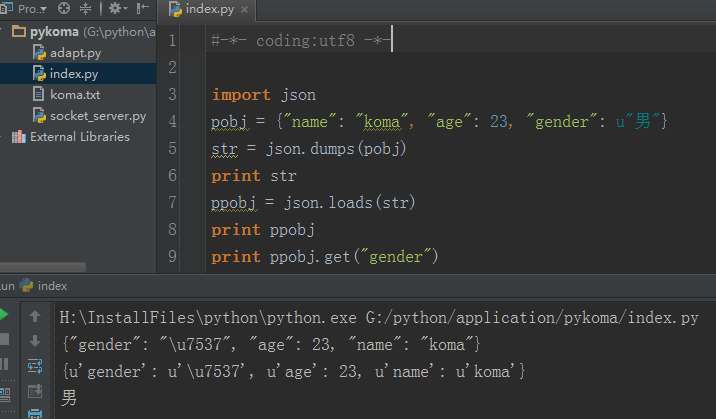
下面,我们用 json 模块做一个简单的示例:
------------------------------------------哈!我又回来了!-------------------------------------------------
我为什么不直接传代码而截图呢?















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









