







当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常需要过滤输出以得到感兴趣的部分。这时正则表达式就派上用场了。
什么是正则表达式?
正则表达式可以定义为代表若干个字符序列的字符串。它最重要的功能之一就是它允许你过滤一条命令或一个文件的输出、编辑文本或配置文件的一部分等等。
正则表达式的特点
正则表达式由以下内容组合而成:
- 普通字符,例如空格、下划线、A-Z、a-z、0-9。
- 可以扩展为普通字符的元字符,它们包括:
- (.) 它匹配除了换行符外的任何单个字符。
- (*) 它匹配零个或多个在其之前紧挨着的字符。
- [ character(s) ] 它匹配任何由其中的字符/字符集指定的字符,你可以使用连字符(-)代表字符区间,例如 [a-f]、[1-5]等。
- ^ 它匹配文件中一行的开头。
- $ 它匹配文件中一行的结尾。
- / 这是一个转义字符。
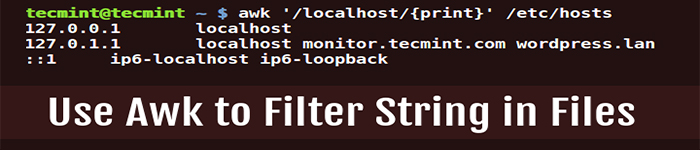
你必须使用类似 awk 这样的文本过滤工具来过滤文本。你还可以把 awk 自身当作一个编程语言。但由于这个指南的适用范围是关于使用 awk 的,我会按照一个简单的命令行过滤工具来介绍它。
awk 的一般语法如下:
# awk 'script' filename
此处 'script' 是一个由 awk 可以理解并应用于 filename 的命令集合。
它通过读取文件中的给定行,复制该行的内容并在该行上执行脚本的方式工作。这个过程会在该文件中的所有行上重复。
该脚本 'script' 中内容的格式是 '/patter
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









