







 本文展示了如何使用Spring Batch将CSV文件内容读取并导入到MySQL数据库中,涵盖了作业分块、CSV读取、数据处理、数据库写入及Spring Batch的弹性处理特性,包括跳过错误项、重试和重启作业。
本文展示了如何使用Spring Batch将CSV文件内容读取并导入到MySQL数据库中,涵盖了作业分块、CSV读取、数据处理、数据库写入及Spring Batch的弹性处理特性,包括跳过错误项、重试和重启作业。
Spring Batch示例: 读取CSV文件并写入MySQL数据库
GitHub版本: https://github.com/kimmking/SpringBatchReferenceCN/blob/master/01_introduction/Spring_Batch_MySQL.md
原文链接: Reading and writing CVS files with Spring Batch and MySQL
原文作者: Steven Haines - 技术架构师
下载本教程的源代码:
SpringBatch-CSV演示代码
用批处理程序来操作动辄上GB的数据很可能会拖死整个系统,但现在我们可以通过Spring Batch将其拆解为多个小块(chunk)。Spring框架中的 Spring Batch 模块, 是专门设计了用来对各种类型文件进行批处理的工程。 本文先从一个简单的作业(Job)入手 —— 将从CSV文件中读取产品列表,并导入到MySQL数据库中; 然后我们一起研究 Spring Batch 的批处理特性: 如单/多处理单元(processors), 以及多个微线程(tasklets); 最后简单介绍一下 Spring Batch 提供的用来处理 忽略记录(skipping), 重试记录(retrying),以及批处理作业重启(restarting ) 的弹性工具(resiliency tools)。
如果你曾在Java企业系统中用批处理来处理过十万级以上的数据, 那么你肯定知道工作负载是怎么回事。 批处理系统需要处理大量的数据, 内部消化单条记录失败的情况, 还要管理中断,在重启后也不去重复执行已经处理过的部分。
对于初学者来说,下面是一些需要用到批处理的场景, 在这些情况下如果使用Spring Batch ,则会节省大量的时间:
- 接收的文件中缺少了一部分汇总信息,需要读取并解析整个文件,调用服务来获取缺少的那部分信息,然后写入输出文件,供另一个批处理程序使用。
- 如果在执行代码时发生错误,则将失败信息写入数据库中。 有一个专门的程序每隔15分钟来遍历一次失败信息,如果标记为可以重试,则完成后再重复执行一次。
- 在工作流中,约定由其他系统在收到消息事件时,来调用某个特定的服务。 但如果其他系统没有调用这个服务,那么一段时间后需要自动清理过期数据,以免影响正常的业务流程。
- 每天收到员工信息更新文件,需要为新员工建立相关档案和账号(artifacts)。
- 生成自定义订单的服务。 每天晚上需要执行批处理程序来生成清单文件,并将它们发送给相应的供应商。
作业与分块: Spring Batch 范例
Spring Batch 有很多组成部分,我们先来看批量作业中的核心部分。 可以将一个作业分成以下3个步骤:
- 读取数据
- 对数据进行各种处理
- 对数据进行写操作
例如, 打开一个CSV格式的数据文件,对文件中的数据执行某种处理,然后将数据写入数据库。 在Spring Batch中, 需要配置一个 reader 来读取文件中的数据(每次一行), 然后将数据传递给 processor 进行处理, 处理完成之后会将结果收集并分组为 “块 chunks” , 然后把这些记录发送给 writer ,在这里是插入到数据库中。 如图1所示。
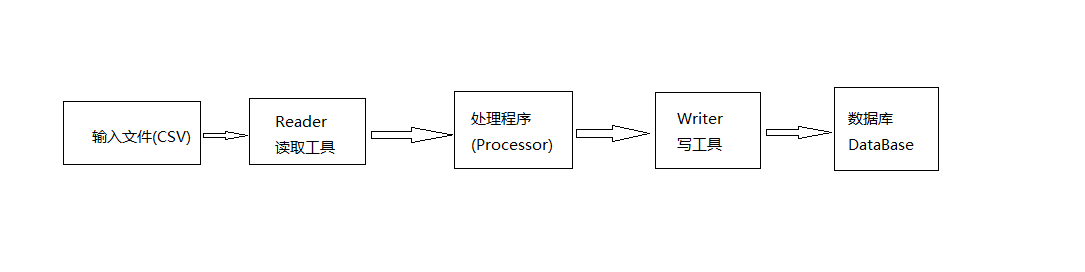
图1 Spring Batch批处理的基本逻辑
Spring Batch 提供了常见输入源的 reader 实现, 极大地简化了批处理过程. 例如 CSV文件, XML文件、数据库、文件中的JSON记录,甚至是 JMS; 同样也实现了对应的 writer。 如有需要,创建自定义的 reader 和 writer 也很简单。
下载本教程的源代码:
SpringBatch-CSV演示代码
首先,让我们配置一个 file reader 来读取 CSV文件,将其内容映射到一个对象中,并将生成的对象插入数据库中。
读取并处理CVS文件
Spring Batch 的内置 reader, org.springframework.batch.item.file.FlatFileItemReader,用来将文件解析为多个独立的行。 需要纯文本文件的引用,文件开头要忽略的行数(比如标题,表头等信息), 以及将单行转换为对象的 line mapper. 行映射器需要一个分割字符串的分词器(line tokenizer),用来将一行拆分成多个组成字段, 还需要一个 field set mapper ,根据字段值构建对象。 FlatFileItemReader 的配置如下所示:
清单1 一个Spring Batch 配置文件
<bean id="productReader" class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<!-- <property name="resource" value="file:./sample.csv" /> -->
<property name="resource" value="file:#{jobParameters['inputFile']}" />
<property name="linesToSkip" value="1" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names" value="id,name,description,quantity" />
</bean>
</property>
<property name="fieldSetMapper">
<bean class="com.geekcap.javaworld.springbatchexample.simple.reader.ProductFieldSetMapper" />
</property>
</bean>
</property>
</bean>
下面来看看这些组件。 图2概括了它们之间的关系:
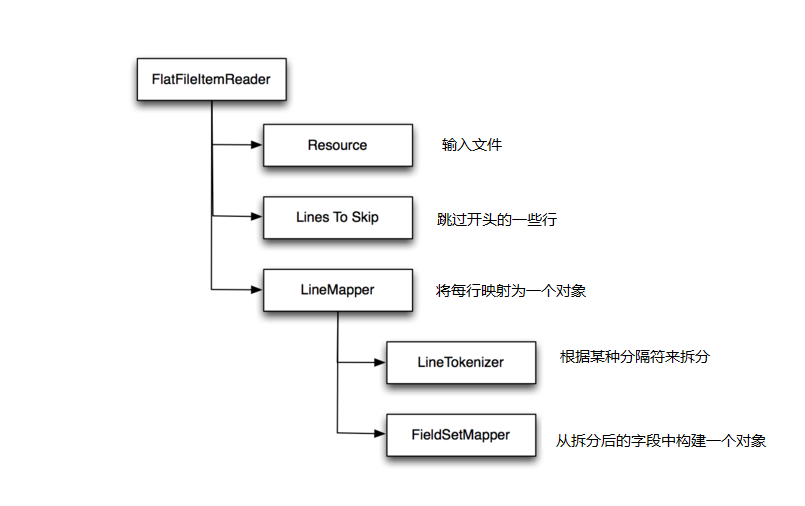
图2 FlatFileItemReader的组件
Resources: resource 属性指定了要读取的文件。 注释部分的 resource 使用了文件的相对路径,也就是批处理作业工作目录下的 sample.csv 。 有趣的是使用了Job参数 InputFile : 使用job parameters 则允许在运行时才根据需要决定相关参数。 在使用 import 文件的情况下, 在运行时才决定使用哪个参数比起在编译时就固定要灵活好用很多。 (要一遍又一遍,五六七八遍导入同一个文件是相当无聊的!)
Lines to skip: 属性linesToSkip 告诉 file reader 有多少标题行需要跳过。 通常CSV文件的第一行包含标题信息,如列名称,所以本例中让 reader 跳过文件的第一行。
Line mapper: lineMapper 负责将一行记录转换为一个对象。 依赖两个组件:
-
LineTokenizer指定了如何将一行拆分为多个字段。 本例中列出了CSV文件中各列的列名。 -
fieldSetMapper根据字段值构造一个对象。 示例中构建了一个Product对象, 属性包括 id, name, description, 以及 quantity 。
请注意,虽然Spring Batch提供了基础框架, 但我们仍需要设置字段映射的逻辑。 清单2显示了 Product 对象的源码,也就是我们准备构建的对象。
清单2 Product.java
package com.geekcap.javaworld.springbatchexample.simple.model;
/**
* 代表产品的简单值对象(POJO)
*/
public class Product
{
private int id;
private String name;
private String description;
private int quantity;
public Product() {
}
public Product(int id, String name, String description, int quantity) {
this.id = id;
this.name = name;
this.description = description;
this.quantity = quantity;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public int getQuantity() {
return quantity;
}
public void setQuantity(int quantity) {
this.quantity = quantity;
}
}
Product 类是一个简单的POJO,包含4个字段。 清单3显示了 ProductFieldSetMapper 类的源代码。
清单3 ProductFieldSetMapper.java
package com.geekcap.javaworld.springbatchexample.simple.reader;
import com.geekcap.javaworld.springbatchexample.simple.model.Product;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
/**
* 根据 CSV 文件中的字段集合构建 Product 对象
*/
public class ProductFieldSetMapper implements FieldSetMapper<Product>
{
@Override
public Product mapFieldSet(FieldSet fieldSet) throws BindException {
Product product = new Product();
product.setId( fieldSet.readInt( "id" ) );
product.setName( fieldSet.readString( "name" ) );
product.setDescription( fieldSet.readString( "description" ) );
product.setQuantity( fieldSet.readInt( "quantity" ) );
return product;
}
}
ProductFieldSetMapper 类实现了 FieldSetMapper 接口 ,该接口只定义了一个方法: mapFieldSet(). 只要 line mapper 将一行数据解析为单独的字段, 就会构建一个 FieldSet(包含命名好的字段), 然后将这个 FieldSet 对象传递给 mapFieldSet() 方法。 该方法负责创建对象来表示 CSV文件中的一行。 在本例中,我们通过 FieldSet 的各种 read 方法 构建一个 Product 实例.
写入数据库
在读取文件得到一组 Product 之后 ,下一步就是将其写入到数据库。 原则上我们可以组装一个 processing step,用来对这些数据进行某些业务处理,为简单起见,我们直接将数据写到数据库中。 清单4是 ProductItemWriter 类的源码。
清单4
ProductItemWriter.java
package com.geekcap.javaworld.springbatchexample.simple.writer;
import com.geekcap.javaworld.springbatchexample.simple.model.Product;
import org.springframework.batch.item.ItemWriter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
/**
* Writes products to a database
*/
public class ProductItemWriter implements ItemWriter<Product>
{
private static final String GET_PRODUCT = "select * from PRODUCT where id = ?";
private static final String INSERT_PRODUCT = "insert into PRODUCT (id,name,description,quantity) values (?,?,?,?)";
private static final String UPDATE_PRODUCT = "update PRODUCT set name = ?, description = ?,quantity = ? where id = ?";
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public void write(List<? extends Product> products) throws Exception
{
for( Product product : products )
{
List<Product> productList = jdbcTemplate.query(GET_PRODUCT, new Object[] {product.getId()}, new RowMapper<Product>() {
@Override
public Product mapRow( ResultSet resultSet, int rowNum ) throws SQLException {
Product p = new Product();
p.setId( resultSet.getInt( 1 ) );
p.setName( resultSet.getString( 2 ) );
p.setDescription( resultSet.getString( 3 ) );
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









