







今天,介绍一种特别简单的机器学习算法,叫K-临近法,英文k-nearest neighbors,简称KNN。
在介绍算法之前,我们先举一个案例。等案例讲完后,看看我们怎么用K-临近法去解决这个案例中的问题。
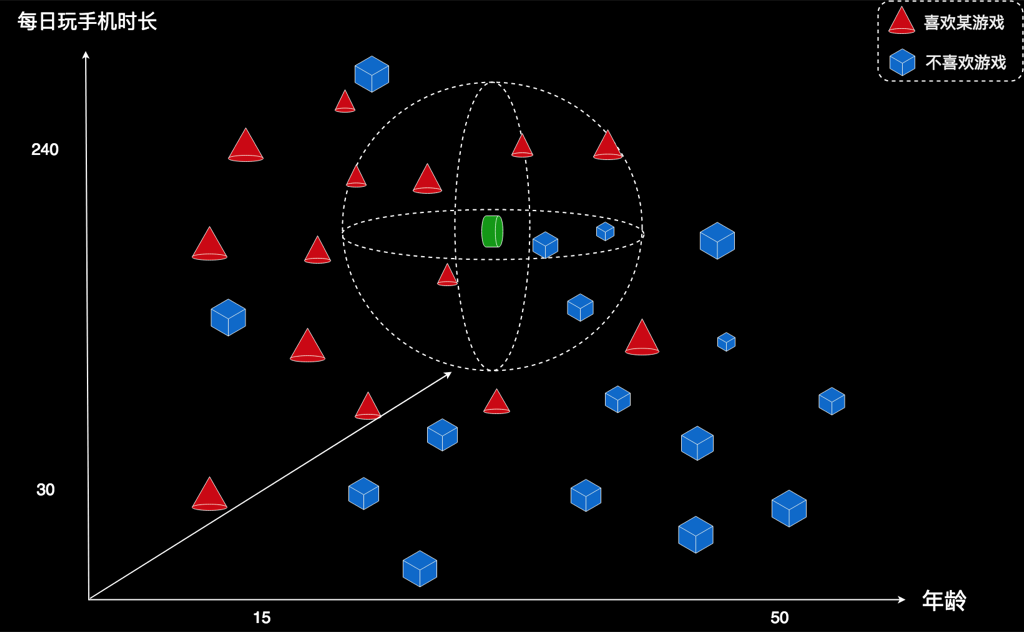
有一个游戏公司,他们开发了一款游戏。这款游戏发布了一段时间后,他们得到了一些用户的数据。数据如面这幅图所示:
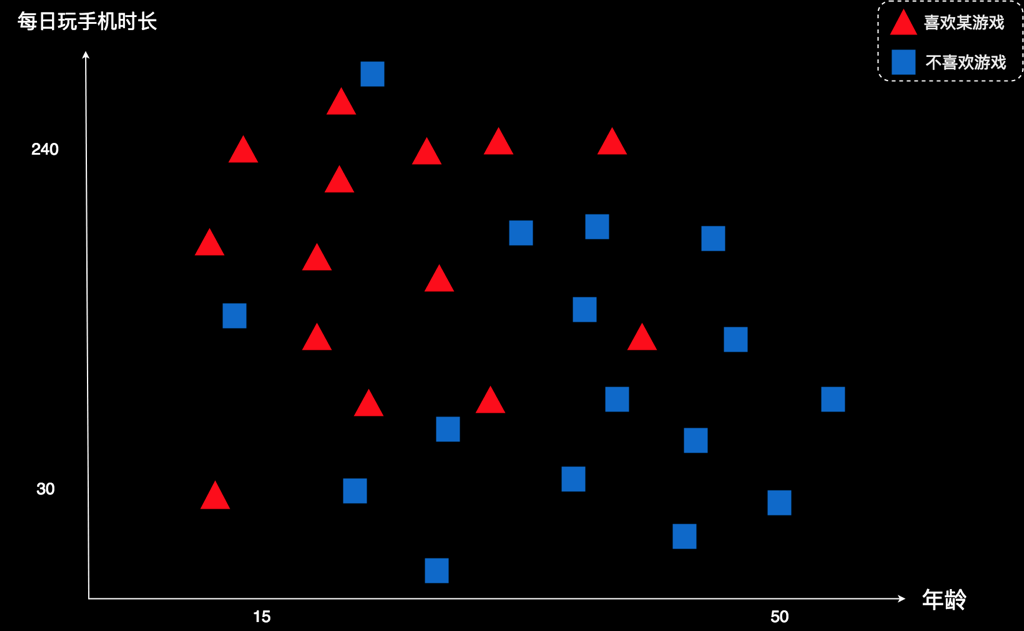
这个图上的每一个图形表示一个用户。红色的三角形表示该用户喜欢这款游戏;蓝色的正方形表示该用户不喜欢这款游戏。图上有2个坐标。横坐标表示用户的年龄,纵坐标表示用户平均每天玩手机的时长,单位是分钟。
比如,右下角这个蓝色方框。这个用户的年龄大概50岁,TA每天平均玩手机的时间30分钟左右。这个图形是蓝色,表示他不喜欢这款游戏。再比如左上角的红色三角形。这个用户的年龄不到15岁,每天玩手机时间240分钟,也就是4个小时。这个图形是红色,表示他喜欢这款游戏。其它用户也是一样等逻辑。
这些都是已知用户的数据。现在,他们从某些渠道获得了一批新用户。比如,有一个用户,在图上表示为绿色的圆点。这个用户大概30岁,每天玩手机时长有200分钟左右。
公司想知道,他们是否应该向这个用户推广这款游戏?
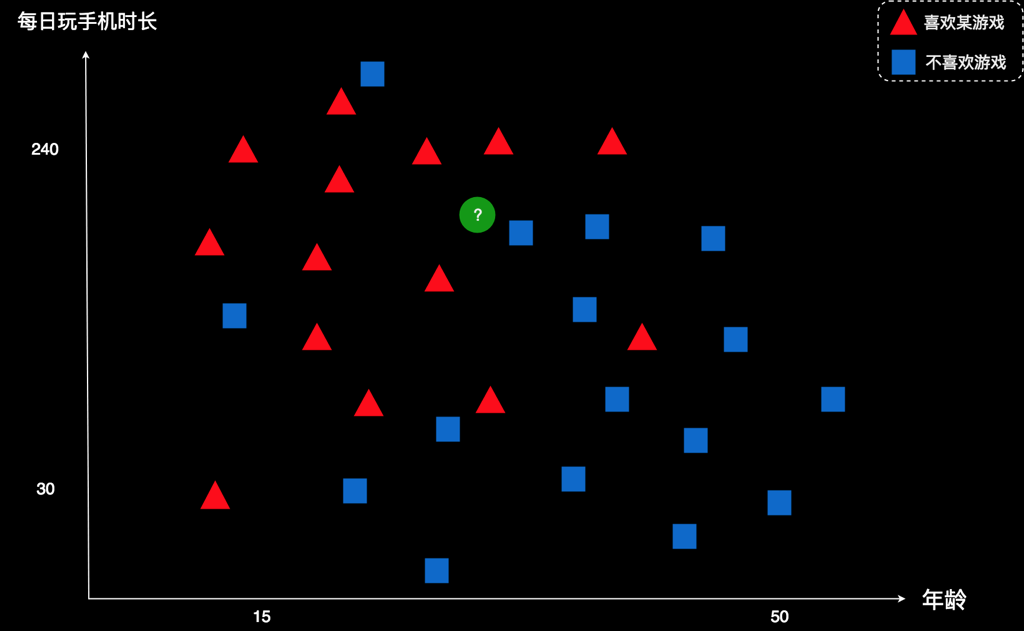
需要说明一下,推广游戏是有成本的,需要花费一定的推广费用。所以,只有推广给那些喜欢这款游戏的人,公司才能获取收益。
于是,刚才那个问题就转换成为:预测这个绿色的新用户是否喜欢这款游戏。
那如何预测呢?
这里我们需要一个假设:属性越接近的人,行为偏好也越相似。
比如,两个20多岁的人,他们的行为偏好可能比较相似;而一个20多岁和一个50多岁的人,他们的行为偏好就会相差比较大。也就是说,年龄这个属性越接近,行为偏好也就越相似。
再比如,两个工程师,他们的行为偏好可能就比较相似。而一个工程师和一个演员,他们的行为偏好就会相差比较大。也就是说,行业这个属性越接近,行为偏好也就越相似。
推广一下,就是属性越接近的人,行为偏好也越相似。这跟我们常说的“物以类聚、人以群分”是一个道理。
回到我们的案例。要想知道绿色的用户跟那一类用户更相似,我们可以比较他跟哪些人的属性更接近。或者反过来说,跟他接近的人有哪些?
我们发现,“接近”是一个距离的概念。在二维平面图上,就是指哪些图形距离这个绿色圆点比较短。
我们要判断新用户(绿色圆点)喜欢不喜欢这款游戏,就是判断这个点应该属于红色还是应该属于蓝色。根据上面的假设,我们可以先找到跟他属性接近的图形,也就是它的邻居。看看它的邻居都是什么类型的。如果邻居都是红色,根据物以类聚的原则,它大概率也是红色。如果邻居都是蓝色,它大概率也就是蓝色。
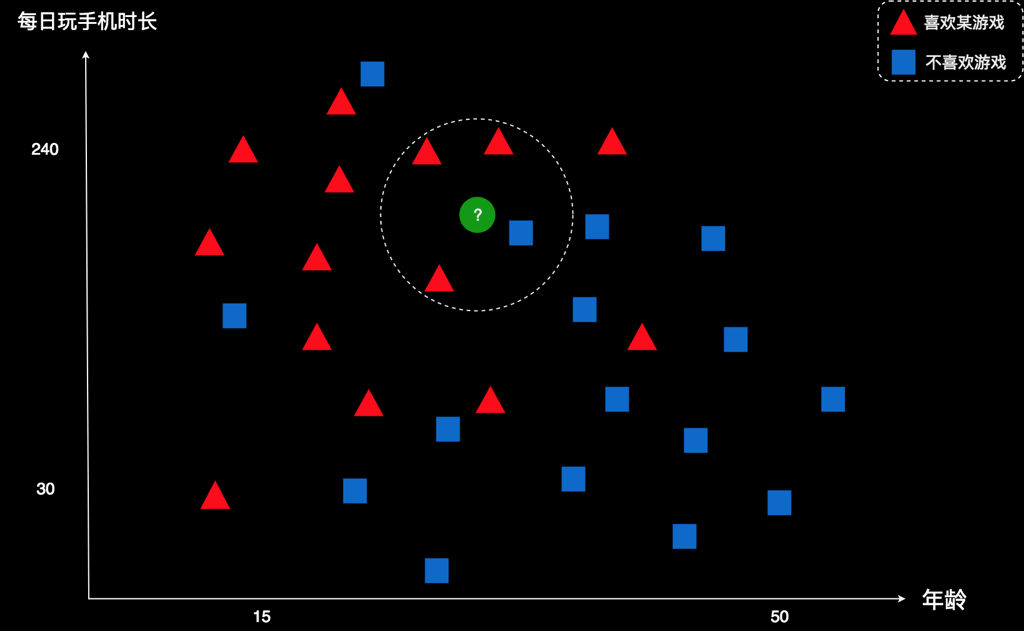
那选几个邻居比较合适呢?这个数由我们自己定,我们可以选任意K个邻居,K是个整数。这就是K临近法的含义。
比如,我们选4个最近邻居。发现四个邻居有3个是红色,只有一个蓝色。邻居中红色占多数,我们就可以判断,这个新用户也大概也是红色。物以类聚嘛!他是红色就表示他喜欢这款游戏,因此这家公司应该给他推荐这款游戏。
我们还可以扩大一下邻居的范围,比如找8个邻居。这时发现5个红色,3个蓝色。还是红色邻居多,因此我们仍然判断这个用户是红色。
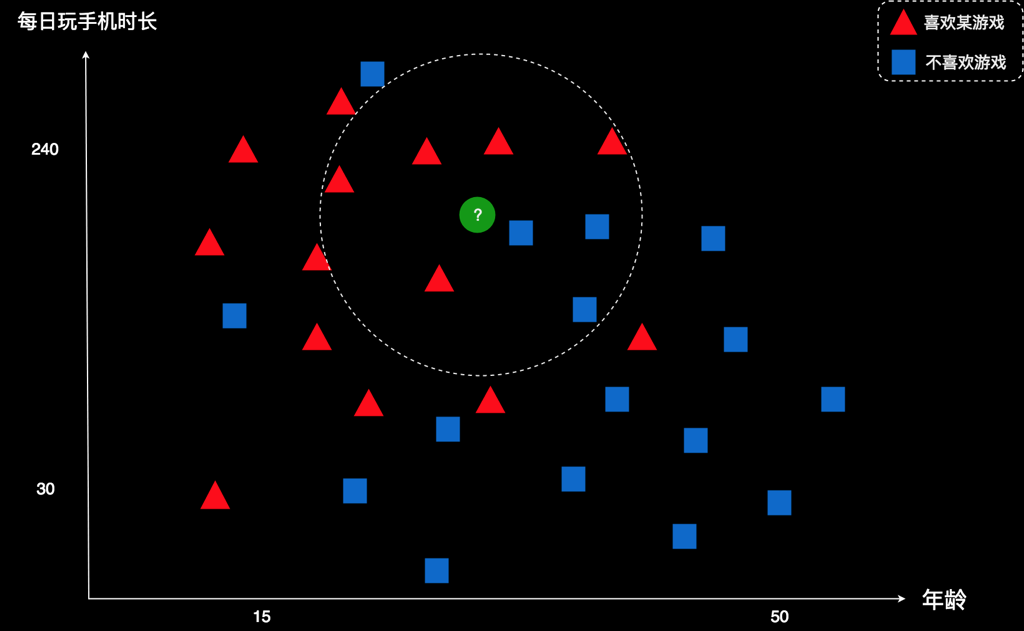
不过,并不是任意选几个邻居都能得出相同的结论。比如我们选1个邻居。这时就会发现,这个邻居是蓝色,因此结论应该是该用户为蓝色。与之前的结论不一样!

理论上讲,选的邻居越多越好。不过,太多的话,计算量大,算起来也就会慢。通常我们需要根据实际情况选择合适的K值,既使得结论比较合理,同时计算量也不会太大。
到此为止,K临近法的主要原理就介绍完了。
不过,有心的同学可能会发现一个问题。我们的图只有两个属性:“年龄”和“每天玩手机的时长”。如果有三个属性怎么办?比如,我们还有一个属性是“学历”。该怎么表达呢?
其实,三个属性可以用三维的空间表示,x、y、z三个坐标。每一个坐标代表一个属性。一个点的邻居,就是它在三维空间中离它最近的那些点。三维空间中两点的距离,其计算方法与二维平面两点距离是类似的。
如果有4个属性,那就是4维空间表示。有N个属性,就用N维空间表示。我们可能无法想象出高维空间是什么样子大,不过高维空间中两个点的距离,其计算方法与二维、三维中的距离计算方法是类似的。
因此,不管有多少个属性,K临近法都可以用相同的计算方法。
今天我们介绍了一个游戏公司的案例,案例中的公司要判断是否应该给新用户推广某一款游戏,然后用K临近法解决了这个问题。
你觉得K临近法还可以解决哪些问题?如果你有想法,可以写到评论里。
相关文章:















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









