







7. HashSet
底层数据结构是哈希表(元素是链表的数组)
关于这个结构,我觉得有必要用一张图来解释:
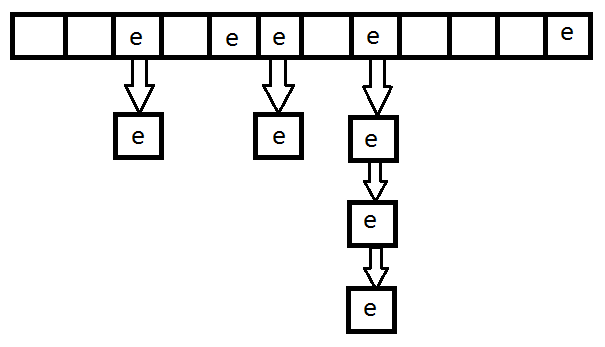
哈希表是一个数组,当一个数据(对象)要添加时,先计算对象的hashCode,来确定它应该对应数组的哪个位置,如果那个位置没有数据,则该元素放到对应位置上;如果有数据,则继续调用该对象的equals方法,与该位置的已有数据对比,如果返回true,则HashSet认为这两个数据是一样的,就不允许添加;如果返回false,则在原位置以链表的形式继续向下连接该要添加的数据。
所以说,哈希表依赖于哈希值存储,也就是对象的hashCode方法
HashSet的特性:
HashSet不保证迭代的插入顺序性,特别是不保证每次迭代的顺序一致。
比方说下面这段代码,我们做一个String的Set集合,看看每次输出的结果:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("嘿嘿");
set.add("呵呵");
set.add("嗯呐");
set.add("哈哈");
set.add("好的");
set.add("呼呼");
System.out.println(set);
}
}
//运行结果
//[嘿嘿, 呵呵, 哈哈, 呼呼, 嗯呐, 好的]跟add的顺序果然不一样。。。
但所谓的迭代顺序不确定,并不是几次试验就可以试验出来的,这取决于对象的hashCode和equals,还有哈希表的内部结构。更深入的了解,戳:“不保证有序”和“保证无序”
既然基本数据的包装类可以,我们来试试自己写的自定义实体类吧:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person(1, "辣条"));
set.add(new Person(3, "冰棍"));
set.add(new Person(4, "面包"));
set.add(new Person(2, "薯片"));
set.add(new Person(2, "薯片"));
set.add(new Person(2, "薯片"));
for (Person person : set) {
System.out.println(person);
}
}
}
class Person {
private int id;
private String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + "]";
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}运行之后出现了下图的异常情况:
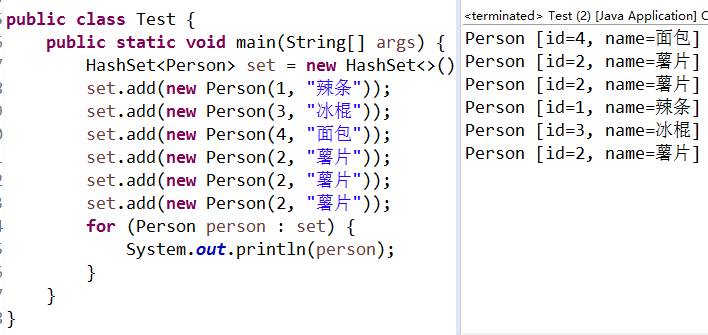
出现异常情况的原因:
添加功能底层依赖两个方法:
int hashCode()
boolean equals(Object obj)
那我们给Person类重写hashCode方法,存储Person:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person(1, "辣条"));
set.add(new Person(3, "冰棍"));
set.add(new Person(4, "面包"));
set.add(new Person(2, "薯片"));
set.add(new Person(2, "薯片"));
set.add(new Person(2, "薯片"));
for (Person person : set) {
System.out.println(person);
}
}
}
class Person {
private int id;
private String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
return result;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}运行之后:
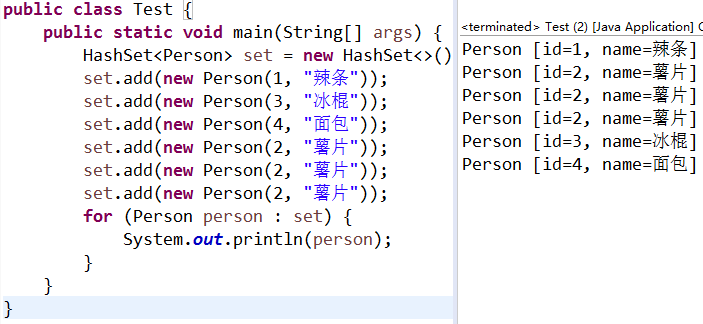
发现仍然异常,但似乎我们有了一个意外收获:竟然以id为排序规则,升序排序了?
注意:这或许是巧合!但我们可以感觉到另外一个重点:3个id=2在一起了,这也就恰恰跟刚才的数组+链表结构呼应上了!
最后我们给Person类重写equals方法,存储Person:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person(1, "辣条"));
set.add(new Person(3, "冰棍"));
set.add(new Person(4, "面包"));
set.add(new Person(2, "薯片"));
set.add(new Person(2, "薯片"));
set.add(new Person(2, "薯片"));
for (Person person : set) {
System.out.println(person);
}
}
}
class Person {
private int id;
private String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (id != other.id)
return false;
return true;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}运行结果:
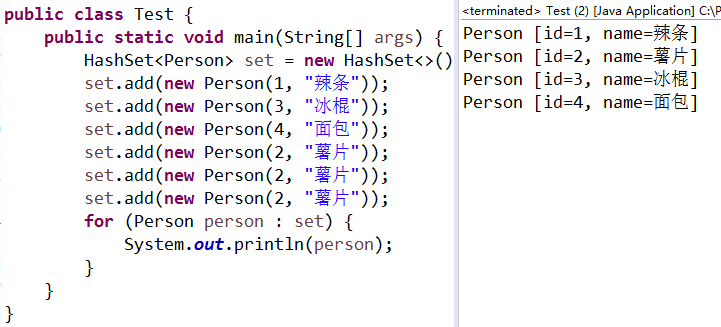
完全正常!这也就说明了为什么自定义的实体类必须要重写hashCode和equals方法!
HashSet的插入原理:
当你试图把对象加入HashSet时,HashSet会使用对象的hashCode来判断对象加入的位置。
同时也会与其他已经加入的对象的hashCode进行比较,如果没有相等的hashCode,HashSet就会假设对象没有重复出现。
如果元素(对象)的hashCode值相同,并不会立即存入,而是会继续使用equals进行比较。
如果equals为true,那么HashSet认为新加入的对象重复了,所以加入失败。
如果equals为false,那么HashSet认为新加入的对象没有重复,新元素可以存入。
HashSet与List都有contains方法,List接口的实现全部使用equals,而HashSet先使用hashCode,再使用equals
---------------------------多唠几句--------------------------------
如果有兴趣去扒源码,会发现HashSet其实是利用了HashMap的键来做的。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>(); // 这里new了一个HashMap
}另一个可以解释的位置在iterator方法里:
/**
* Returns an iterator over the elements in this set. The elements
* are returned in no particular order.
*
* @return an Iterator over the elements in this set
* @see ConcurrentModificationException
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}返回的竟然是map.keySet()的iterator????(黑人问号.jpg)















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









