







目录
一,一个例子
public static void test1() {
Order o1 = new Order();
o1.setId(1);
Order o2 = new Order();
o2.setId(2);
Order o3 = new Order();
o3.setId(3);
Order o4 = new Order();
o4.setId(2);
Set<Order> set = new HashSet<>();
set.add(o1);
set.add(o2);
set.add(o3);
set.add(o4);
System.out.println("size:" + set.size()); //添加四个元素
o2.setId(10); //修改hash值
set.remove(o2); //删除o2
System.out.println("size:" + set.size());
set.add(o2); //重新添加o2
System.out.println("size:" + set.size());
}其中Order类的hashCode()方法,改成以id为准:
@Override
public int hashCode() {
return id;
}此案例输出的结果是:
size:3
size:3
size:4
可见,o2的hash值从2改成10后,remove()方法没能把o2元素删除,甚至后面还能把o2再次添加到set中。
下面分析一下原因
因为HashSet底层是由HashMap实现的,其中key是我们指定的对象,value是HashSet自定义的一个类,不用关注,所以我们可以直接研究HashMap的remove()方法。
二,一些基础知识
1,HashMap用拉链法保存元素,维护了一个数组,保存各个节点链表的头节点,初始长度是16,根据元素hash值决定属于哪个链表。
2,HashMap根据元素hash值决定元素在哪个链表,算法是:(n-1)&hash。其中n是数组长度,hash是元素Hash值,得到的结果就是HashMap中数组的下标,也就决定了元素属于哪个链表。这个算法说白了就是元素Hash值除以数组长度(注意不是除以数组长度减一)然后取余。
2,节点由Node类实现,这是HashMap中的内部类,有以下四个参数:
- final int hash; 节点hash值
- final K key; 节点的key
- V value; 节点的value
- Node<K,V> next; 该节点的下一节点
3,当HashSet使用HashMap实现时,指定元素将保存在Node的key中,而value是HashSet自定义的一个对象。
4,当已经添加到HashMap中的对象改变了hash值后,不会改变它在HashMap中的位置,此时元素的Hash值和节点的Hash值会不同。
因此,在上面的例子中,o2对象修改Hash值前后的HashMap结构如下:
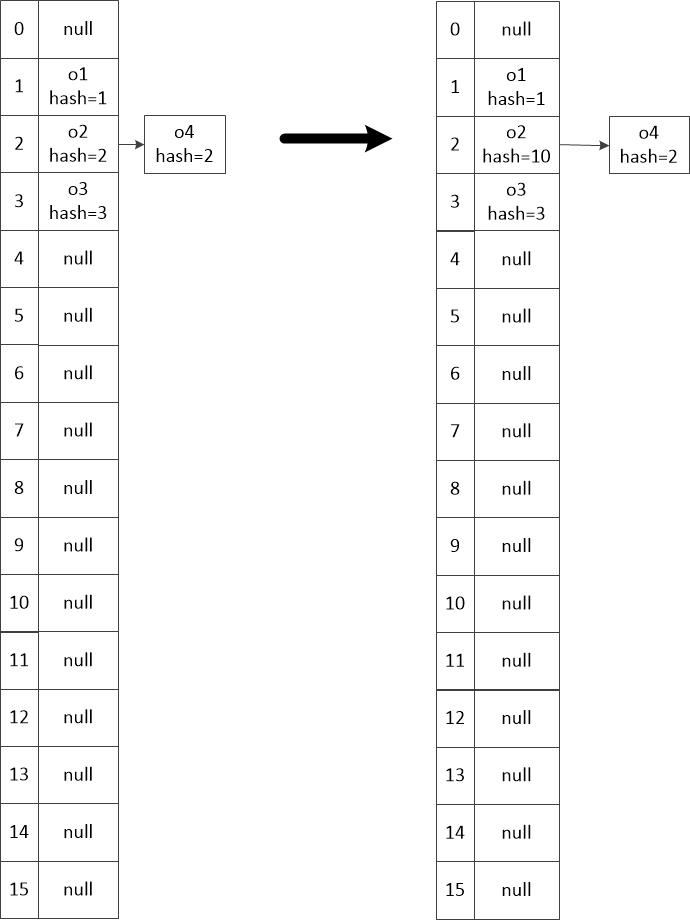
可见,在修改前,下标为2的链表节点中都是hash值除以16(数组长度)余2的节点,修改o2的hash值后,o2节点依然在原来的位置,节点Hash值依然是2,但o2的Hash值已经变成10了。
三,HashMap的remove()方法
下面准备开始执行remove()方法,看一下HashMap的remove()方法代码:
@Override
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}调用了removeNode()方法:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}方法先是定义了一堆的变量:
Node<K,V>[] tab; Node<K,V> p; int n, index;然后进行了一个让人眼花缭乱的if判断:
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {这种边赋值边判断的写法真是不想让我们好好读代码了。
拆解一下。
第一步:
(tab = table) != nulltable是HashMap维护的那个数组,保存链表头结点,赋值给tab。如果table都是null那肯定没什么可remove的,方法直接返回null。
第二步:
(n = tab.length) > 0tab.length是数组长度,赋值给n。如果数组长度是0那也没什么可remove的,方法直接返回null。
第三步:
(p = tab[index = (n - 1) & hash]) != null其中hash是要remove元素的Hash值,n前面说了是数组长度。
(n - 1) & hash的位运算实际上就是HashMap确认元素属于哪个链表的算法,也就是Hash值除以数组长度取余,得到的是数组下标。
得到的数组下标赋值给index。
tab[index]就是数组对应位置链表的头节点,赋值给节点对象p。
如果p==null,则说明Hash值在对应位置的链表连头元素都没有,链表里没有元素那就肯定删不了,方法直接返回null。
而我们今天讨论的问题就出现在第三步上。
四,下标变更的三种场景
当一个元素的Hash值改变后,根据(n - 1) & hash得到的下标,可能出现以下三种情况:
1,下标和元素原位置不同,新下标位置无节点。
2,下标和元素原位置不同,新下标位置有节点。
3,下标和元素原位置相同,显然元素就在这个链表中。
下面分别分析这三种情况。
1,下标和元素原位置不同,新下标位置无节点。
比如上面例子中的o2的Hash值从2改成10,新下标是10,这种情况下,前面说到的头节点p就会是null,方法直接返回null。故删除失败。
2,下标和元素原位置不同,新下标位置有节点。
比如上面例子中的o2的Hash值从2改成17,新下标是1,这种情况下,就得看一下if判断通过后的代码了:
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}一上来又是一个边赋值边判断的if逻辑,这个if逻辑实际上判断的是要remove的元素是不是头节点中的元素:
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))还是分开看,
第一步:
p.hash == hash元素Hash值和头节点Hash值相同。
第二步:
(k = p.key) == key || (key != null && key.equals(k))key就是要remove的元素本身,也就是说元素本身和头节点中的key用==或者equals判定为相同就可以。
显然此处判定为false。
看后面的else if逻辑,查询了p节点的下一节点,赋值给节点e,剩下的逻辑和处理头节点时相同,循环查询下一节点直到链表末尾。
显然此处判定也为false,因为元素不在这个链表中,第二步中二者不会相等。
于是此情形删除失败。
3,下标和元素原位置相同,显然元素就在这个链表中。
比如上面例子中的o2的Hash值从2改成18,新下标还是2,重新看上面的逻辑:
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))实际上在文章开头的例子中, o2对象就是链表的头节点,但是
p.hash == hash判断为false,因为Hash值是18,节点的Hash值是2。
(k = p.key) == key || (key != null && key.equals(k))这个判断是true。
后面判断下一节点的逻辑显然也判断为false。
于是此情形删除失败。
综上,添加到HashSet,或者HashMap(作为key)中的对象,如果改了HashCode,就无法被单独remove了。
另外,HashMap的扩容也不会使元素回到正确的位置,因为扩容时元素不会重新计算位置,而是会待在原处或下标加上原数组长度。
以上。















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









