







在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
输入文件会被切分成多个块,每一块都有一个map task
map阶段的输出结果会先写到内存缓冲区,然后由缓冲区写到磁盘上。默认的缓冲区大小是100M,溢出的百分比是0.8,也就是说当缓冲区中达到80M的时候就会往磁盘上写。如果map计算完成后的中间结果没有达到80M,最终也是要写到磁盘上的,因为它最终还是要形成文件。那么,在往磁盘上写的时候会进行分区和排序。一个map的输出可能有多个这个的文件,这些文件最终会合并成一个,这就是这个map的输出文件。
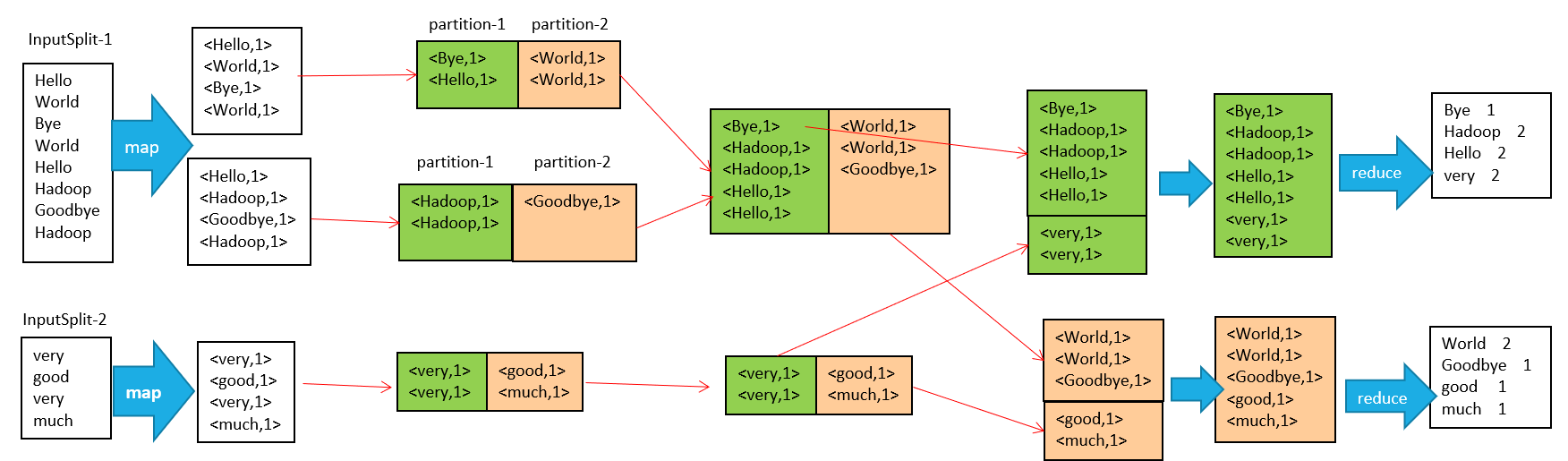
流程说明如下:
1、输入文件分片,每一片都由一个MapTask来处理
2、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
3、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
4、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
5、以上只是一个map的输出,接下来进入reduce阶段
6、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
7、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
8、reduce输出















 4665
4665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









