






云计算设计模式(二十一)——Sharding分片模式
将一个数据存储到一组水平分区或碎片。存储和访问大量数据时,这个模式可以提高可扩展性。
背景和问题
由一个单一的服务器托管的数据存储区可能会受到以下限制:
•存储空间。一种数据存储为一个大型云应用可以预期含有数据量巨大,可以随着时间的推移显著增加。服务器通常提供的磁盘存储仅是有限的,但它可以是能与较大的取代现有的磁盘,或者添加另外的磁盘的机器作为数据量的增加。然而,由此,不能够容易地增加一个给定的服务器上的存储容量的系统最终将达到一个硬限制。
•计算资源。云应用程序可能需要支持大量并发用户,每一个运行检索的数据存储信息的查询。一个单一的服务器托管的数据存储可能无法提供所需的计算能力,以支持该负载,从而延长反应时间,为用户和故障频作为应用程序试图存储和检索数据超时。它可能会增加存储器或升级的处理器,但是当其不能够提高计算资源的任何进一步的系统将达到极限。
•网络带宽。最后,在单个服务器上运行的数据存储区的性能是通过在该服务器可以接收请求并发送回复率的约束。这是可能的网络流量的量可能会超过用于连接到该服务器,从而导致失败的请求的网络的容量。
•地理。可能需要为存储由特定的用户在同一个区域中产生的那些用户为合法,合规性,或性能原因,数据,或减少数据访问延滞。如果用户在不同的国家或地区的分散,也未必能够存储整个数据为在一个单一的数据存储区中的应用。
垂直缩放通过添加更多的磁盘容量,处理能力,内存和网络连接可能会推迟一些这些限制的效果,但它很可能是只是一个临时的解决方案。能够支持大量用户和大量数据的商业云应用程序必须能够扩展几乎无限,所以垂直缩放不一定是最好的解决方案。
解决方案
划分数据存储到水平分区或碎片。每个碎片都有相同的模式,但保存的数据其独特的子集。甲碎片是在自己的权利(它可以包含许多不同类型的实体的数据)的数据存储器,用作存储节点的服务器上运行。
这种模式具有以下优点:
•您可扩展系统,通过添加额外的存储节点上运行的进一步碎片。
•系统可以使用现成的商品硬件,而不是专门的(和昂贵)的计算机为每个存储节点。
•您可以通过平衡跨越碎片的工作量减少争用和改进的性能。
•在云中,碎片可以位于物理上接近将要访问数据的用户。
何时将一个数据存储成碎片,决定哪些数据应该被放置在每个碎片。甲碎片通常包含倒在数据中的一个或多个属性所确定的指定范围内的物品。这些属性形成的分片密钥(有时也被称为分区键)。分片的关键应该是静态的。它不应该根据可能发生变化的数据。
分片身体组织的数据。何时一个应用程序存储和检索数据,该分片的逻辑指示应用到相应的碎片。此拆分逻辑可在应用程序中被实现为数据访问代码的一部分,或者它可以由数据存储系统中实现,如果它透明地支持分片。
抽象的拆分逻辑的数据的物理位置提供了一个高层次的控制在其上的碎片包含的数据,并且使数据分片之间迁移,而再加工的应用程序的业务逻辑应该需要在碎片的数据后面将要引入的(例如,如果碎片变得不平衡)。的折衷是在确定的每个数据项的位置,因为它被检索所需的附加数据存取的开销。
为了确保最佳的性能和可扩展性,分裂的数据的方式,适合的查询类型的应用程序执行是重要的。在许多情况下,这是不可能的拆分计划将完全符合每个查询的要求。例如,在一个多用户系统中的应用,可能需要通过使用承租者ID来检索租户数据,但它也可能需要基于其它属性这个数据查找,如承租人的名称或位置。为了处理这些情况,实行分片策略,即支持最常用的查询执行的一个子库的关键。
如果查询通过使用属性值的组合来定期检索数据,这可能是可以定义通过将属性一起的复合分片键。另外,使用模式,如索引表,以提供快速的查找到未覆盖的碎片关键基础属性数据。
分片策略
选择所述分片密钥,并决定如何跨碎片分发数据时的三种策略是常用的。注意,并不需要成为碎片和承载它们 - 在单个服务器可以承载多个分块中的服务器之间的一对一的对应关系。这些战略包括:
•查找策略。在上述策略中,分片的逻辑实现了一个图,路由对数据的请求到包含碎片,通过使用分片密钥数据。在一个多用户应用将租户的所有数据可能通过使用租户ID作为分片密钥一起存储在一个碎片。多个租户可能共享相同的碎片,但对于单个租户的数据将不被跨越多个碎片散布。图1示出了这种策略的一个例子。
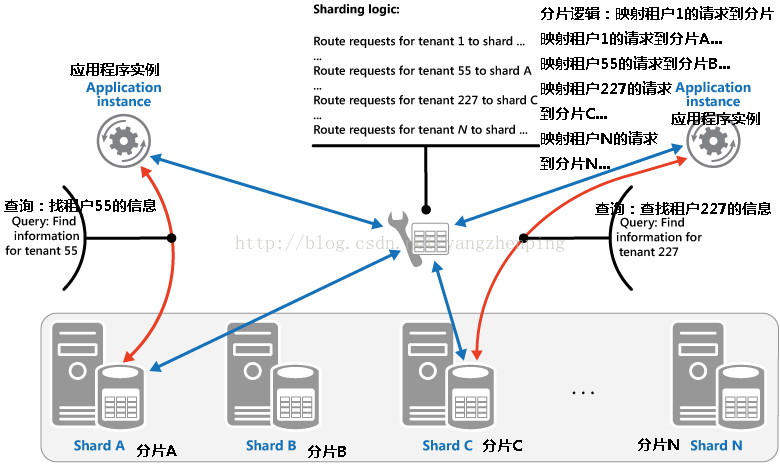
图1 - 基于租户ID的分片租户数据
分片键和物理存储的映射关系可以基于物理分块,每个分片键映射到一个物理分区。可替换地,这种技术提供了重新平衡碎片时更大的灵活性是使用虚拟分区方法,其中分片键映射到虚拟碎片的数量相同,这又映射到较少的物理分区。在这种方法中,一个应用程序通过使用指的是一个虚拟碎片一个碎片键定位数据,并在系统的虚拟分片透明地映射到物理分区。进行修改,以使用一组不同的碎片的键的虚拟碎片和物理分区可以改变,而不需要对应用程序代码之间的映射。
•范围的策略。这在同一个分片相关的项目一起策略组,并把它们的订单通过分片密钥分片键是连续的。它是用于应用程序通过使用范围查询(即返回一组数据项的为落在给定范围内的碎片键查询)经常检索项集有用的。例如,如果应用程序经常需要找到放置在给定月份所有的订单,该数据可被检索更快如果一个月的所有命令被存储在日期和时间的顺序在同一个分片。如果每个订单被存储在不同的碎片,它们将必须通过进行大量的点查询(返回单个数据项的查询)的单独取出。图2示出了这种策略的一个例子。
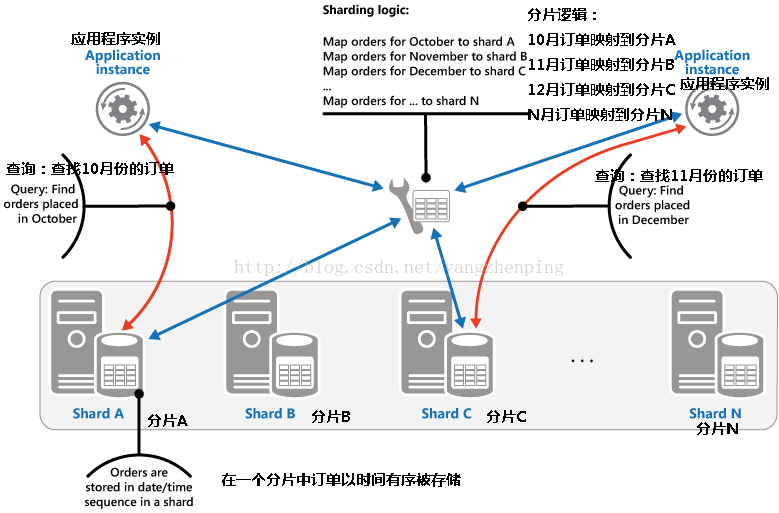
图2 - 数据中的碎片存储顺序集合(范围)
在这个例子中,分片键是一个组合键,包括订单月作为最显著元件,其次是为了日和时间。创建和附加到一个碎片新订单时,订单中的数据自然排序。一些数据存储支持包括识别所述碎片和行密钥唯一地标识该子库中的项分区键元件的两部分分片密钥。数据通常是在碎片中排键顺序举行。该受的范围内的查询和需要的项目组合在一起可以使用一个分片键具有用于分区键但该行键的唯一值相同的值。
•哈希策略。这种策略的目的是减少在数据热点的机会。它的目的是分配在实现每个碎片的大小和平均负载,每个碎片会遇到之间的平衡的方式在整个碎片中的数据。分片的逻辑计算,其中基于所述数据的一个或多个属性的散列来存储中的项目的子库。所选择的散列函数应该均匀地分布在整个数据碎片,可能通过引入一些随机元素插入的计算。图2示出了这种策略的一个例子。
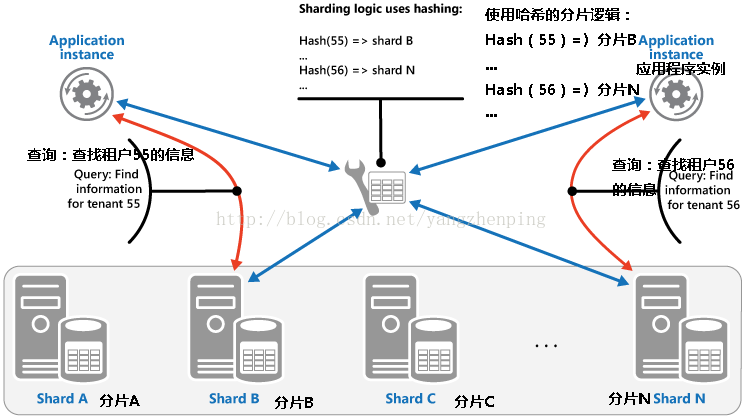
图3 - 基于租户ID的哈希分片租户数据
•了解超过其他分片策略哈希策略的优势,考虑如何依序录取新租户多租户应用程序可能分配租户碎片中的数据存储。当使用范围的策略,租户1到n的数据都将存储在分片A中,数据为住户的n +1到m都将存储在分片B,依此类推。如果最近登记的租户也是最活跃,最数据活动将发生在少数碎片,这可能会导致热点。与此相反,哈希策略分配租户基于对其租户ID的散列碎片。这意味着顺序租户是最有可能被分配到不同的碎片,如图3所示为住户55和56,这将在这些碎片分配负载。
下表列出的主要优点和考虑这三个分片策略。
| Strategy策略 | Advantages优点 | Considerations考虑 |
|---|---|---|
| Lookup 查找 | More control over the way that shards are configured and used. Using virtual shards reduces the impact when rebalancing data because new physical partitions can be added to even out the workload. The mapping between a virtual shard and the physical partitions that implement the shard can be modified without affecting application code that uses a shard key to store and retrieve data. 更好地控制碎片的配置和使用方式。 | Looking up shard locations can impose an additional overhead. 查找碎片位置可以征收额外的开销。 |
| Range 范围 | Easy to implement and works well with range queries because they can often fetch multiple data items from a single shard in a single operation. Easier data management. For example, if users in the same region are in the same shard, updates can be scheduled in each time zone based on the local load and demand pattern. 易于实现和使用范围查询工作得很好,因为它们通常可以取在单个操作中从单个分片的多个数据项。 | May not provide optimal balancing between shards. Rebalancing shards is difficult and may not resolve the problem of uneven load if the majority of activity is for adjacent shard keys. 可能不提供碎片之间的最佳平衡。 |
| Hash 哈希 | Better chance of a more even data and load distribution. Request routing can be accomplished directly by using the hash function. There is no need to maintain a map. 一个甚至更多的数据和负荷分布的更好的机会。 | Computing the hash may impose an additional overhead. Rebalancing shards is difficult. 计算哈希可能会收取额外的开销。 |
最常见的拆分方案实现上述方法之一,但你也应该考虑你的应用程序的业务需求和他们的数据使用模式。例如,在一个多用户应用:
•可以分片根据工作负载数据。你可以分开在不同的碎片极易挥发租户的数据。对于其他租户的数据访问的速度可以提高作为结果。
•可以分片根据租户的位置数据。它可能会采取对租户的数据在一个特定的地理区域离线期间在该地区非高峰期备份和维护,而对于住户在其他地区的数据仍然在他们上班时间上网和访问。
•高价值的住户能分到自己的私人高性能,轻载碎片,而价值较低的住户可能有望分享更密集堆积,忙碎片。
•对于需要数据隔离和隐私的高度可以存储一个完全独立的服务器上租户的数据。
缩放和数据移动操作
每个分片策略意味着不同的功能和复杂性管理的规模,向外扩展,数据移动,并保持水平状态。
查找策略允许缩放和数据移动操作来进行,在用户层面,无论是在线还是离线。该技术暂停部分或全部用户活动(也许是在非高峰时段),移动数据到新的虚拟分区或物理碎片,改变映射,无效或刷新持有该数据的缓存,然后让用户活动恢复。通常这种类型的操作可以进行集中管理。查找战略要求的状态是高度可缓存和副本友好。
的范围的策略规定了结垢和数据移动操作,这通常必须进行时的一部分或全部的数据存储为脱机,因为数据必须被分割和整个碎片合并的一些限制。移动的数据,以重新平衡碎片可能无法解决不均匀负荷的问题,如果大多数的活性是对相邻分片密钥或数据标识符是相同的范围之内的。范围的策略可能也需要进行维护,以图范围内的物理分区的一些状态。
哈希策略使得扩展和数据移动操作更为复杂,因为分区键是碎片密钥或数据标识符的哈希值。每个碎片的新位置,必须从散列函数来确定,或者该函数修改,以提供正确的映射。然而,哈希策略不需要维护状态。
问题和注意事项
在决定如何实现这个模式时,请考虑以下几点:
•分片是互补的其他形式的分区,如垂直分区和功能划分。例如,单个子库可以包含已垂直划分实体和功能划分可以被实现为多个碎片。有关分区的详细信息,请参阅数据分区指导。
•保持平衡碎片,使他们都处理的I / O相似的体积。作为数据被插入和删除,它可能有必要定期地重新平衡的碎片,以保证均匀分布,并减少热点的机会。再平衡可能是一个昂贵的操作。为了降低频率与再平衡成为必要,你应该确保每个碎片中含有足够的可用空间来处理变化的预期货量计划增长。你还应该制定战略和脚本,你可以用它来快速重新平衡碎片这应该成为必要。
•使用稳定的数据分片的关键。如果分片键的变化,相应的数据项可能需要碎片之间移动,增加工作通过更新操作执行的工作量。出于这个原因,避免立足于潜在的波动信息的碎片关键。相反,寻找那些不变的或自然形成的关键属性。
•确保碎片钥匙都是独一无二的。例如,应避免使用自动递增的字段作为分片的关键。在一些系统中,自动递增字段可以不横跨碎片协调,从而可能导致在具有相同分片键不同的碎片的项目。
注意:
在不包括分片键也可能导致问题字段自动递增值。例如,如果您使用自增字段来生成唯一标识,并分布在不同的碎片两个不同的项目可能被分配相同的ID。
•它可能无法设计出符合针对数据的每个可能的查询要求一个分片键。分片的数据,以支持最经常进行的查询,并在必要时创建二级索引表,以支持通过使用基于不属于分片键的一部分的属性标准检索数据的查询。欲了解更多信息,请参见索引表模式。
•查询访问仅单个碎片会比那些来自多个分块中检索数据的效率,从而避免执行一个分片方案,该方案导致在执行该连接在不同碎片保持的数据的查询的大量应用程序。请记住,碎瓷片可以包含的数据为多个类型的实体。考虑非规范化的数据保持相同的碎片常常被认为是一起查询(如客户的详细信息和订单,他们已经把)相关实体,以减少单独读取数的应用程序执行。
注意:
如果在一个子库的实体引用存储在另一个分片的一个实体,包括分片键用于第二实体,作为第一实体的架构的一部分。这可以帮助提高引用跨碎片相关数据查询的性能。
•如果应用程序必须执行检索来自多个分块数据的查询,有可能通过使用并行任务来获取这些数据。例子包括扇出查询,其中来自多个分片的数据检索平行,然后汇总到一个结果。然而,这种方法不可避免地增加了一些复杂性的溶液的数据访问逻辑。
•对于许多应用来说,产生的小碎片更大数目可以比具有少量的大碎片,因为它们可以提供用于负载平衡的机会增加更加有效。如果预计需要碎片从一个物理位置移动到另一个这样的方法也可以是有用的。移动小碎片比移动一个大的更快。
•确保提供给每个分片存储节点的资源足以处理数据的规模和吞吐量方面的可扩展性要求。欲了解更多信息,请参阅数据分区引导部分“设计分区的可扩展性”。
•考虑复制参考数据所有碎片。如果从一个子库中检索数据的操作还引用静态或缓慢移动的数据作为同一查询的一部分,这个数据添加到碎片。然后,应用程序可以读取所有用于容易地查询中的数据,而无需进行额外的往返行程到一个单独的数据存储中。
注意:
如果在多个分块的变化保持的基准数据,该系统必须同步所有碎片这些变化。而此同步发生时,系统可能会出现一定程度的混乱。如果你按照这种方法,你应该设计自己的应用程序能够处理这个矛盾。
•它可以是难以维持的碎片之间的参照完整性和一致性,所以你应该尽量减少影响在多个碎片数据操作。如果应用程序必须通过碎片修改数据,评估完整的数据一致性是否实际上是一个要求。相反,在云中一个常用的方法是实现最终一致性。每个分区中的数据分别进行更新,并在应用程序逻辑必须承担保证责任的更新都成功完成,以及处理,可以从查询数据的最终一致的运行操作时产生的不一致。有关实现最终一致性的更多信息,请参阅数据一致性底漆。
•配置和管理大量碎片可能是一个挑战。任务,例如监控,备份,检查一致性,并记录或审计必须完成对多个碎片和服务器,在多个位置有可能保持。这些任务可能会通过使用脚本或其他自动化解决方案,但脚本和自动化可能无法完全消除额外的行政要求执行。
•碎片可以是地理定位的,使得它们包含的数据是靠近使用它的应用程序的实例。这种方法可以显着改善的性能,但是需要额外考虑为必须访问多个分块中的不同位置的任务。
何时使用这个模式
使用这种模式:
•当数据存储可能需要扩展超越了一单个存储节点的资源的限制。
•通过减少争用的数据存储来提高性能。
注意:
分片的主要焦点是改进系统的性能和可扩展性,而作为副产物,也可以借助于其中数据被划分成单独的分区的方式提高可用性。在一个分区中的故障不一定阻止应用程序访问的其他分区中保存的数据,并且操作者无需使得整个数据为应用程序无法访问的可以执行的一个或多个分区的维护或复原。欲了解更多信息,请参阅数据分区指导。
例子
下面的示例使用了一组充当碎片的SQL Server数据库。每个数据库包含一个应用程序使用的数据的一个子集。应用程序检索该被分布在整个碎片通过使用它自己的分片逻辑(这是一个扇出查询的一个例子)的数据。将位于每个子库中的数据的细节是通过这样的方法称为GetShards返回。此方法返回ShardInformation对象,其中ShardInformation类型包含一个标识符为每个碎片和SQL Server的连接字符串,应用程序应该使用连接到碎片的枚举列表(在连接字符串中没有代码示例所示)。
- private IEnumerable<ShardInformation> GetShards()
- {
- // This retrieves the connection information from a shard store
- // (commonly a root database).
- return new[]
- {
- new ShardInformation
- {
- Id = 1,
- ConnectionString = ...
- },
- new ShardInformation
- {
- Id = 2,
- ConnectionString = ...
- }
- };
- }
下面的代码显示了如何在应用程序使用ShardInformation对象名单进行了从并行每个碎片获取数据的查询。查询的细节没有示出,但在本实施例中所检索的数据包括可以存放信息,如客户的名称,如果碎片包含客户的细节的字符串。该结果由应用聚集成ConcurrentBag集合进行处理。
- // Retrieve the shards as a ShardInformation[] instance.
- var shards = GetShards();
- var results = new ConcurrentBag<string>();
- // Execute the query against each shard in the shard list.
- // This list would typically be retrieved from configuration
- // or from a root/master shard store.
- Parallel.ForEach(shards, shard =>
- {
- // NOTE: Transient fault handling is not included,
- // but should be incorporated when used in a real world application.
- using (var con = new SqlConnection(shard.ConnectionString))
- {
- con.Open();
- var cmd = new SqlCommand("SELECT ... FROM ...", con);
- Trace.TraceInformation("Executing command against shard: {0}", shard.Id);
- var reader = cmd.ExecuteReader();
- // Read the results in to a thread-safe data structure.
- while (reader.Read())
- {
- results.Add(reader.GetString(0));
- }
- }
- });
- Trace.TraceInformation("Fanout query complete - Record Count: {0}",
- results.Count);
本文翻译自MSDN:http://msdn.microsoft.com/en-us/library/dn589797.aspx
















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









