







在前一篇读书笔记里已经提过,如果我们定义的一个类型只重写了Equals而没有重写GetHashCode方法时编译器会发出警告信息。
一个类型为什么要同时重写Equals方法和GetHashCode方法?这是因为System.Collections.Hashtable类型的实现要求任何两个相等的对象都必须有相同的散列码值。即GetHashCode的行为依赖于Equals方法进行判断。所以,如果我们重写了Equals方法,也应该(必须)重写GetHashCode方法以确保用来判等的算法和用来计算对象散列码的算法一致。
基本上来讲,当我们向一个Hashtable对象中添加一个“键/值对”时,其中“键对象”的散列码会首先被获取。该散列码指出了“键/值对”应该被存储在哪个“散列桶”中。当Hashtable对象需要查找某个“键”时,它会取得指定的“键对象”散列码。然后在该散列码所标识的那个“散列桶”中进一步查找和指定的“键对象”相等的“键对象”。使用这种存储和搜索的“键”算法意味着如果我们改变了Hashtable中的一个“键对象”,我们在Hashtable中将不能再找到该对象。如果我们改变一个散列表中的“键对象”,我们应该首先删除原来的“键/值对”,然后改变“键对象”,最后再将新的“键/值对”添加到散列表中。
System.Object中实现的GetHashCode方法对于它的派生类型及其内的字段一无所知。出于这个原因,Object的GetHashCode方法返回的是一个在应用程序域范围内确保唯一的数值。该数值在整个生命周期中保证不会改变。但是,在对象被执行垃圾收集后,这个唯一的数值可以被重新利用作为一个新的对象的散列码。
System.ValueType中实现的GetHashCode方法使用反射来返回定义在类型中第一个实例字段的散列码。这个简单的实现对于某些值类型来说可能已经够用,但是还是建议最好提供自己的实现。即使我们实现的算法同样返回一个实例字段的散列码,我们的实现也要比ValueType中实现的快一些(why?因为是直接调用的缘故?)下面是ValueType中实现的GetHashCode方法:
 class ValueType
class ValueType


 {
{
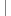 protected override Int32 GetHashCode()
protected override Int32 GetHashCode()

 {
FieldInfo[] fields = this.GetType().GetFields(BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic);
if(fields.Length > 0)
{
for(Int32 i = 0;i < fields.Length;i++)
{
Object obj = fields[i].GetValue(this);
if(null != obj)
return obj.GetHashCode();
{
FieldInfo[] fields = this.GetType().GetFields(BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic);
if(fields.Length > 0)
{
for(Int32 i = 0;i < fields.Length;i++)
{
Object obj = fields[i].GetValue(this);
if(null != obj)
return obj.GetHashCode();
 }
}
//如果没有非空字段,为其返回一个与类型相关的唯一值
return GetMethodTablePtrAsInt(this);
}
}
}
//如果没有非空字段,为其返回一个与类型相关的唯一值
return GetMethodTablePtrAsInt(this);
}
 }
}
如果我们因为某种原因要实现自己的散列表集合,或者编写的任何代码中调用了GetHashCode方法,我们都不应该持久化(persist)散列码值。原因是散列码值可能会改变。例如,一个类型的下一个版本可能会使用不同的算法来计算对象的散列码。
选择计算类型实例的散列码算法时,我们应该尽力遵循以下原则:
1、算法应该使所得的数值有一个良好的随机分布,这样散列表可以获得最佳的性能。
2、算法还可以调用基类型的GetHashCode方法,并将其返回值包含在我们的算法中。但在一般情况下,我们不应该调用Object或ValueType的GetHashCode方法,因为这两个类型的GetHashCode方法实现都不会获得高性能的 散列算法。
3、算法应该至少使用一个实例字段(以确保唯一性?)。
4、理想情况下,我们在算法中使用的字段都应该是恒定不变的;也就是说在构造对象时字段被初始化后,它们就不 应该再在对象的生存周期内有任何改变。
5、算法应该执行的尽可能快。
6、有着相同值的对象应该返回相同的散列码。例如,两个有着相同文本的String对象应该返回相同的散列码值















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









