






手段一:
Robots协议:用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。
spider在访问一个网站是,会首先检查该网站的根域下是否有一个叫做robots.txt的纯文本文件,这个文件用于指定spider在您网站上抓取范围。
一般屏蔽有:隐私资料,表结构
robots文件是存在于网站的根目录下,首先会检查http://www.123.com/robots.txt这个文件。
robots格式:
User-agent: (代表所有搜索引擎)
Disallow:(不允许抓取的相对路径)
allow:(允许抓取的相对路径或文件)
robots.txt生成器:https://robots.51240.com/
文件用法
例:
- 禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: /
实例分析:淘宝网的 Robots.txt文件:访问www.taobao.com/robots.txt
User-agent: Baiduspider
Allow: /article
Allow: /oshtml
Disallow: /product/
Disallow: /
User-Agent: Googlebot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-agent: Bingbot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-Agent: 360Spider
Allow: /article
Allow: /oshtml
Disallow: /
User-Agent: Yisouspider
Allow: /article
Allow: /oshtml
Disallow: /
User-Agent: Sogouspider
Allow: /article
Allow: /oshtml
Allow: /product
Disallow: /
User-Agent: Yahoo! Slurp
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-Agent: *
Disallow: /做个例子,分析第一条:
User-agent: Baiduspider
Allow: /article
Allow: /oshtml
Disallow: /product/
Disallow: /显然淘宝允许百度能访问根目录下的article,oshtml,不允许访问product目录根目录下其他的目录
手段二:
除了设置robots协议之外,还可以在网页代码里面设置。
在网页<head></head>之间加入<meta name="robots" content="noarchive">代码。表示紧致所有搜索引擎抓取网站和显示快照。
- NOINDEX:告诉Google不要索引含此标签的网页。但根据实际经验,Google并非100%遵守。
- NOFOLLOW:告诉Google不要关注含此标签的网页里的特定链接。这是为了解决链接spam而设计的Meta标签。
- NOARCHIVE:告诉Google不要保存含此标签的网页的快照。
- NOSNIPPET:告诉Google不要在搜索结果页的列表里显示含此标签的网站的描述语句,并且不要在列表里显示快照链接。
如果要针对某一个搜索引擎禁止抓取,在网页<head></head>之间加入<meta name="baidspider" content="noarchive">代码,表示禁止百度抓取,<meta name="googlebot" content="noarchive">表示禁止谷歌抓取,其他的搜索引擎一样原理。
这样,一共有四种组合:
<META NAME="ROBOTS" CONTENT="INDEX,FOLLOW">
<META NAME="ROBOTS" CONTENT="NOINDEX,FOLLOW">
<META NAME="ROBOTS" CONTENT="INDEX,NOFOLLOW">
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">
其中
<META NAME="ROBOTS" CONTENT="INDEX,FOLLOW">可以写成<META NAME="ROBOTS" CONTENT="ALL">;
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">可以写成<META NAME="ROBOTS" CONTENT="NONE">手段三:
拒绝网站的站内搜索功能是支持输入HTML代码或者UBB代码
例如:

防护方式:
1.屏蔽搜索引擎收录站内搜索页,或者关闭站内搜索功能
2.不屏蔽站内搜索,那需要及时发现站内搜索数据是否异常,再设置敏感词词库过滤一些黑灰产业的关键词,以及站内搜索必须是纯文本形式。
手段四:
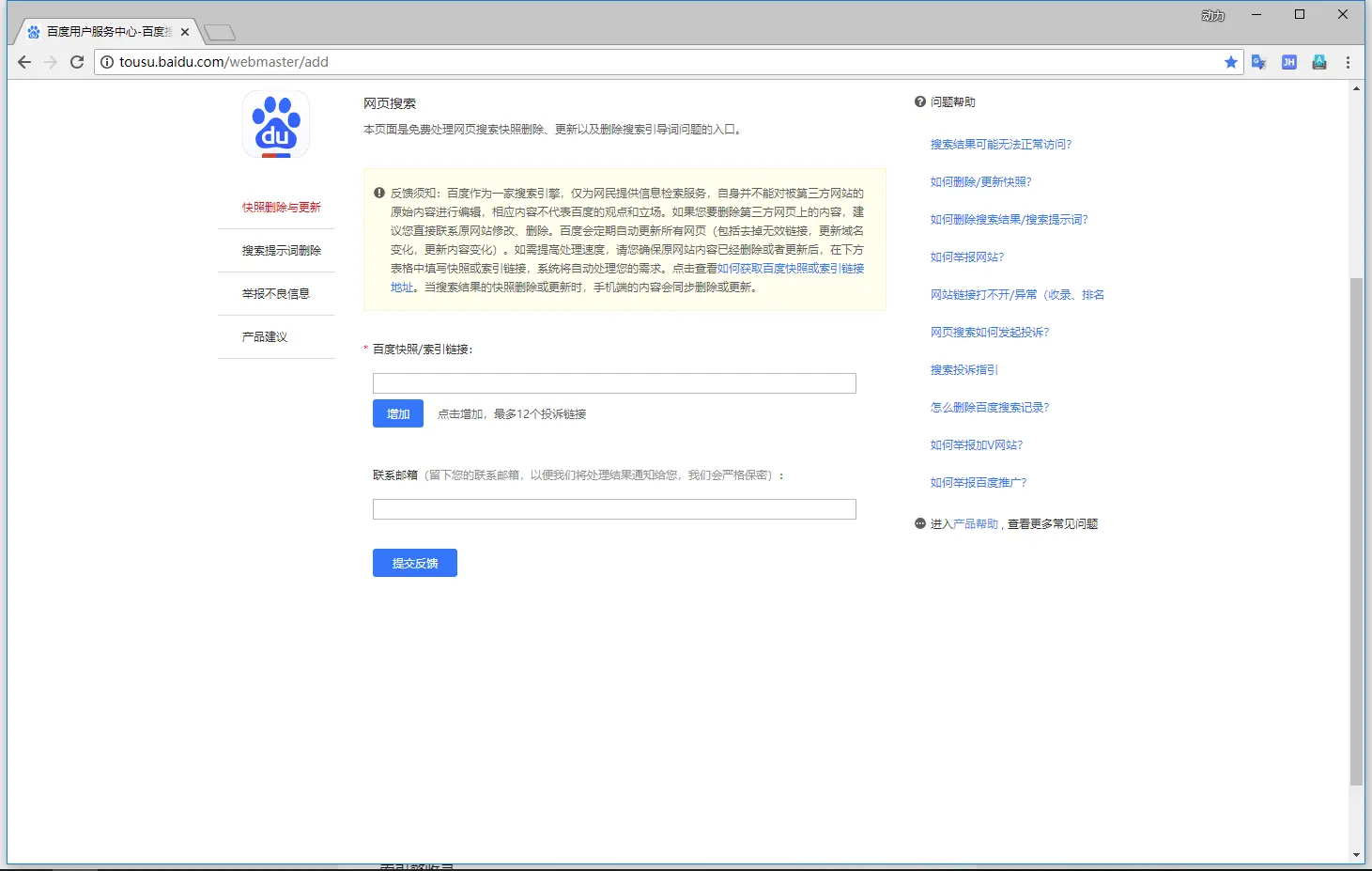
通过搜索引擎提供的站长工具,删除网页快照
网址:http://tousu.baidu.com/webmaster/add
手段五:
配置nginx的配置文件,增加http_user_agent字段进行禁止网络爬虫,直接返回403
例子:
server {
listen 80;
server_name _ ; (域名或者默认服务器地址)
#添加防止哪些爬虫,下面做例子
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot")
{
return 403;
} 或者
#新增location字段,并且匹配到了蜘蛛,则返回403
location = /robots.txt {
if ($http_user_agent !~* "spider|bot|Python-urllib|pycurl")
{ return 403; }
}测试工具:http://s.tool.chinaz.com/tools/robot.aspx
注意:如果还是能够搜索到,是因为某搜索引擎不遵守robots协议约定,那么通过robots来禁止搜索是不够的。
转载于:https://blog.51cto.com/leoheng/2129526















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









