







- 描述了全文检索的一般过程
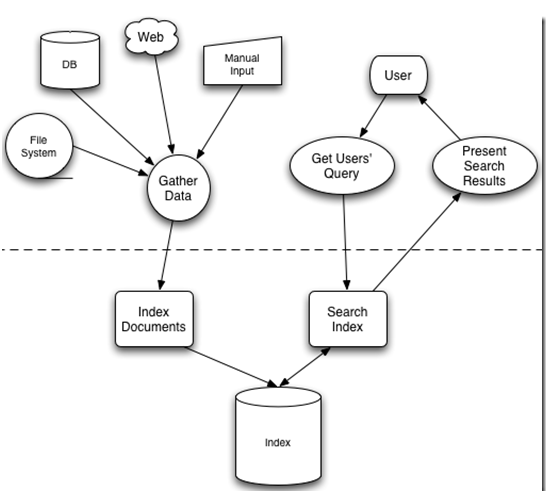
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
- 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
于是全文检索就存在三个重要问题:
- 1. 索引里面究竟存些什么?(Index)
- 2. 如何创建索引?(Indexing)
- 3. 如何对索引进行搜索?(Search)
索引里面究竟存些什么
- 由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
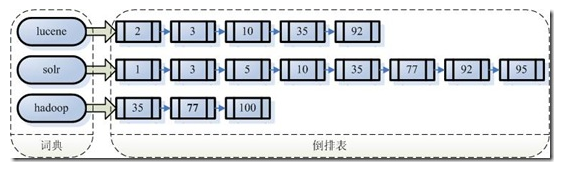
- 左边保存的是一系列字符串,称为词典 。
- 每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表 (Posting List)。
查询既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
- 1. 取出包含字符串“lucene”的文档链表。
- 2. 取出包含字符串“solr”的文档链表。
- 3. 通过合并链表,找出既包含“lucene”又包含“solr”的文件。

- 全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
如何创建索引
第一步:一些要索引的原文档(Document)。
第二步:将原文档传给分词器(Tokenizer)。
- 中文分词器: IK Analyzer
-
1. 将文档分成一个一个单独的单词。
2. 去除标点符号。
3. 去除停词(Stop word) 。
-
第三步:将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
- 1. 变为小写(Lowercase) 。
- 2. 将单词缩减为词根形式,如“cars ”到“car ”等。这种操作称为:stemming 。
- 3. 将单词转变为词根形式,如“drove ”到“drive ”等。这种操作称为:lemmatization 。
第四步:将得到的词(Term)传给索引组件(Indexer)。
- 1. 利用得到的词(Term)创建一个字典。
- 2. 对字典按字母顺序进行排序。
- 3. 合并相同的词(Term) 成为文档倒排(Posting List) 链表。
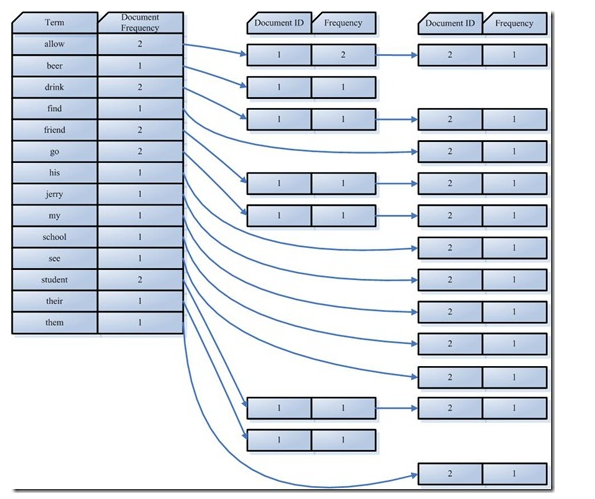
- Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)。
如何对索引进行搜索?
- 搜索主要分为以下几步:
-
第一步:用户输入查询语句。
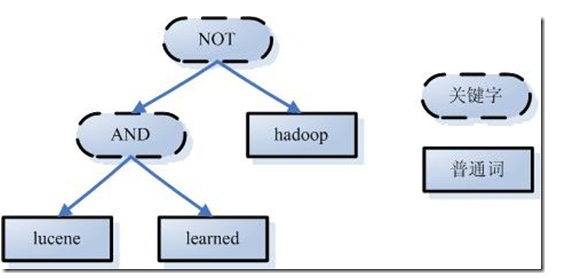
- 举个例子,用户输入语句:lucene AND learned NOT hadoop。
-
第二步:对查询语句进行词法分析,语法分析,及语言处理。
- 1. 词法分析主要用来识别单词和关键字。
- 2. 语法分析主要是根据查询语句的语法规则来形成一棵语法树。
- 如上述例子,lucene AND learned NOT hadoop形成的语法树如下:
- 如上述例子,lucene AND learned NOT hadoop形成的语法树如下:
-
3. 语言处理同索引过程中的语言处理几乎相同。
-
如learned变成learn等。
-
-
第三步:搜索索引,得到符合语法树的文档。
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
- 然后,将此链表与hadoop的文档链表进行差操作,
- 去除包含hadoop的文档,
- 从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
- 此文档链表就是我们要找的文档。
-
第四步:根据得到的文档和查询语句的相关性,对结果进行排序。
- 首先,一个文档有很多词(Term)组成
- 找出词(Term) 对文档的重要性:计算词的权重(Term weight)
- 词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要
- 有越多的文档包含此词(Term), 说明此词(Term),重要性越低
-
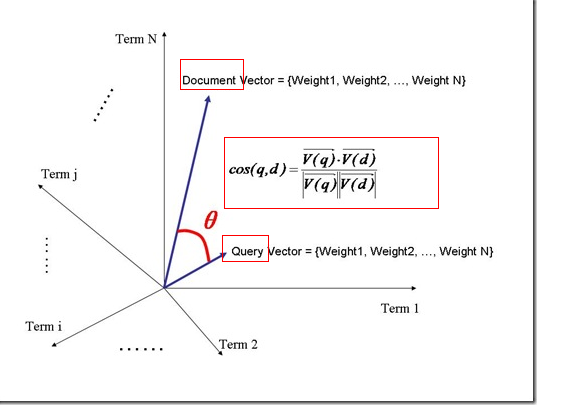
判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
-
我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
-
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
-
-
查询语句看作一个简单的文档,也用向量来表示
-
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
-
-
-
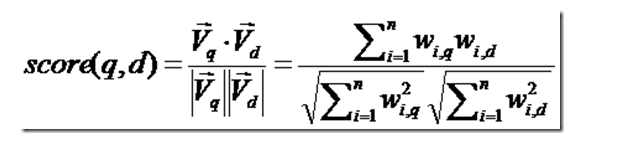
-
-
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









