







Hadoop是干嘛的?传送门
正式的应用场景下,Hadoop将会进行在一个很多台Linux服务器组成的大集群上,首先我们就把这个环境给搞起来。现实情况是,没有很多台Linux 服务器,所以第一步,虚拟机搞起来。很多培训教程都是将hadoop先搭建一个单机的模式,我建议大家直接搞3个虚拟机,一个master两个 slave(这种叫法虽不正确,但是一下就懂),这样会更贴近真实环境一些,对我们观察hadoop的动作和理解原理更有一些帮助。
由于某些原因,我将使用jdk6和hadoop1.1.2,后续会有涉及升级的文章。
①虚拟机安装
虚拟机软件多得很,主要需要注意的就是安装的系统版本和网络设置。
系统必然是centos,版本建议大家先使用稳定的6.5。网络设置为host-only模式,一个封闭稳定的网络环境用来学习最适合不过了。在window下的安装配置方法网上一搜一堆。下面只给出我的环境Mac+Parallels Desktop的网络设置细节。
1:设置Parallels网卡,在 【系统偏好设置 /网络】 中大家会找到一个Parallels Host-Only #1,点击 “高级”,如上设置,其中ipv4的地址129大家随意改,剩下的就这样吧.


2:进入3个虚拟机桌面,设置各自的IP,我的设置如下:master 192.168.0.100;slave1 192.168.0.101;slave2 192.168.0.102。国际惯例所有机器的子网掩码为255.255.255.0,网关为192.168.0.1。
3:用ssh工具连接吧,我用的是SecureCRT。登陆成功互相ping一下,OK。
ps:为了方便配置,我所有的linux操作都使用root用户,真实环境下有待商榷。
②各台机器的必要设置
1:设置各台机器的hostname,如master进行如下操作:
vim /etc/sysconfig/network 添加一句 HOSTNAME=master (centos7 :hostnamectl --static set-hostname master)
需要重启机器才生效,如果想立刻生效,执行hostname master
2: 设置hosts,所有的机器进行如下操作
vim /etc/hosts
添加 192.168.0.100 master
192.168.0.101 slave1
192.168.0.102 slave2
3:关闭防火墙,所有的机器进行如下操作:
service iptables stop //关闭防火墙 ,在centos 7中是 systemctl stop firewalld
chkconfig iptables off //设置防火墙不自启动,在centos 7中是 systemctl disable firewalld
4:免秘钥登陆:所有的分布式系统都需要机器之间免密钥登陆,神马hadoop,storm之流。我们要做的就是将master的钥匙发送给slave,让中枢神经在master的hadoop可能直接管理slave,在master上运行以下命令 :
ssh-keygen -t rsa ; //一路回车
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys ;
scp ~/.ssh/id_rsa.pub root@slave1:~/id_rsa.pub;//这时候还要输入密码
scp ~/.ssh/id_rsa.pub root@slave2:~/id_rsa.pub;//这时候还要输入密码接着登陆两台slave:
mkdir .ssh
mv ~/id_rsa.pub ~/.ssh/authorized_keys测试,在master上运行以下命令,不需要输入密码即ok,所有的slave机器也需要生成秘钥并添加到master中
ssh slave1 //第一次运行需要输入一个 yes
ssh slave2 //第一次运行需要输入一个 yes③分发工具
所有的分布式系统都需要在集群上同步,当集群数多了一台台手动改那太不可取,so需要一个分发工具,虽然只有两个slave,我们也要追求幸福!
pssh是一个基于python的小巧精干的工具,下载的时候可能需要翻墙。下载后用sftp工具上传到 master的/opt(我用的ForkLift)。在master运行以下命令进行安装:
cd /opt
tar -zxvf pssh-2.3.1.tar.gz
cd pssh-2.3.1
python setup.py install
cd bin
touch hosts.txthosts.txt 中配置两台slave的ip地址,pssh工作的时候需要该文件来确定分发的目标,使用pssh之前必须完成步骤2,测试一下
pscp -h hosts.txt -r hosts.txt /hosts.txt //分发文件
pssh -h hosts.txt -i "hostname" //分发执行命令,只能执行指令型的命令,神马vim,top之流是不行的。有了分发工具,日子幸福多了,后续的很多操作都只用一行命令即可
④安装jdk
将jdk安装包上传到master的 /opt中,因为有了分发工具,各种安装包,压缩包啊之流的只需要上传到master然后进行分发就可以了。
cd /opt //咱们所有的软件都装在国际惯例 /opt
./jdk1.6.0_45.bin //安装,如果没权限 执行 chmod u+x jdk1.6.0_45.bin⑤安装配置Hadoop
所谓的安装Hadoop就是把Hadoop的包解压缩,之后配置下面六个文件:
1:HADOOP_HOME/conf/hadoop_env.sh //Hadoop环境
export JAVA_HOME=/opt/jdk1.6.0_45 //jdk路径
export HADOOP_LOG_DIR=/bigdata/logs/hadoop //日志默认是在/tmp下,改到一个合理的位置
export HADOOP_PID_DIR=/var/hadoop/pids //进程号默认是在/tmp下,改到一个合理的位置2:HADOOP_HOME/conf/core-site.sh //核心配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<description>hdfs web port.</description>
</property>
</configuration>3:HADOOP_HOME/conf/hdfs-site.xml //Hdfs设置
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>how many copies of every block in our hadoop.God,poor English..</description>
</property>
</configuration>4 : HADOOP_HOME/conf/mapred-site.xml //mapreduce设置
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
<description>map-reduce web port.</description>
</property>
</configuration>5 : HADOOP_HOME/conf/masters //所有机器都需要配置,制定Hadoop的master
192.168.0.1006:HADOOP_HOME/conf/slaves //只需master配置,制定slaves列表,一行一个IP
192.168.0.101
192.168.0.102 关于Hadoop的安装路径有个小技巧:将未来可能涉及到升级的包都放在 /bigdata 分区里,通过软连接指定到 /opt的对应文件夹,这样做的好处是未来涉及到升级也不需要改变环境变量只需要重新设置软连接即可。在master中执行如下操作,完成Hadoop包的分发和软连接命令执行
cd /bigdata
ln -s /bigdata/hadoop/hadoop-1.1.2 /opt/hadoop 创建软连接
pscp -h hosts.txt -r /bigdata/hadoop/hadoop-1.1.2 /bigdata/hadoop/hadoop-1.1.2 //分发Hadoop
pssh -h hosts.txt -i "ln -s /bigdata/hadoop/hadoop-1.1.2 /opt/hadoop" //分发命令到slave创建软连接,如下 
⑥必须设置的环境变量
我就喜欢把同样的事情放在一起做,设置java和hadoop的环境变量吧。执行命令 :vim /etc/profile,加入以下配置后执行 source /etc/profile使环境变量生效。
JAVA_HOME=/opt/jdk1.6.0_45
HADOOP_HOME=/opt/hadoop
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:/opt/pssh/bin:$PATH
CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export HADOOP_HOME
export PATH
export CLASSPATH⑦大功告成
经过这么一裤衩的配置,重要要看到东西了,最后运行两行命令
hadoop namenode -format //格式化hdfs的文件系统
start-all.sh //启动Hadoop,改脚本位于HADOOP_HOME/bin/ 下,环境变量生效验证一下:jps。可以看到在master中起了我们熟悉的NameNode和JobTracker,还有一个奇怪的SecondaryNameNode,这家伙干嘛的我们以后说说。两台slave中都起了DataNode和TaskTracker。大功告成。
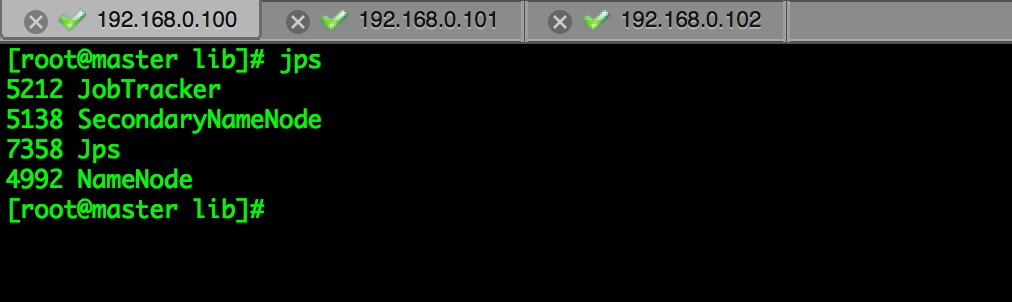
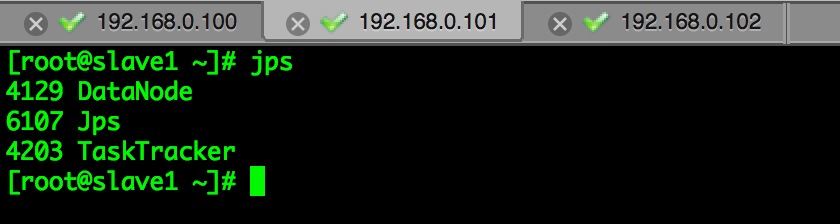

最后用宿主机来访问一下两个web系统,宿主机也要配置hosts哦。
1:HDFS系统:http://master:50070/dfshealth.jsp
2 : Job系统 : http://master:50030/jobtracker.jsp


That's all.















 70
70

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









