







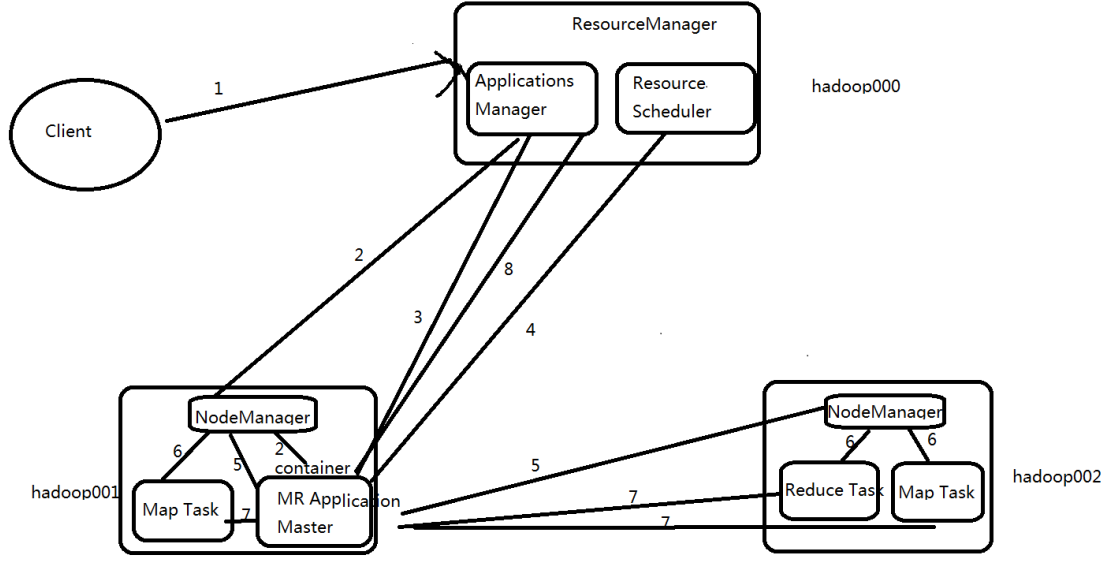
1、客户端向Yarn提交一个程序application(包含程序主体applicationMaster和程序启动命令)
2、ResourceManager接收请求后会在集群中寻找一个NodeManager并分配一个Container,与对应的NodeManager通信(rpc通信)并要求container启动applicationMaster;
3、applicationMaster向ResourceManager注册(这样就可以通过yarn的web界面查看任务运行状态),
4、根据任务信息向ResourceManager申请资源(Container);
5、由于是分布式计算,所以applicationMaster申请到资源后会向另外的NodeManager节点和自己的NodeManager节点rpc通信并启动container(运行MapTask和ReduceTask),每个container里面的Task时刻向applicationMaster 汇报( rpc通信)自己运行的状态和进度,为了防止任务失败能及时重启。
6、当任务运行完成,ApplicationMaster会向ResourceManager注销并关闭自己。















 3140
3140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









