






参考书目:鸟哥的LINUX私房菜基础学习篇(第三版)
Linux Shell Scripting Cookbook
本节主要内容
- 基础正则表达式
1. 基础正则表达式
(1)^行开始符
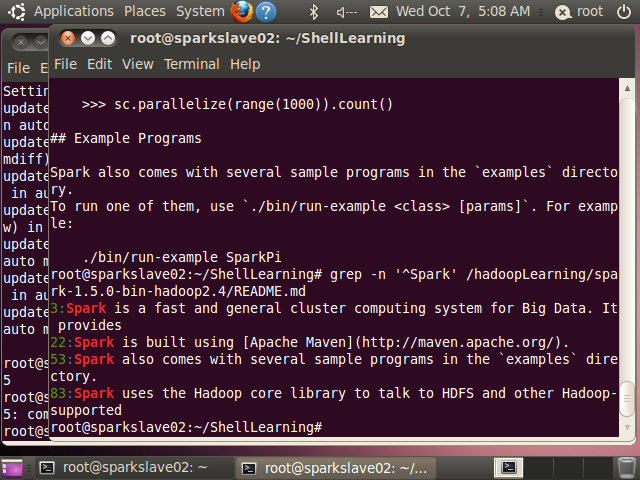
^匹配一行的开始,例如’^Spark’ 匹配所有Spark开始的行
//grep -n表示查找到的结果显示行号
root@sparkslave02:~/ShellLearning# grep -n '^Spark' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
3:Spark is a fast and general cluster computing system for Big Data. It provides
22:Spark is built using [Apache Maven](http://maven.apache.org/).
53:Spark also comes with several sample programs in the `examples` directory.
83:Spark uses the Hadoop core library to talk to HDFS and other Hadoop-supported
(2)$行结束符
匹配一行的结束,例如′Spark’ 匹配所有以Spark结束的行
root@sparkslave02:~/ShellLearning# grep -n 'Spark$' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
20:## Building Spark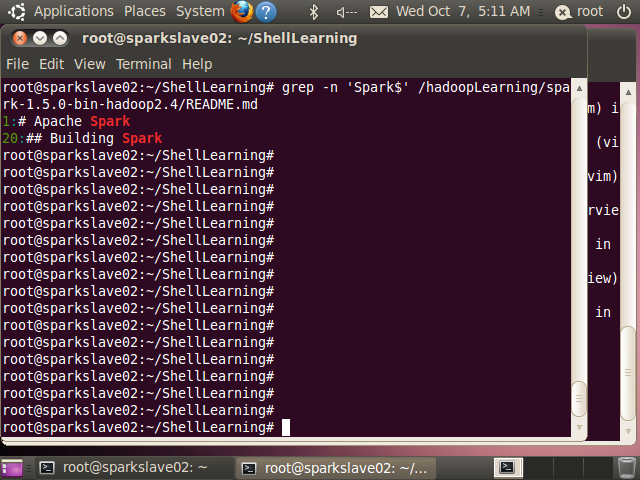
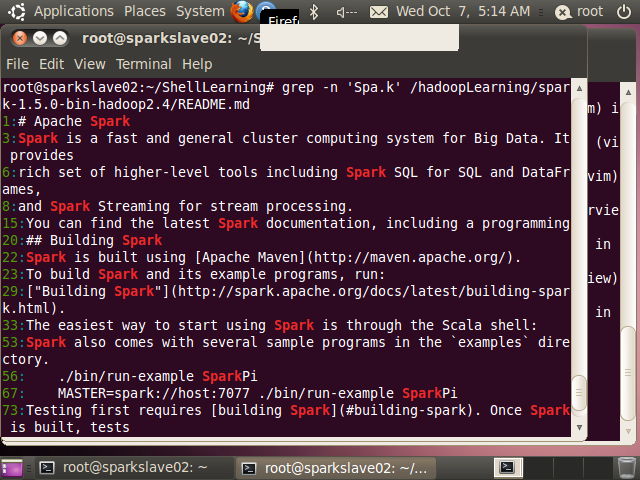
(3).匹配任意一个字符
例如 Spa.k可以匹配Spark、Spaak等
root@sparkslave02:~/ShellLearning# grep -n 'Spa.k' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
3:Spark is a fast and general cluster computing system for Big Data. It provides
6:rich set of higher-level tools including Spark SQL for SQL and
//其它省略
上面没有匹配小写spark,要匹配可以采用
//-i选项表示忽略大小写
root@sparkslave02:~/ShellLearning# grep -in 'Spa.k' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md 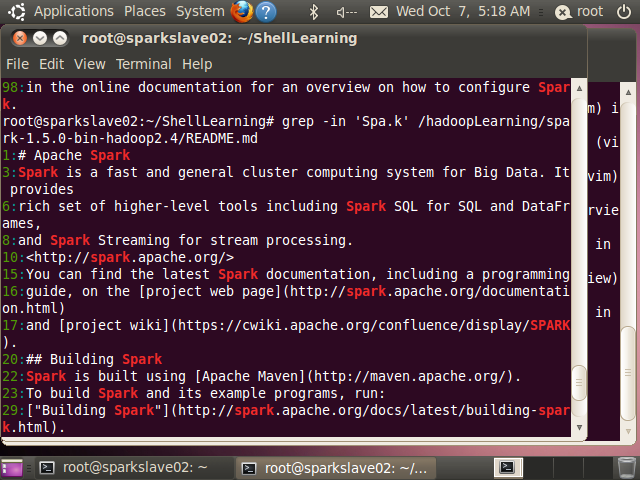
(4)[]匹配其中一个
[Ss]park只匹配Spark和spark
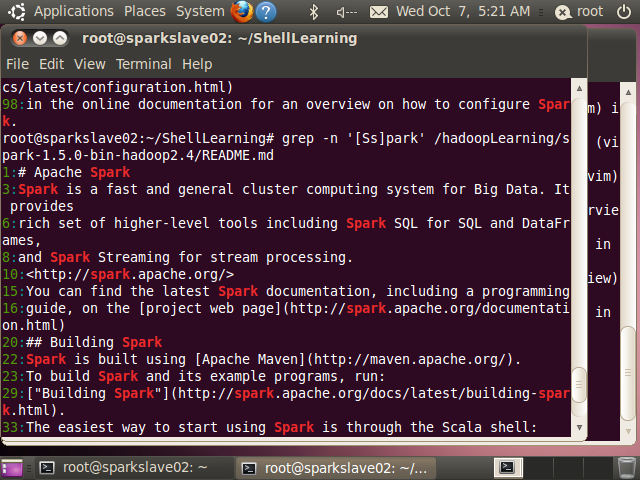
root@sparkslave02:~/ShellLearning# grep -n '[Ss]park' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
3:Spark is a fast and general cluster computing system for Big Data. It provides
6:rich set of higher-level tools including Spark SQL for SQL and DataFrames,
8:and Spark Streaming for stream processing.
10:<http://spark.apache.org/>
//其它省略
(5) [^]不匹配[]中的任何一个字符
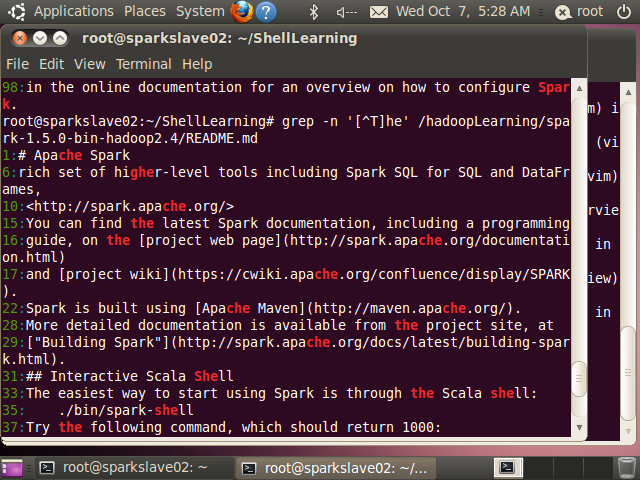
例如 ‘[^T]he’ ,不匹配The,但可匹配 the、che等
root@sparkslave02:~/ShellLearning# grep -n '[^T]he' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
(6) [-]匹配固定范围的字符
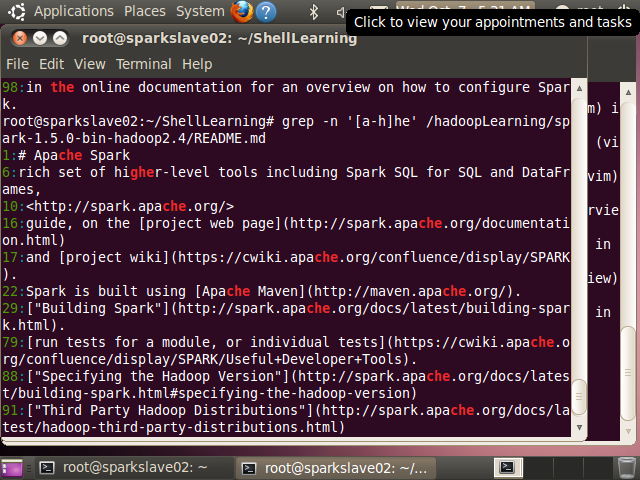
例如[a-h]he,只匹配ahe、bhe、che…hhe,不匹配ihe、the等
root@sparkslave02:~/ShellLearning# grep -n '[a-h]he' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
6:rich set of higher-level tools including Spark SQL for SQL and DataFrames,
10:<http://spark.apache.org/>
16:guide, on the [project web page](http://spark.apache.org/documentation.html)
(7)? 匹配0次或1次
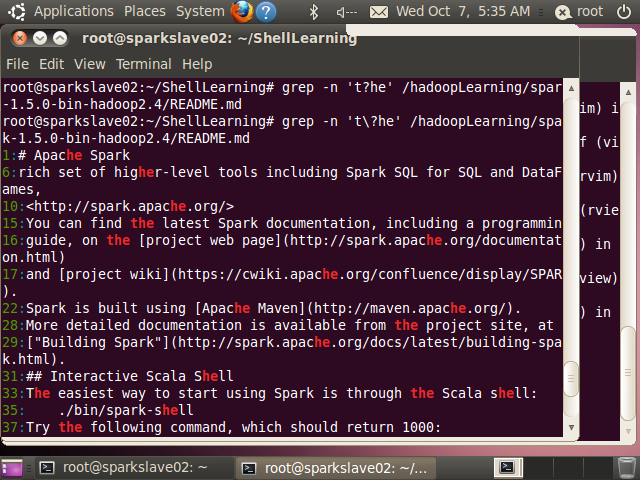
例如t?he只匹配he和the,不匹配tthe
//?属于特殊符号,需要\进行转义
root@sparkslave02:~/ShellLearning# grep -n 't\?he' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
6:rich set of higher-level tools including Spark SQL for SQL and DataFrames,
10:<http://spark.apache.org/>
15:You can find the latest Spark documentation, including a programming
16:guide, on the [project web page](http://spark.apache.org/documentation.html)
//其它省略
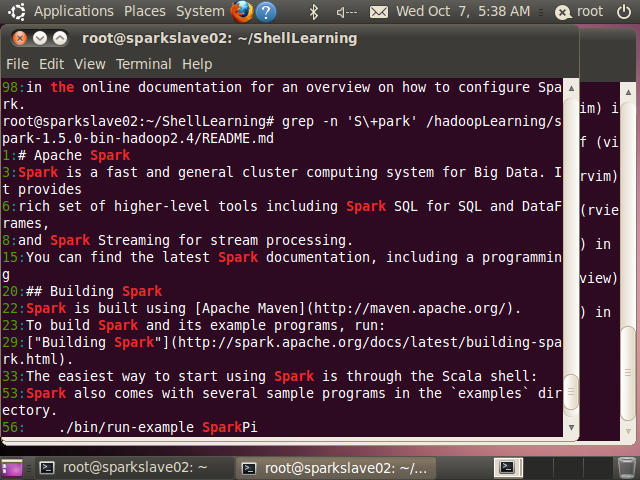
(8)+ 至少匹配一次
‘S+park’可以匹配Spark、SSpark、SSSpark等
root@sparkslave02:~/ShellLearning# grep -n 'S\+park' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
(9) * 匹配零次或多少
‘S*park’可匹配park、Spark、SSpark、SSSpark等
root@sparkslave02:~/ShellLearning# grep -n 'S*park' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
3:Spark is a fast and general cluster computing system for Big Data. It provides
6:rich set of higher-level tools including Spark SQL for SQL and DataFrames,
8:and Spark Streaming for stream processing.
10:<http://spark.apache.org/>
15:You can find the latest Spark documentation, including a programming
//其它省略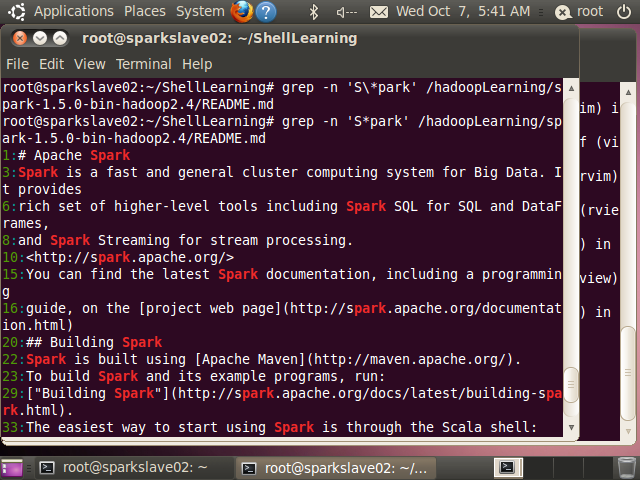
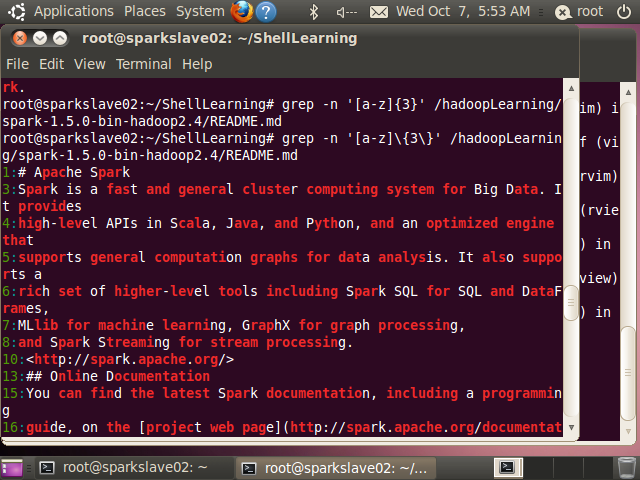
(10) {n},匹配n次
例如[a-z]{3},匹配任意3个小写字母,等同于[a-z][a-z][a-z]
root@sparkslave02:~/ShellLearning# grep -n '[a-z]\{3\}' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
1:# Apache Spark
3:Spark is a fast and general cluster computing system for Big Data. It provides
(11) 其它限定次数匹配
{n, }至少匹配n次
{n, m}至少匹配n次,最多匹配m次
(13) 转义字符\
Ubuntu Linux ?,+,(,), {,}是特殊字符,在使用正则表达式时,如果不加转义符,会匹配将其视为一般字符,如果要设置为正则表达式式符,需要使用\进行转义,前面的例子已经给出示例。
(14) ()匹配一组字符
例如Sp(ar)\?k 匹配Spark和Spk,
root@sparkslave02:~/ShellLearning# echo "Spark Spk Spak" | grep -n 'Sp\(ar\)\?k'
1:Spark Spk Spak
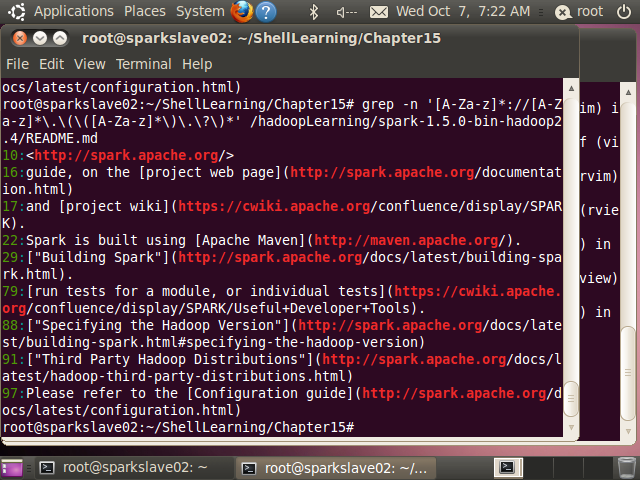
(15) URL匹配实战
root@sparkslave02:~/ShellLearning/Chapter15# grep -n '[A-Za-z]*://[A-Za-z]*\.\(\([A-Za-z]*\)\.\?\)*' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md
上面整个例子可以分下列步骤完成:
(1)匹配http://
root@sparkslave02:~/ShellLearning/Chapter15# grep -n '[A-Za-z]*://' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md 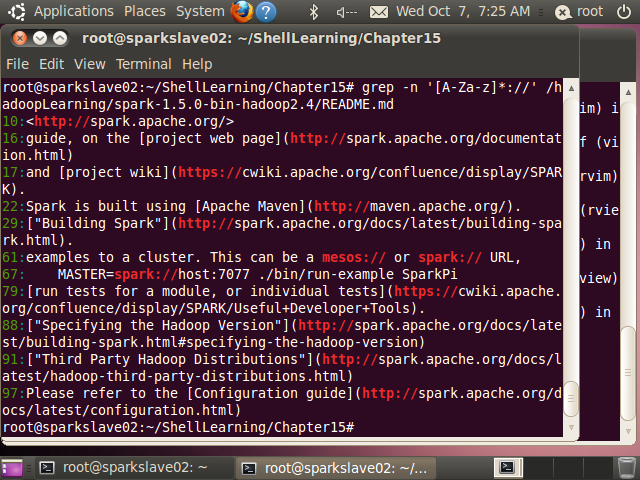
(2)匹配域名
root@sparkslave02:~/ShellLearning/Chapter15# grep -n '[A-Za-z]*://[A-Za-z]*\.[A-Za-z]*' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md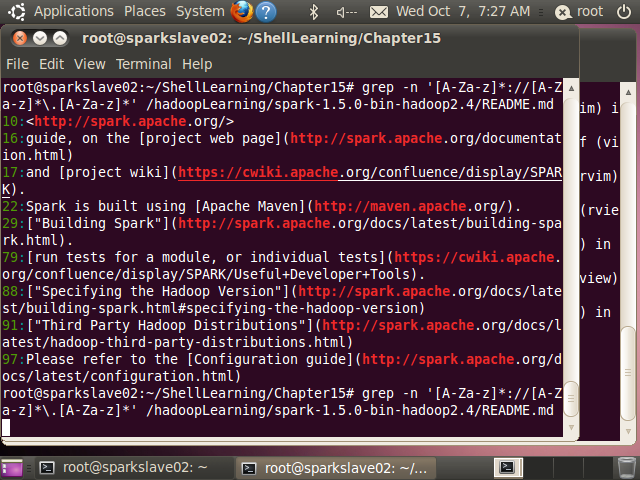
(3)处理重复部分
root@sparkslave02:~/ShellLearning/Chapter15# grep -n '[A-Za-z]*://[A-Za-z]*\.\(\([A-Za-z]*\)\.\?\)*' /hadoopLearning/spark-1.5.0-bin-hadoop2.4/README.md 














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









