







前言
一、 爬虫简介
爬虫:一段自动抓取互联网信息的程序。 简单说,爬虫可以从一个URL出发,访问相关联的url,并且从页面 获取我们需要的有价值的数据。
价值: 互联网数据,为我所用。
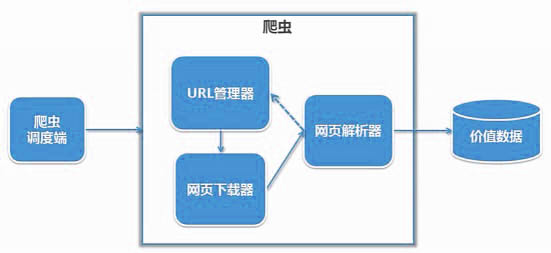
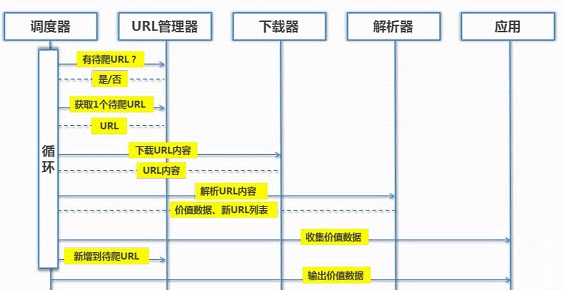
二、简单的爬虫架构
爬虫的调度端: 启动 清理爬虫 或者来监视
三大模块:
URL管理器 :管理已经爬取的URL和未经爬取的URL的管理,取出待爬取的URL传送给网页下载器。
网页下载器:再将网页下载下来 存储成Str 然后传送给网页解析器。
网页解析器:解析出有价值的数据, 另外网页指向其他URL会补充到URL管理器。
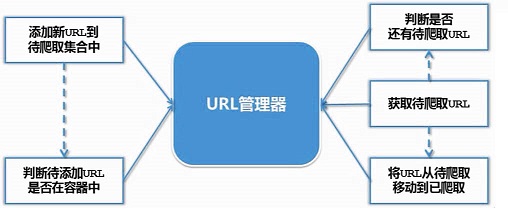
三、URL管理器
用来管理带抓取的URL集合和已抓取的URL集合----为了防止重复抓取、防止循环抓取。
支持的功能:1、添加新的URL到待爬取集合中。并判断是否存在。
2、获取待爬的URL,并判断是否有待爬取的URL。
3、爬区结束后,将URL移动到已爬取的集合中。
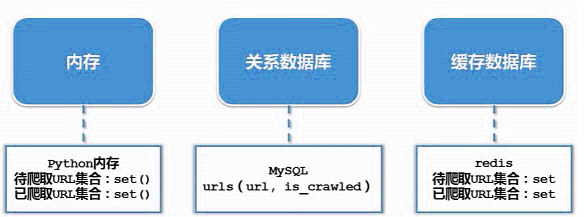
实现的方式:1、内存:将待爬取的URL和已爬取的URl放在集合中。
使用set()--可以去除重复的元素。
2、关系数据库:Create table,采用字段的值来判断URL的状态。
3、缓存数据库:redis--将待爬取的URL和已爬取的URl放在集合中使用set()。
四、网页下载器(urllib.request)
将互联网上URL对应的网页下载到本地的工具。
下载器的种类:1、urllib:python官方基础模块。
2、requests:更强大的第三方插件。
urllib下载网页的方法1:
# 给定URL直接下载 urllib.request.urlopen(url)
improt urllib.request
# 直接请求
response = urllib.request.urlopen("http://www.baidu.com")
# 获取状态码,如果是200表示获取成功
print(response.getcode())
# 读取内容
cont = response.read()urllib下载网页的方法2:
# 添加参数 data、http、header--->urllib.Request--->request.urlopen(req)
from urllib import request, parse
url = "http://httpbin.org/post"
# 伪装一个火狐浏览器
headers = {
"User-Agent":'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
"host":'httpbin.org'
}
# 添加数据
dict = {
"name":"Germey"
}
data = bytes(parse.urlencode(dict),encoding="utf8")
# 创建Requests对象
req = request.Request(url=url, data=data,headers=headers,method="POST")
#发送请求获取结果
response = request.urlopen(req)
print(response.read().decode("utf-8"))urllib下载网页的方法3:
# HTTPCookieProcessor 访问需要登陆的网页,进行Cookie的处理
# ProxyHandler 访问需要代理的网页
# HttpSHandler 访问需要HTTPS加密访问的的网页
# HTTPRedirectHandler 访问需要URL相互自动的跳转关系的网页
# 以上---> opner = urllib2.build_opener(handler)--->urllib2.install_opener(opener)
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)五、网页解析器(BeautifulSoup)
六、完整的实例















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









