







1. 关于用户态协议栈
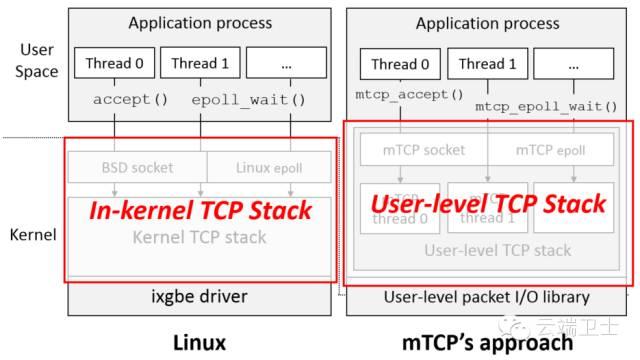
一直以来,网络协议栈都和内核密切相关,内核作为操作系统的控制者,也是负责网络资源分配的最佳人选。随着Linux系统的不断壮大,内核协议栈的功能性能和稳定性都得到了高度认可。
现在互联网业务蒸蒸日上,本该是性能瓶颈的网络传输,被聪明的开发者们通过集群、分布式等方式不断优化,将网络业务的力量不断提高。但随之而来,Linux内核作为一个调度者,不适宜对外提供业务服务,也不适合占用系统资源,无论多么巧妙的开发技巧,都存在面对单点性能瓶颈的问题。
而用户态协议栈,可以让Linux内核更专注系统的控制调度;将复杂的协议处理放到用户态,使用更多的系统资源,提供给开发者更自由的环境,做更多更酷的事~
2. 关于mTCP
关于用户态协议栈已经有很多开源的项目,之所以选mTCP来说,主要觉得其层次结构清晰,便于适配使用。
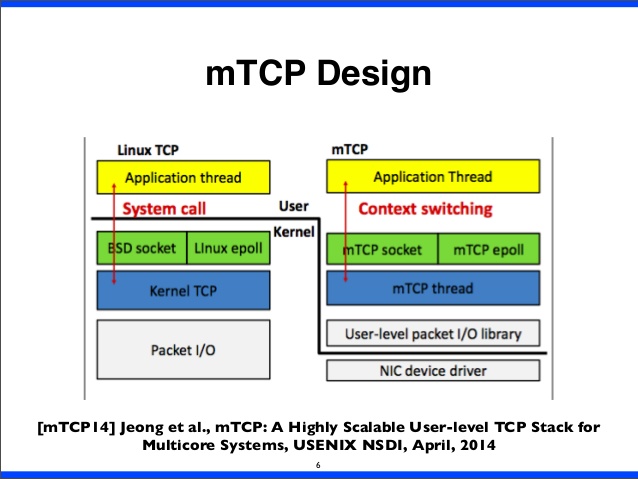
参考其首页描述,将结构分成:IO驱动、mTCP协议栈应用。
mTCP设计模型:
3. 协议栈模型
按描述,mTCP的实现基于RFC793规范,提供了大多数基础tcp功能,以及一些常见的socket套接字配置。TCP协议栈的实现内容较多,有兴趣会另起一个专题详述,当前着重从其模型分析其架构。
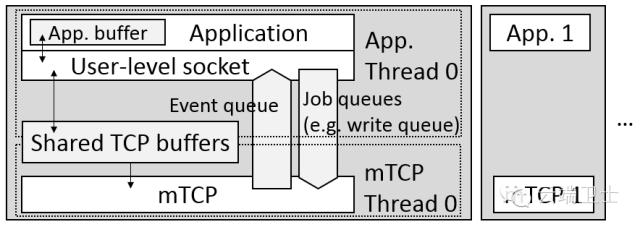
从其提供的结构模型看,实现了:
·传统socket套接字接口,对每条流提供socket形式的抽象。
·线程间有共享内存的使用方法。
·支持epoll相似的批事件处理。
·与mTCP协议栈交互的消息队列机制。
·配置cpu绑定的多线程/进程模型。
按example中epserver的启动过程进行分析,从而了解其内部运作机制。
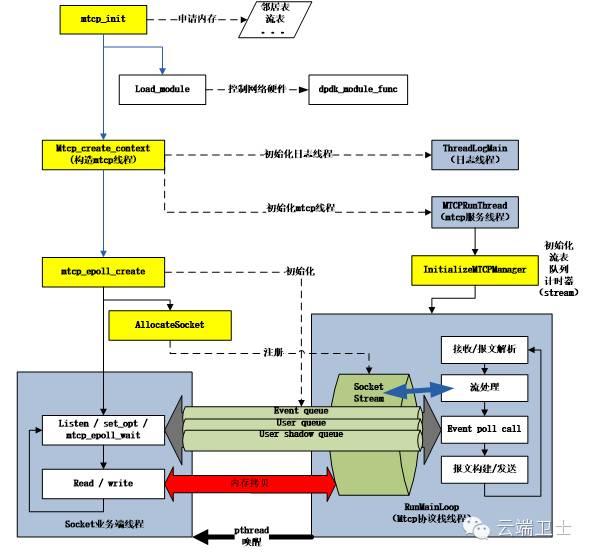
注意:
启动基于mTCP的应用,至少需要三个线程(日志、mTCP协议栈和应用自身)。
如其首页所说,”a separate-TCP-thread-per-application-thread model”。
基于mTCP的应用,read/write依旧会有内存拷贝问题。
Event触发的通知方式,采用pthread唤醒机制。
由于app线程和mTCP线程一对一,其协议栈设计为仅支持一个epoll服务注册。
4. IO驱动
mTCP提供两种方式:
·根据intel网卡驱动igb/ixgbe改进的PSIO(PacketShader I/O engine)。
·基于intel的DPDK(DATA PLANE DEVELOPMENT KIT)进行适配的驱动。
这里选用了基于DPDK的IO驱动,因为PSIO的支持依赖内核版本。DPDK是一套用户态高性能网络设备开发工具,在用户态就可以控制和使用网卡硬件资源。(DPDK本身非常强大,这里就不详细分析了……)
使用中发现,mTCP对DPDK进行了一小部分拓展:被igb_uio驱动绑定的硬件设备,自动为其在Linux上注册为网络设备,被用作配置接口(如ifconfig命令配置ip等)。
5. 为何高性能
由模型来分析,其内存管理机制,没有实现”零拷贝”;其线程调度也较为传统。没有这些较热门的技术,其为何可以提高数倍于传统协议栈的性能?抛开mTCP协议栈性能的优化,其高性能更依赖其用户态的多核架构设计。
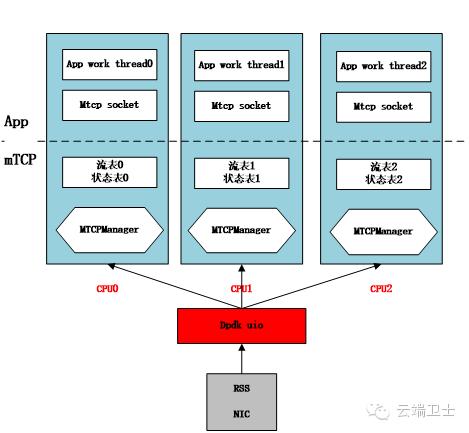
CPU设置线程亲和性;降低cache miss,提高资源利用率。
每个线程独立状态信息;大大降低因信息同步而使用锁的场景。
利用网卡硬件基于rss进行分流(五元组);确保每个线程只处理属于自己的流。
用户态应用;降低了传统socket系统调用的额外开销。
6. 测试对比
mTCP自带了一些用例,其中包含集成好的lighttpd和ab(ApacheBench)。
我采用了ab来进行测试,不同版本的ab,分别访问一台nginx服务器的静态页面,根据ab自身信息来查看并发性能和mTCP效果。
·环境:两台E5-2690,64G内存服务器 x520网口对接
·参数:ab -n 200000 -c 10000 http://111.11.1.1/index.html
·方法:分别用传统协议栈ab,mTCP版ab,对nginx服务器做测试。
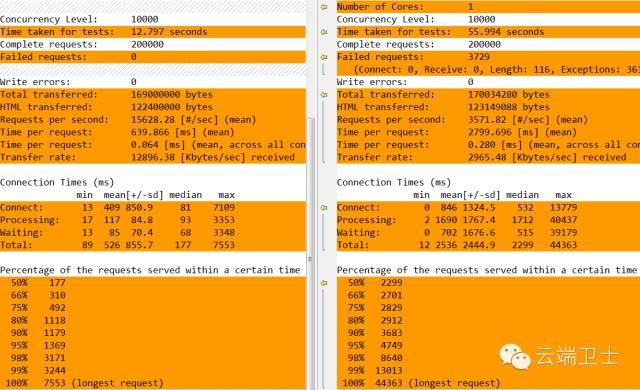
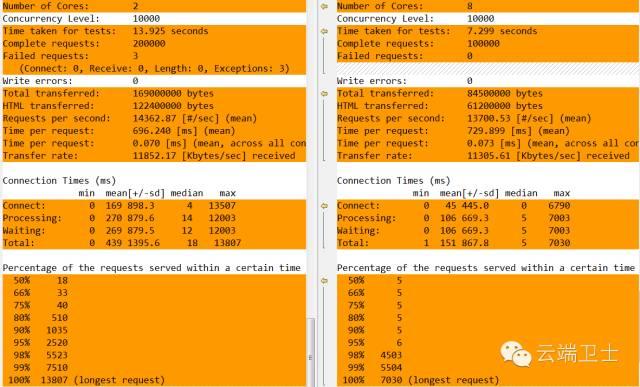
每个用例运行10次,平均结果如下图,分别是传统协议栈的ab,和配置1,2,8个核的mTCP版ab。
mTCP单核性能比传统协议栈差很多,但由于支持多核架构,多核版的处理能力高于传统协议栈。
mTCP协议栈在异常状态处理上还有所不足,出现了一些Failed requests。
7. 结语
mTCP的结构简洁,层次分明。由于时间问题,还没有做针对性的功能和性能测试- -,有机会后面会有更详尽的补充。
通过上面的描述,可见其有符合未来高性能架构的基础。而且内存操作和线程调度上,还有提升的潜力。
但分流策略依赖硬件配置,intel网口不同芯片支持的队列数也是0~16不等,使用时需要考虑自己的平台规格,对架构设计者要求较高。
要想做一个高性能网络服务端,mTCP+DPDK的组合可以作为一个学习优化定制的起点。















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









