







总结一下,理解算法时的几个问题,搞懂这些基本上就算理解Swift rebalnce的算法了。
Swift如何保证文件的随机存储和保持系统中的平衡性?
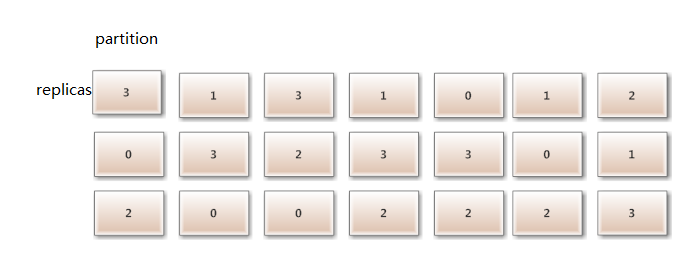
例如有4台dev(编号 0,1, 2, 3)2的18次幂262144虚节点,我们都知道builder和ring中存储了一个数据结构_replica2part2dev,它表明了partition到replica到dev的映射关系,即某个文件的某个副本存储到哪个dev上,如下图
系统要做的是根据策略来生成随机的分布,让一个文件的三个副本可以存储到3个不同的dev上去。
builder文件到底存的什么?
其实builder文件里存储了一个字典型的数据结构,其中包含了整个系统所有的重要的数据。
'part_power': self.part_power,
'replicas': self.replicas,
'min_part_hours': self.min_part_hours,
'parts': self.parts,
'devs': self.devs,
'devs_changed': self.devs_changed,
'version': self.version,
'_replica2part2dev': self._replica2part2dev,
'_last_part_moves_epoch': self._last_part_moves_epoch,
'_last_part_moves': self._last_part_moves,
'_last_part_gather_start': self._last_part_gather_start,
'_remove_devs': self._remove_devsring文件里到底存了什么?
ring文件只存储记录part分布的数据
def serialize_v1(self, file_obj):
# Write out new-style serialization magic and version:
file_obj.write(struct.pack('!4sH', 'R1NG', 1))
ring = self.to_dict()
json_text = json.dumps(
{'devs': ring['devs'], 'part_shift': ring['part_shift'],
'replica_count': len(ring['replica2part2dev_id'])})
json_len = len(json_text)
file_obj.write(struct.pack('!I', json_len))
file_obj.write(json_text)
for part2dev_id in ring['replica2part2dev_id']:
file_obj.write(part2dev_id.tostring())文件对应的part如何生成
一个上传文件的请求,proxy会来决定哪个node(dev)来存储这个文件和它的副本。然后向选好的dev发送请求。
例如 admin账户,向test容器中,上传一个名字为update.c的文件。会根据/admin/test/update.c + 设置的HASH_PATH_SUFFIX 生成一个md5 的值 然后解析成一个数字 例如35564 这个就是part,然后在_replica2part2dev 中查找它的三个replica所在的dev ,然后向这三个dev发送请求。
def get_nodes(self, account, container=None, obj=None):
key = hash_path(account, container, obj, raw_digest=True)
#md5(/account/contianer/obj + HASH_PATH_SUFFIX).digest()
if time() > self._rtime:
self._reload()
part = struct.unpack_from('>I', key)[0] >> self._part_shift
seen_ids = set()
return part, [self._devs[r[part]] for r in self._replica2part2dev_id
if not (r[part] in seen_ids or seen_ids.add(r[part]))]sort_key
dev对应的sort_key影响它分配的方式,系统生成一个字符串,它分成三段,进行排序,第一段为dev_want,第二段随机数,第三段dev_id,系统根据这个三段排序,然后查找最想want的dev
def _sort_key_for(self, dev):
# The maximum value of self.parts is 2^32, which is 9 hex
# digits wide (0x100000000). Using a width of 16 here gives us
# plenty of breathing room; you'd need more than 2^28 replicas
# to overflow it.
# Since the sort key is a string and therefore an ascii sort applies,
# the maximum_parts_wanted + parts_wanted is used so negative
# parts_wanted end up sorted above positive parts_wanted.
return '%016x.%04x.%04x' % (
(self.parts * self.replicas) + dev['parts_wanted'],
randint(0, 0xffff),
dev['id'])parts_wanted = (sum_part/sum_weight )*dev_weith-dev_pars
系统设置的part减去已经分配的part 生成想要得到的part















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









