







在之前的分析中,生成ring文件通过builder.py中的rebalance方法,最终调用 _reassign_parts 方法,下面我来详细的分析下reassign的过程,顾名思义,就是从新分配parts的过程,无论是第一次rebalance还是修改后重新rebalance ,最终都是通过这个函数。
要了解其中的算法,首先要懂一些概念性的东西,比如说RingBuilder类的构造方法__init__方法中有这个一个设置,
self._replica2part2dev = None,这其实就是part到dev的映射(事实上就是一个二维数组)dev = _replica2part2dev[replica][part],代表某个part的某个replica属于某个dev,其实就是,某个文件的某个副本存储在某个设备上。 而我们要做的就是初始化/重新分配 这个二维数组,根据设计理念制定逻辑,然后通过算法实现这些逻辑。
如何决定一个replica到底放在哪个dev中呢? Swift把一个dev划分成三层结构 第一层根据zone划分,第二层根据ip port划分,第三层根据dev id划分,然后保证一个part的replicas要放到不同的zone的不同ip port下的不用dev id 上,
同时根据weight 和已经拥有的replica等属性,进行排序,让replica到当前满足划分条件,又最有需求的 dev 上去,三层图如下:
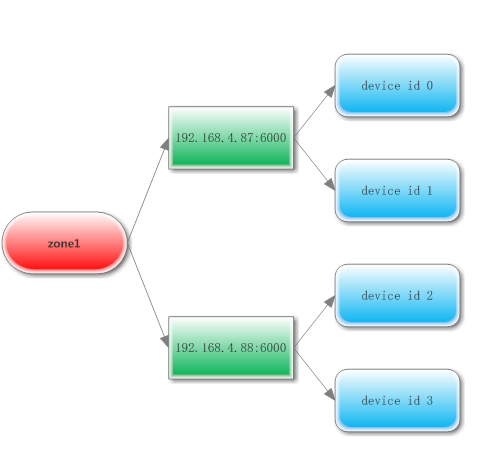
/swfit/common/ring/utils下有这两个方法,这两个方法非常的重要,
def tiers_for_dev(dev):
"""
Returns a tuple of tiers for a given device in ascending order by
length.
:returns: tuple of tiers
"""
t1 = dev['zone']
t2 = "{ip}:{port}".format(ip=dev.get('ip'), port=dev.get('port'))
t3 = dev['id']
return ((t1,),
(t1, t2),
(t1, t2, t3))
def build_tier_tree(devices):
tier2children = defaultdict(set)
for dev in devices:
for tier in tiers_for_dev(dev):
if len(tier) > 1:
tier2children[tier[0:-1]].add(tier)
else:
tier2children[()].add(tier)
return tier2children
下面是源码分析:
def _reassign_parts(self, reassign_parts):
"""
For an existing ring data set, partitions are reassigned similarly to
the initial assignment. The devices are ordered by how many partitions
they still want and kept in that order throughout the process. The
gathered partitions are iterated through, assigning them to devices
according to the "most wanted" while keeping the replicas as "far
apart" as possible. Two different zones are considered the
farthest-apart things, followed by different ip/port pairs within a
zone; the least-far-apart things are different devices with the same
ip/port pair in the same zone.
If you want more replicas than devices, you won't get all your
replicas.
:param reassign_parts: An iterable of (part, replicas_to_replace)
pairs. replicas_to_replace is an iterable of the
replica (an int) to replace for that partition.
replicas_to_replace may be shared for multiple
partitions, so be sure you do not modify it.
"""
for dev in self._iter_devs():#数据结构的初始化,可用的dev初始化,包括它的排序,各个层结构的初始化,做这些的目的只有一个,为后面分配part提供策略上的支持。
dev['sort_key'] = self._sort_key_for(dev)#个体dev添加sort_key属性
available_devs = \
sorted((d for d in self._iter_devs() if d['weight']),#通过sort_key排序dev
key=lambda x: x['sort_key'])
tier2children = build_tier_tree(available_devs)#三层结构初始化
tier2devs = defaultdict(list)
tier2sort_key = defaultdict(list)
tiers_by_depth = defaultdict(set)
for dev in available_devs:
for tier in tiers_for_dev(dev):
tier2devs[tier].append(dev) # <-- starts out sorted!#dev层
tier2sort_key[tier].append(dev['sort_key'])#sort_key
tiers_by_depth[len(tier)].add(tier)#层的深度
for part, replace_replicas in reassign_parts:#dev的层结构,这里收集不需要被move的replicas
# Gather up what other tiers (zones, ip_ports, and devices) the
# replicas not-to-be-moved are in for this part.
other_replicas = defaultdict(lambda: 0)
for replica in xrange(self.replicas):
if replica not in replace_replicas:
dev = self.devs[self._replica2part2dev[replica][part]]
for tier in tiers_for_dev(dev):
other_replicas[tier] += 1
def find_home_for_replica(tier=(), depth=1):#根据策略找找合适的dev
# Order the tiers by how many replicas of this
# partition they already have. Then, of the ones
# with the smallest number of replicas, pick the
# tier with the hungriest drive and then continue
# searching in that subtree.
#
# There are other strategies we could use here,
# such as hungriest-tier (i.e. biggest
# sum-of-parts-wanted) or picking one at random.
# However, hungriest-drive is what was used here
# before, and it worked pretty well in practice.
#
# Note that this allocator will balance things as
# evenly as possible at each level of the device
# layout. If your layout is extremely unbalanced,
# this may produce poor results.
candidate_tiers = tier2children[tier]#通过三层结构,查找做少的,需求最大的dev
min_count = min(other_replicas[t] for t in candidate_tiers)
candidate_tiers = [t for t in candidate_tiers
if other_replicas[t] == min_count]
candidate_tiers.sort(
key=lambda t: tier2sort_key[t][-1])
if depth == max(tiers_by_depth.keys()):
return tier2devs[candidate_tiers[-1]][-1]
return find_home_for_replica(tier=candidate_tiers[-1],
depth=depth + 1)
for replica in replace_replicas:
dev = find_home_for_replica()#找位置
dev['parts_wanted'] -= 1
dev['parts'] += 1
old_sort_key = dev['sort_key']
new_sort_key = dev['sort_key'] = self._sort_key_for(dev)
for tier in tiers_for_dev(dev):
other_replicas[tier] += 1
index = bisect.bisect_left(tier2sort_key[tier],#这里是移除之前的sort_key,在相同的排序下插入新的sort_key
old_sort_key)
tier2devs[tier].pop(index)
tier2sort_key[tier].pop(index)
new_index = bisect.bisect_left(tier2sort_key[tier],
new_sort_key)
tier2devs[tier].insert(new_index, dev)
tier2sort_key[tier].insert(new_index, new_sort_key)
self._replica2part2dev[replica][part] = dev['id']
# Just to save memory and keep from accidental reuse.
for dev in self._iter_devs():
del dev['sort_key']














 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









