







一、什么是FSImage和EditsLog
我们知道HDFS是一个分布式文件存储系统,文件分布式存储在多个DataNode节点上。一个文件存储在哪些DataNode节点的哪些位置的元数据信息(metadata)由NameNode节点来处理。随着存储文件的增多,NameNode上存储的信息也会越来越多。那么HDFS是如何及时更新这些metadata的呢?
在HDFS中主要是通过两个组件FSImage和EditsLog来实现metadata的更新。在某次启动HDFS时,会从FSImage文件中读取当前HDFS文件的metadata,之后对HDFS的操作步骤都会记录到edit log文件中。比如下面这个操作过程
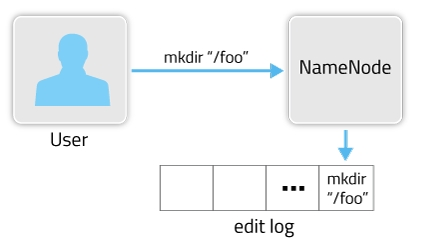
那么完整的metadata信息就应该由FSImage文件和edit log文件组成。fsimage中存储的信息就相当于整个hdfs在某一时刻的一个快照。
FSImage文件和EditsLog文件可以通过ID来互相关联。在参数dfs.namenode.name.dir设置的路径下,会保存FSImage文件和EditsLog文件,如果是QJM方式HA的话,EditsLog文件保存在参数dfs.journalnode.edits.dir设置的路径下。
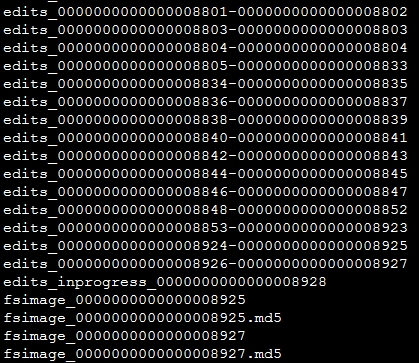
在上图中可以看到,edit log文件以edits_开头,后面跟一个txid范围段,并且多个edit log之间首尾相连,正在使用的edit log名字为edits_inprogress_txid。该路径下还会保存两个fsimage文件,文件格式为fsimage_txid。上图中可以看出fsimage文件已经加载到了最新的一个edit log文件,仅仅只有inprogress状态的edit log未被加载。在启动HDFS时,只需要读入fsimage_0000000000000008927以及edits_inprogress_0000000000000008928就可以还原出当前hdfs的最新状况。
但是这里又会出现一个问题,如果edit log文件越来越多、越来越大时,当重新启动hdfs时,由于需要加载fsimage后再把所有的edit log也加载进来,就会出现第一段中出现的问题了。怎么解决?HDFS会采用checkpoing机制定期将edit log合并到fsimage中生成新的fsimage。这个过程就是接下来要讲的了。
二、Checkpoint机制
fsimage和edit log合并的过程如下图所示:
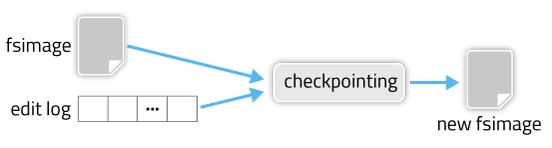
其实这个合并过程是一个很耗I/O与CPU的操作,并且在进行合并的过程中肯定也会有其他应用继续访问和修改hdfs文件。所以,这个过程一般不是在单一的NameNode节点上进行从。如果HDFS没有做HA的话,checkpoint由SecondNameNode进程(一般SecondNameNode单独起在另一台机器上)来进行。在HA模式下,checkpoint则由StandBy状态的NameNode来进行。
什么时候进行checkpoint由两个参数dfs.namenode.checkpoint.preiod(默认值是3600,即1小时)和dfs.namenode.checkpoint.txns(默认值是1000000)来决定。period参数表示,经过1小时就进行一次checkpoint,txns参数表示,hdfs经过100万次操作后就要进行checkpoint了。这两个参数任意一个得到满足,都会触发checkpoint过程。进行checkpoint的节点每隔dfs.namenode.checkpoint.check.period(默认值是60)秒就会去统计一次hdfs的操作次数。
三、HA模式下Checkpointing过程分析
在HA模式下checkpoint过程由StandBy NameNode来进行,以下简称为SBNN,Active NameNode简称为ANN。
HA模式下的edit log文件会同时写入多个JournalNodes节点的dfs.journalnode.edits.dir路径下,JournalNodes的个数为大于1的奇数,类似于Zookeeper的节点数,当有不超过一半的JournalNodes出现故障时,仍然能保证集群的稳定运行。
SBNN会读取FSImage文件中的内容,并且每隔一段时间就会把ANN写入edit log中的记录读取出来,这样SBNN的NameNode进程中一直保持着hdfs文件系统的最新状况namespace。当达到checkpoint条件的某一个时,就会直接将该信息写入一个新的FSImage文件中,然后通过HTTP传输给ANN。
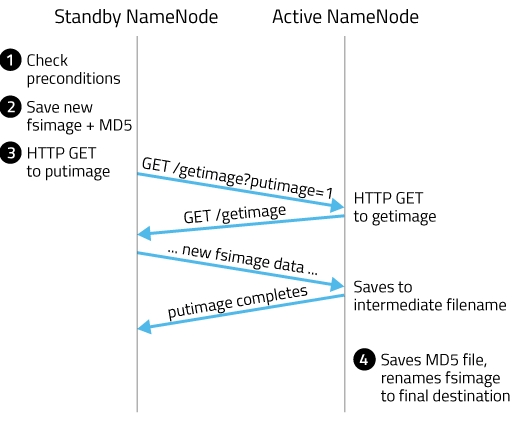
如上图所示,主要由4个步骤:
1. SBNN检查是否达到checkpoint条件:离上一次checkpoint操作是否已经有一个小时,或者HDFS已经进行了100万次操作。
2. SBNN检查达到checkpoint条件后,创建一个新的编辑日志文件edits.new,后续对文件系统的任何修改都记录到这个新编辑日志里。
3.将Namenode上的fsimage文件和原编辑日志下载到本地,并在内存中合并,合并的结果输出为fsimage.ckpt,并且随之生成一个MD5文件。
4. 再次发起请求通知ANN节点数据(fsimage.ckpt)已准备好,然后ANN节点会下载fsimage.ckpt文件并保存为fsimage.ckpt_txid。
5.然后也生成一个MD5,将这个MD5与SBNN的MD5文件进行比较,确认ANN已经正确获取到了SBNN最新的fsimage文件。然后将fsimage.ckpt_txid文件重命名为fsimage_txit。
6.将新的编辑日志edits.new改名为edits。
通过上面一系列的操作,SBNN上最新的FSImage文件就成功同步到了ANN上。
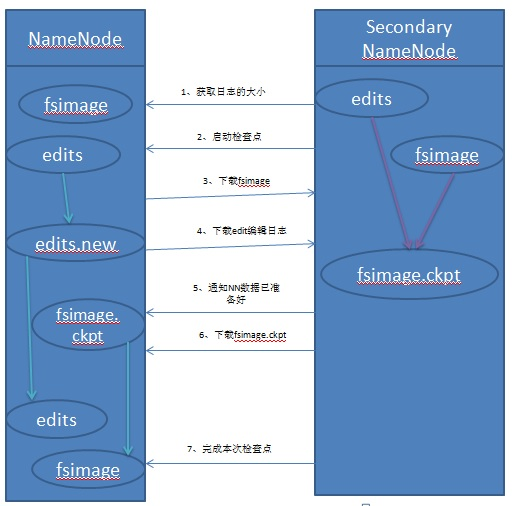
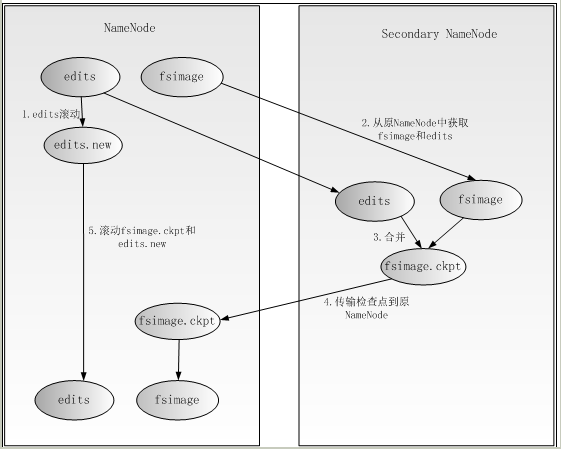
附:参考流程:















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









