






引入maven包
org.apache.kafka
kafka-clients
0.11.0.1
一、同步发送消息
1、创建topic:
./bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --partitions 3 --replication-factor 1 --topic test-syn
2、代码
package com.example.demo.test;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SynProducer {
private static Properties getProps(){
Properties props = new Properties();
props.put("bootstrap.servers", "47.52.199.51:9092");
props.put("acks", "all"); // 发送所有ISR
props.put("retries", 2); // 重试次数
props.put("batch.size", 16384); // 批量发送大小
props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送
props.put("client.id", "producer-syn-1"); // 发送端id,便于统计
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
public static void main(String[] args) {
KafkaProducer producer = new KafkaProducer<>(getProps());
for(int i=0; i< 1000; i++){
// 三个参数,topic,key:用户分配partition,value:发送的值
ProducerRecord record = new ProducerRecord<>("test-syn", "topic_"+i,"test-syn-"+i);
Future metadataFuture = producer.send(record);
RecordMetadata recordMetadata = null;
try {
recordMetadata = metadataFuture.get();
System.out.println("发送成功!");
System.out.println("topic:"+recordMetadata.topic());
System.out.println("partition:"+recordMetadata.partition());
System.out.println("offset:"+recordMetadata.offset());
} catch (InterruptedException|ExecutionException e) {
System.out.println("发送失败!");
e.printStackTrace();
}
}
producer.flush();
producer.close();
}
}
3、测试
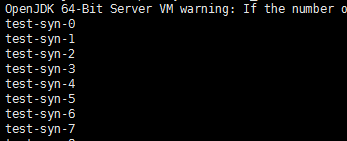
1、创建consumer
./bin/kafka-console-consumer.sh --bootstrap-server 47.52.199.52:9092 --topic test-syn --group test-1 --from-beginning
2、运行程序
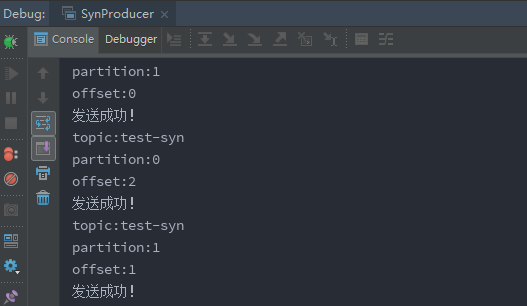
二、异步发送消息
packagecom.example.demo.test;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerRecord;importjava.util.Properties;public classASynProducer {private staticProperties getProps(){
Properties props= newProperties();
props.put("bootstrap.servers", "47.52.199.51:9092");
props.put("acks", "all"); //发送所有ISR
props.put("retries", 2); //重试次数
props.put("batch.size", 16384); //批量发送大小
props.put("buffer.memory", 33554432); //缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); //发送频率,满足任务一个条件发送
props.put("client.id", "producer-asyn-1"); //发送端id,便于统计
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");returnprops;
}public static voidmain(String[] args) {
KafkaProducer producer = new KafkaProducer<>(getProps());for(int i=0; i< 1000; i++){
ProducerRecord record = new ProducerRecord<>("test-asyn", "topic_"+i,"test-asyn-"+i);//相比同步发送,异步发送需要传入callback,发送结果回来回调callback方法
producer.send(record, (recordMetadata, e) ->{if(e != null){
System.out.println("发送失败!");
e.printStackTrace();
}else{
System.out.println("发送成功!");
System.out.println("topic:"+recordMetadata.topic());
System.out.println("partition:"+recordMetadata.partition());
System.out.println("offset:"+recordMetadata.offset());
}
});
}
producer.flush();
producer.close();
}
}
三、及时发送消息
相比前两种方式,该方式不关心结果,只管发送,所以比较快。
packagecom.example.demo.test;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerRecord;importjava.util.Properties;public classFireProducer {private staticProperties getProps(){
Properties props= newProperties();
props.put("bootstrap.servers", "47.52.199.51:9092");
props.put("acks", "all"); //发送所有ISR
props.put("retries", 2); //重试次数
props.put("batch.size", 16384); //批量发送大小
props.put("buffer.memory", 33554432); //缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); //发送频率,满足任务一个条件发送
props.put("client.id", "producer-syn-1"); //发送端id,便于统计
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");returnprops;
}public static voidmain(String[] args) {
KafkaProducer producer = new KafkaProducer<>(getProps());for(int i=0; i< 1000; i++){
ProducerRecord record = new ProducerRecord<>("test-syn", "topic_"+i,"test-syn-"+i);//不关心发送结果
producer.send(record);
}
producer.flush();
producer.close();
}
}
四、自动提交offset
packagecom.example.demo.consumer;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importjava.util.ArrayList;importjava.util.List;importjava.util.Properties;/***@author王柱星
*@version1.0
* @title
* @time 2018年12月11日
*@since1.0*/
public classAutoCommitConsumer {private staticProperties getProps(){
Properties props= newProperties();
props.put("bootstrap.servers", "47.52.199.52:9092");
props.put("group.id", "test_3");
props.put("session.timeout.ms", 30000); //如果其超时,将会可能触发rebalance并认为已经死去,重新选举Leader
props.put("enable.auto.commit", "true"); //开启自动提交
props.put("auto.commit.interval.ms", "1000"); //自动提交时间
props.put("auto.offset.reset","earliest"); //从最早的offset开始拉取,latest:从最近的offset开始消费
props.put("client.id", "producer-syn-1"); //发送端id,便于统计
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");returnprops;
}public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);//拉取任务超时时间
for(;;){
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}
}
}
}
}
五、同步提交
同步提交,提交后broke会阻塞等结果返回,在成功提交或碰到无怯恢复的错误之前,commitSync()会一直重试
packagecom.example.demo.consumer;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importjava.util.ArrayList;importjava.util.List;importjava.util.Properties;/***@author王柱星
*@version1.0
* @title
* @time 2018年12月11日
*@since1.0*/
public classCommitConsumer {private staticProperties getProps(){
Properties props= newProperties();
props.put("bootstrap.servers", "47.52.199.51:9092");
props.put("group.id", "test_3");
props.put("session.timeout.ms", 30000); //如果其超时,将会可能触发rebalance并认为已经死去,重新选举Leader
props.put("enable.auto.commit", "false"); //开启自动提交
props.put("auto.commit.interval.ms", "1000"); //自动提交时间
props.put("auto.offset.reset","earliest"); //从最早的offset开始拉取,latest:从最近的offset开始消费
props.put("client.id", "consumer-2"); //发送端id,便于统计
props.put("max.poll.records","1000"); //每次批量拉取条数
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");returnprops;
}public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}//当前批次offset
consumer.commitSync();
}
}
}
}
六、异步提交
commitAsync()方法提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,commitSync()会一直重试,但是commitAsync()不会,这也是commitAsync()不好的一个地方。它之所以不进行重试,是因为在它收到服务器响应的时候, 可能有一个更大的偏移量已经提交成功。假设我们发出一个请求用于提交偏移量2000,这个时候发生了短暂的通信问题,服务器收不到请求,自然也不会作出任何响应。与此同时,我们处理了另外一批消息,并成功提交了偏移量3000。如果commitAsync()重新尝试提交偏移量2000 ,它有可能在偏移量3000之后提交成功。系统会记录最后提交的偏移量,这个时候如果发生再均衡,就会出现重复消息,会从2000开始。
public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}//当前批次offset
consumer.commitAsync();
}
}
}
异步提交支持回调方法,可以记录提交错误的值
public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}//当前批次offset
consumer.commitAsync((map, e) ->{if(e != null){
System.out.println("提交失败:"+map.get(""));
}
});
}
}
}
七、同步和异步组合提交
packagecom.example.demo.consumer;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importjava.util.ArrayList;importjava.util.List;importjava.util.Properties;/***@author王柱星
*@version1.0
* @title
* @time 2018年12月11日
*@since1.0*/
public classCommitAsynCallbackConsumer {private staticProperties getProps(){
Properties props= newProperties();
props.put("bootstrap.servers", "47.52.199.51:9092");
props.put("group.id", "test_4");
props.put("session.timeout.ms", 30000); //如果其超时,将会可能触发rebalance并认为已经死去,重新选举Leader
props.put("enable.auto.commit", "false"); //开启自动提交
props.put("auto.commit.interval.ms", "1000"); //自动提交时间
props.put("auto.offset.reset","earliest"); //从最早的offset开始拉取,latest:从最近的offset开始消费
props.put("client.id", "consumer-3"); //发送端id,便于统计
props.put("max.poll.records","200"); //每次批量拉取条数
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");returnprops;
}public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}//当前批次offset
consumer.commitAsync((map, e) ->{if(e != null){
System.out.println("提交失败:"+map.get(""));
}
});
}
}
}
}
八、提交到特定的partition、偏移量
public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}
Map offsets = new HashMap<>();//指定topic 、partition
TopicPartition topicPartition = new TopicPartition("producer-syn",0);//指定offset
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(100);//可以提交多个topic
offsets.put(topicPartition, offsetAndMetadata);//提交offset
consumer.commitSync(offsets);
}
}
}
为提高消费吞吐量,可使用线程处理,消费者只负责接收消息,由线程池处理。
九、从特定偏移量处开始消费
前面都是consumer.poll()之后读取该批次的消息,kafka还提供了从分区的开始或者末尾读消息的功能:
seekToEnd(Collectionpartitions)
seekToBeginning(Collection partitions)
另外kafka还提供了从指定偏移量处读取消息,可以通过seek()方法来处理:
// 只有先pull一次,seek才会生效,启动后第一次拉取不返回数据
seek(TopicPartition partition, long offset)
示例:
public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
TopicPartition topicPartition= new TopicPartition("producer-syn",0);
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}//只有先pull一次,seek才会生效,启动后第一次拉取不返回数据
consumer.seek(topicPartition,100L);//new ArrayList<>(topicPartition)
List list = new ArrayList<>();
list.add(topicPartition);//consumer.seekToEnd(list);//consumer.seekToBeginning(list);
consumer.commitSync();
}
}
}
十、从特定时间开始消费
offsetsForTimes(java.util.Map)
入参:parttition、时间戳
返回:响应的offset
调用 seek(TopicPartition partition, long offset)开始消费
示例:
public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
TopicPartition topicPartition= new TopicPartition("producer-syn",0);
List topics = new ArrayList<>();
topics.add("producer-syn");
consumer.subscribe(topics);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}
Map timestampsToSearch = new HashMap<>();//通过时间戳获取offset
timestampsToSearch.put(topicPartition,1544594780946L);
Map timestampMap =consumer.offsetsForTimes(timestampsToSearch);//指定offset
consumer.seek(topicPartition,timestampMap.get(topicPartition).offset());
consumer.commitSync();
}
}
}
其他场景:
通过时间戳查询指定分区的offsets,前后两个时间戳就是指定的时间段,所有分区相加就是指定的主题。所以可以通过时间戳查询指定分区的offsets方法来查询指定时间段内指定主题的偏移量。结果可以用来核对生产或者同步的消息数量。
十一、监听rebalance提交
前面我们说过当发生consumer退出或者新增,partition新增的时候会触发再均衡。那么发生再均衡的时候如果某个consumer正在消费的任务没有消费完该如何提交当前消费到的offset呢?kafka提供了再均衡监听器,在发生再均衡之前监听到,当前consumer可以在失去分区所有权之前处理offset关闭句柄等。
消费者API中有一个()方法:
subscribe(Collection var1, ConsumerRebalanceListener var2);
ConsumerRebalanceListener对象就是监听器的接口对象,我们需要实现自己的监听器继承该接口。接口里面有两个方法需要实现:
void onPartitionsRevoked(Collectionvar1);void onPartitionsAssigned(Collection var1);
第一个方法会在再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管分区的消费者就知道该从哪里开始读取了。
第二个会在重新分配分区之后和消费者开始读取消息之前被调用。
示例:
public static voidmain(String[] args) {
KafkaConsumer consumer = new KafkaConsumer<>(getProps()) ;
List topics = new ArrayList<>();
topics.add("test-syn");//指定offset
Map currentOffset = new HashMap<>();
consumer.subscribe(topics,newConsumerRebalanceListener() {
@Overridepublic void onPartitionsRevoked(Collectioncollection) {
System.out.println("发生rebalance!提交:"+currentOffset);
consumer.commitAsync(currentOffset,null);
}
@Overridepublic void onPartitionsAssigned(Collectioncollection) {
}
});for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);
Long offset= 0L;for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
offset=consumerRecord.offset();
}
TopicPartition topicPartition= new TopicPartition("test-syn",0);
OffsetAndMetadata offsetAndMetadata= newOffsetAndMetadata(offset);
currentOffset.put(topicPartition, offsetAndMetadata);
consumer.commitSync();
}
}
十二、主动分配分区消费
到目前为止我们讨论的都是消费者群组,分区被自动分配给群组的消费者,群组的消费者有变动会触发再均衡。那么是不是可以回归到别的消息队列的方式:不需要群组消费者也可以自己订阅主题?
kafka也提供了这样的案例,因为kafka的主题有分区的概念,那么如果没有群组就意味着你的自己订阅到特定的一个分区才能消费内容。如果是这样的话,就不需要订阅主题,而是为自己分配分区。一个消费者可以订阅主题(并加入消费者群组),或者为自己分配分区,但不能同时做这两件事情。注:group.id配置不能与其他consumer重复,否则会报错,直接去掉也行。
packagecom.example.demo.consumer;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.ConsumerRecords;importorg.apache.kafka.clients.consumer.KafkaConsumer;importorg.apache.kafka.common.PartitionInfo;importorg.apache.kafka.common.TopicPartition;importjava.util.ArrayList;importjava.util.List;importjava.util.Map;importjava.util.Properties;/***@author王柱星
*@version1.0
* @title
* @time 2018年12月11日
*@since1.0*/
public classPartitionConsumer {private staticProperties getProps(){
Properties props= newProperties();
props.put("bootstrap.servers", "47.52.199.51:9092");
props.put("session.timeout.ms", 30000); //如果其超时,将会可能触发rebalance并认为已经死去,重新选举Leader
props.put("enable.auto.commit", "false"); //开启自动提交
props.put("auto.commit.interval.ms", "1000"); //自动提交时间
props.put("auto.offset.reset","earliest"); //从最早的offset开始拉取,latest:从最近的offset开始消费
props.put("client.id", "consumer-3"); //发送端id,便于统计
props.put("max.poll.records","200"); //每次批量拉取条数
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");returnprops;
}public static voidmain(String[] args) {try (KafkaConsumer consumer = new KafkaConsumer<>(getProps())) {
List partitionInfoList = consumer.partitionsFor("test-syn");
List topicPartitionList = new ArrayList<>();if(partitionInfoList != null){for(PartitionInfo partitionInfo : partitionInfoList){
topicPartitionList.add(newTopicPartition(partitionInfo.topic(),partitionInfo.partition()));
consumer.assign(topicPartitionList);
}
}
Map map=consumer.metrics();
System.out.println(map);for(;;){//拉取任务超时时间
ConsumerRecords records = consumer.poll(1000);for(ConsumerRecord consumerRecord : records){
System.out.println("partition:"+consumerRecord.partition());
System.out.println("offset:"+consumerRecord.offset());
System.out.println("key:"+consumerRecord.key());
System.out.println("value:"+consumerRecord.value());
}
consumer.commitSync();
}
}
}
}
注:
consumer.partitionsFor(“主题”)方法允许我们获取某个主题的分区信息。
知道想消费的分区后使用assign()手动为该消费者分配分区。














 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









