






摘要:
语言学知识对各种自然语言处理任务都是有用的,但难点在于表达 和应用。我们认为语言知识隐含在大规模语料库中,而分类知识,即与 实体和关系类型的定义相关的知识,隐含在标记的训练数据中。因此, 提出了一个语料库子图来从容易获取的未标记数据中挖掘更多的语言知 识,并使用句子子图来获取分类知识。它们共同构成了一个关系知识图 (RKG),用于从本文的句子中提取关系。在 RKG,实体识别可视为属性值 填充问题,关系分类可视为链接预测问题。因此,多重关系抽取可以被 视为知识完成的推理过程。我们将统计推理和神经网络推理相结合,将 句子分割成实体组块和非实体组块,然后提出一种新的组块图 LSTM 网络 来学习实体组块的表示并推断它们之间的关系。在两个标准数据集上的 实验表明,该模型在多关系抽取方面优于以往的模型。
1 引言
关系抽取是从句子中为实体对分配合适的关系类型的任务。对web挖掘、信息检索、问答、机器翻译等自然语言处理(NLP)任务有帮助。此外,这也是自动构建知识库的必要步骤。因此,可重构是信息抽取中的一个重要研究课题。通常,三元组(实体1,关系类型,实体2)用作关系的结构化表示的格式。有时一个句子可能包含多个实体和关系三元组,一个实体可能属于多个不同的三元组。因而有C(n,2)——在多重关系提取任务中,要分类到句子中的候选关系。如图1所示,在例句中标记了7个实体和6个关系三元组。PER(人)、WEA(武器)和GPE(地理/政治)是实体类型。PHYS(实体)、ART(代理人)、ORG-AFF(组织-附属)和GEN-AFF(一般附属)是关系类型。
我们可以看到,根据实体对的位置,三元组有重叠、嵌套、相交等结构。基于序列的模型很难处理这些复杂的结构。近年来,一些有效的基于图的模型被提出来解决多重关系抽取。文献提出了一个多关系提取模型,该模型将新识别的实体与先前的实体联系起来,并使用特征矩阵来学习图形结构。n元关系抽取的图模型是重叠关系抽取的一个特例,它将句子划分成两个有向无环图,并用图LSTM对关系进行分类。模型定义了一系列实体和关系转换动作,并将提取任务视为图形的动态生成过程。文献首先采用双RNN和GCN(图形卷积网络)来提取顺序和区域相关性单词特征,然后应用关系加权GCN来提取所有单词对之间的隐含特征。
这些基于图的模型在多关系抽取方面取得了巨大的成功。然而,他们主要利用已标记的训练数据来学习分类知识,而忽略了容易获取的未标记语料库。他们利用通过对未标记的语料库进行生成性预处理而产生的单词嵌入的语义信息,或者从辅助工具套件中获得语言学知识,例如依赖解析器、位置、NER工具等。我们认为大规模语料库包含丰富的语言学知识。因此,提出了一个语料库子图来从未标记的语料库中挖掘与任务相关的语言知识。它与句子子图结合构成一个关系知识图(RKG),用于多重关系抽取。关于RKG,实体识别可视为属性值填充问题,关系分类可视为链接预测问题。推理未知的实体和关系类型,或者根据已知的类型为它们寻找概率值,在本文中称为推理。因此,多重关系抽取可以被视为知识完成的推理过程。我们构建了语料库子图上节点的一系列统计量。这些统计量作为节点特征输入神经网络,将句子分割成实体块和非实体块。然后我们提出了一种新的组块图LSTM网络来学习实体组块的表示,并推导出它们之间的关系。

LSTM 网络对于学习单词序列中的长距离相关性是有效的,因此它被 应用于大量的自然语言处理任务。然而,大多数基于 LSTM 的模型只学习 单词表示,而不能表示语义块。作为 LSTM 的推广,本文提出了组块 LSTM 网络,用于同时学习单词和组块表示向量。我们将组块 LSTM 和图 LSTM 集成到组块图 LSTM 网络中,用于多重关系提取。组块图 LSTM 网络是 LSTM 的一般形式。它可以学习自然语言序列结构的表示和实体组块的图形结构的表示。实验结果证明了该模型的有效性。在 ACE2005 和 GENIA 数据 集上,它优于以前的多关系提取模型。本文的贡献可归纳如下:
·我们首先提出组块 LSTM 网络,它是 LSTM 网络的一般形式。组块 LSTM 网络能够学习单词和单词组块的表示。我们将组块 LSTM 与图 LSTM 集成,形成组块图 LSTM 网络,用于多关系提取。
·我们研究了一种新的方法,利用易于访问的未标记语料库来帮助 关系抽取任务。不同于在未标注语料库上生成预训练产生的词嵌入,该 方法构建了一些任务相关的统计量来挖掘语言知识。在本文的其余部分,我们在第 2 节讨论了相关的工作,然后在第 3 节介绍了我们的方法。接下来,我们在第 4 节中进行实验并分析结果。最后,我们在第五节结束我们的工作。
2相关工作
现有的关系抽取系统主要可以分为两类:基于手工匹配规则的半监督模型和基于手工标记数据的监督模型。半监督模型不需要大量带注释的数据,但是很难设计出高精度和高覆盖率的适当规则或模式。监督模型主要分为:基于核函数的方法,手动选择特征集对关系进行分类和基于神经网络的方法,自动学习潜在特征提取关系。基于神经网络的方法,可以利用或不利用手工制作的特征,包括基于RNN的,基于美国有线电视新闻网的,以及基于GCN的。神经网络模型可以学习所需的潜在特征和模式,但需要大量人工标注的训练数据。为了减少人工参与,在研究中研究了一种远程监督模型,该模型通过现有的知识库而不是人工产生注释数据。
上述研究在关系抽取方面取得了很大的成功。然而,它们大多侧重于单关系抽取。许多对多关系抽取有效的模型采用基于图的方法。工作通过将新识别的实体与先前的实体相联系来提取多个关系,并利用特征矩阵来学习图形结构。文献提出了一个重叠多关系抽取的图模型。该模型将句子和关系划分为两个有向无环图。一个DAG包含具有前指关系的线性链。另一个DAG用后向关系覆盖了线性链。两者都由一个双LSTM图连接,以对关系进行分类。工作定义了一系列实体和关系转换动作,并将提取视为图形的动态生成过程。工作首先计算每个跨度的局部上下文化向量空间表示,然后使用动态跨度图将全局信息合并到其跨度表示中,用于预测实体类型、关系类型。工作使用预先训练的BERT模型来获得令牌表示,然后通过最大化每个跨度中所有令牌的池来获得跨度表示。跨度表示通过分类层来提取关系。这些研究与我们工作的主要区别是:1.我们的方法通过在未标记的语料库上推理来使用语言知识。2.我们的模型利用块图LSTM网络进行多关系抽取。
标准LSTM可以描述线性关系,但不能模拟复杂关系。为了解决这个问题,提出了树LSTM 来建模依赖树结构。工作将依赖关系推广到所有类型的关系,并将树LSTM推广到图LSTM。遗憾的是,这些基于LSTM的网络仅描述了单词之间的关系,而不能捕捉词块之间的关系。在本文中,我们提出了一个块LSTM网络来学习块向量,并将其与图LSTM集成到块图LSTM中,用于多关系提取。
3方法
我们构建了用于多重关系抽取的关系知识图(RKG)。根据已知的数据推断未知的节点类型和边的类型,称为RKG推理过程。我们在语料库子图上应用基于混合推理的组块模型将句子分割成实体组块和非实体组块,然后提出组块图LSTM模型来学习实体和关系的表示。最后,使用两个完全连接的神经网络将实体和关系分类为预定义的类型。以下小节将详细描述我们的方法。
3.1关系知识图
关系知识图(RKG)G=(GC,GSS)是本文提出的一个由语料库组成的子图。其中GC=(VC,EC),GS=(VS,ES)。语料库子图是一个有向图,其中节点VC代表单词,边EC代表左右相邻关系。例如,在句子“在一个村庄里,以色列军队开火了...”,‘村’字与‘a’有左邻关系,‘a’与‘村’有右邻关系。对于一个词w,与w的左/右邻集有右/左邻关系的所有词。语料库子图是通过逐句扫描未标记的语料库而产生的。每个节点都有一些属性,如其出现频率fn、实体符号s、实体类型t、节点嵌入向量v、左邻集L、右邻集R、首字母大小写ic、左连接强度lc、右连接强度rc、左支撑强度LSA和右支撑强度rs。每条边都有一个属性,即出现频率fe。属性值可以是基本数据类型,如整数、浮点和更复杂的结构,如字符串、列表、数组、字典。本文将所有这些性质视为节点特征。为了方便起见,语料库中的每个句子经过处理后,都以一个开始标记S*开头,并以句尾标点符号结束。语料库子图是通过逐句扫描未标记的语料库和训练数据而生成的。
每个句子子图都是一个无向图,其中节点VS代表句子中的实体组块或非实体组块。一个组块可以包含一个或多个连续的单词。我们遵循图LSTM,边代表各种依赖关系,如邻接关系、句法依赖关系和块对之间的关系,而且这些边是完全参数化的。不同的是,LSTM语块图以语块为节点,而LSTM语块图以单词为节点。
句子子图中的每个单词都可以在语料库子图中找到对应的投影,因此语料库子图为句子中的单词提供分布式表示。此外,语料库子图提供了将句子分割成实体和非实体组块的语言知识。在句子子图上,使用组块图LSTM模型和两个全连接神经网络来推断关系和实体组块的类型。
3.2语料库子图的统计推理
为了准确地将句子分割成实体组块和非实体组块,我们为语料库子图上的每个节点构造了一系列统计量。在本文中,这些统计量被视为节点特征,其值被输入分类器以将句子分割成实体和非实体组块。它们被定义为以下公式:
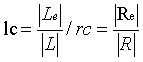
与实体lc/rc的左/右连接强度表示左/右相邻节点属于实体的概率。L/R为左/右相邻集。Le/Re是左/右相邻实体集,是L/R的子集,L /R= R /L是集L/R的基数。
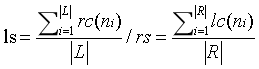
左/右支持强度ls/rs反映了节点属于由左/右相邻集合支持的实体的概率。它是左/右相邻集的右/左连接强度的平均值。rc(ni)/lc(ni)是与节点ni实体的左右连接强度。我们可以构造一个概率函数,它以统计量为输入,输出属于实体的概率以及在节点处切割的概率,从而分割句子。虽然统计推理是一种简单的方法,但它有一些缺点:首先,很难构造最合理的概率函数。其次,数据稀疏问题。为了克服这些问题,我们引入以下神经网络推理。
3.3基于语料库子图的神经网络推理
由于神经网络强大的鲁棒性和突出的函数拟合能力,我们设计了一个基于语料库子图的神经网络推理模型来克服函数选择和数据稀疏性的问题。图推理的主要挑战是节点表示和边表示。对于节点表示,有两种有效的方法可用。一种是广泛使用的单词嵌入。另一个是文献提出的LLE(局部线性嵌入),它假设每个节点是嵌入空间中它的邻居的线性组合。但是前者只强调当前节点,而忽略了环境。后者只强调环境,忽略了当前节点。因此,本文将这两种方法结合起来,提出了一种新的节点分布式表示方法。动机是节点与环境密切相关。因此,一个节点表示向量包含了节点本身和周围节点的信息,周围节点由左右相邻的集合组成。节点ni表示如下:
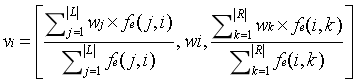
其中vi是节点ni的表示向量。它是通过连接左相邻集合L的单词嵌入向量的平均值、节点ni的单词嵌入向量wi和右相邻集合r的单词嵌入向量的平均值而产生的。fe(j,i)是边缘e(j,i)的出现频率;fe(i,k)是边缘e(i,k)的出现频率。
LSTMs可以捕捉长距离的相关性,广泛应用于序列标记任务。在这篇文章中,我们采用一个BiLSTM来标记每个单词的连接或断开以及实体或不实体,从而将句子分割成实体组块和非实体组块。我们假设一个句子链是S=(W0,W1,W2...WS)及其在Gc上的投影是V=(N1,N2,N3...NS),其中Woi是第i个单词,ni是第i个节点。为了分割成实体组块和非实体组块,我们训练一个双LSTM推理模型来为每个单词输出一个组块标签。每个分块标签可以被分解成两种类型的信号,一种是指示nt是否属于实体的实体信号,另一种是指示Schain是否在nt被切割的切割信号。每个信号有两种状态,即0和1。所以是4类分类模型。在训练过程中,实体标签由标记的数据给出。根据实体标签,我们可以很容易地得到分块标签。在测试过程中,根据组块标签,可以很容易地将句子分割成组块。推理过程如下:
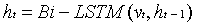

这里t代表在Bi-LSTM中的时间步,vi代表输入节点vi的向量,ht是影藏向量,yt分块标签的预测值。其损失函数为:
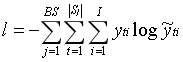
这里Bi是批处理尺寸,是Sj的长度,i=4是状态数。
3.4关于语料库子图的混合推理
如前所述,神经网络推理具有较强的鲁棒性和函数估计能力,克服了函数选择和数据稀疏性的问题。人工构建的统计包含经验知识,有助于分类。因此,本文将神经网络推理与统计推理相结合,应用于分段句。在混合推理模型中,统计量的具体观察值可视为节点的特征值,并输入到神经网络模型中,即将vt替换为输入模型中的vt。
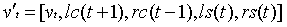
这里为混合推理模型的输入,是输入几点nt的表示向量,lc,rc,ls,rs是统计数据的观察值。
3.5LSTM块
根据混合推理模型在语料库子图上输出的分块标签,该句子被分割成一 个句子块链 SC (K1(wo11,wo12...wo1 K1 )...K SC ) , Ki表示实体块或非实体块。标 准的 LSTM 可以学习携带上下文信息的单词表示,但不能学习块表示。为 了获得语义块的表示向量,我们提出了块 LSTM 网络。具体操作如下:
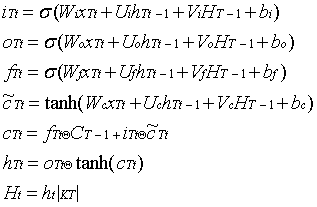
T 是链 SC 中块 KT 的位置号,t 是块 KT 中 woTt的位置号,xTt代表节点,hTt 是隐藏状态向量,Ht是块 Kt的隐藏状态向量, Kt 是 Kt的长度,我们使用组块 中最后一个单词的隐藏状态作为组块表示。在双向大块 LSTM, ht1是向后 方向最后一个单词的隐藏状态,因此组块表示由下式给出:
主要区别在于递推项。组块LSTM为每个组块添加了隐藏表示向量。它可以一起学习单词和组块表示。除此之外,组块LSTM的主要优势还包括其通用性和灵活性。标准LSTM是大LSTM的一个特例,当组块号SC 等于S ,我们可以通过在标准LSTM上堆叠LSTM组块来获得多层组块LSTM。
3.6块图LSTM推理模型上的句子子图
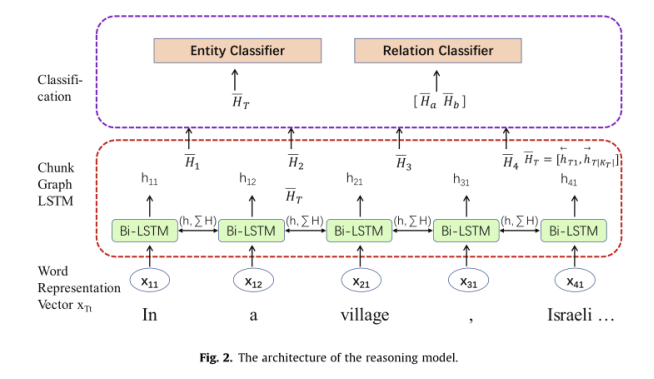
这些实体组块和非实体组块是句子子图的节点。像在工作中一样,各种依赖,如邻接、句法依赖和组块对之间的关系是边。因此,句子子图的推理任务是预测未知链接,并根据已知信息填充未知属性值。为了简化操作,我们将所有块完全连接起来,文献提出了图的LSTM模型,可以有效地表示图的结构。将块式LSTM与图式LSTM相结合,形成了用于多关系提取的块式图LSTM推理模型。模型架构如图2所示,操作如下:
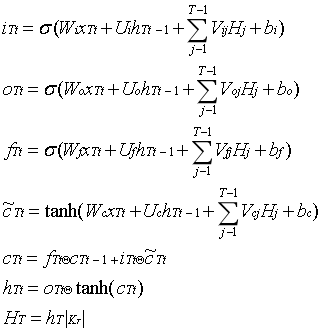
xTt 为节点表示向量。hTt 为隐藏表示向量, HT 是块 KT 在一个方向上隐藏向量。
双向模型如下:
HT 是块 KT 的隐藏表示向量,采用两种单列全连通神经网络对实体类型和 关系类 型进行分类。
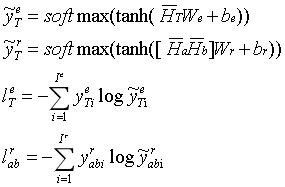
yT分别为实体类型的预测值和实值。yarb 是关系类型 Ha 和 Hb之间的预测价值, yrab 是它们之间真正的价值。lTe 和larb 分别为实体类型损失和关系类型损失。
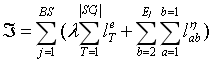
其中B是批处理尺寸,SCj 是句子块链 SCj 的块数量, Ej是一个句子中实体块的数量。重量偏差 决定了这两种损失的相对重要性。我们可以看到,当各种依赖关系只包括邻接关系时,块LSTM是块图LSTM的一个特例。
4试验
4.1语料库及数据集
通过逐句扫描NYT语料库和数据集的训练数据来产生语料库子图。语料库子图包含236 K个句子和8.9兆个单词。ACE2005包含三种语言的网络日志、广播新闻和新闻专线数据。我们选择英文部分作为数据集。它定义了7种实体类型和6种关系类型。GENIA数据集是从生物医学文献中收集的,旨在为分子生物学领域开发信息提取系统。像以前的研究一样,我们从GENIA中提取了药物-突变二元关系和药物-基因-突变三元关系。
4.2评估指标
继以前的研究之后,我们采用标准精度(P)、召回率(R)和F1值来评估ACE2005的性能,并采用平均精度来评估GENIA的性能。当一个实体的类型和头部区域正确时,它就是正确的。只有当两个实体和关系类型都正确时,关系才正确。
4.3参数设置
Stanford 's GloVe和ELMo单词嵌入被用作最初的单词表示。单词向量wi的维数为100。在语料库子图中,节点向量vi为300的维数。混合推理模型的输入为vi与四个统计量和初始字母案例icas。在实验中,我们发现初始字母大小写ic不工作,所以我们只保留了vi的统计量。在Bi-LSTM混合推理模型和Bi-LSTM块图模型中,输入大小分别是ls= 304和300。一个方向上的LSTM单元数是300。所有型号的批量尺寸BS都是100,我们选择{1,2,3}之间网络的层数N,得到{0.1,1,10,100}之间的偏差权重k。首先,我们将k=1固定在开发集上,通过网络搜索选择LR和N的最优值,Bi-LSTM的混合推理为0.00005和2。然后依次对块图Bi-LSTM上的k值进行测试。最后通过比较结果,得到k(10)的最优值。利用Adam算法计算梯度,利用BPTT算法更新参数。
4.4 2005年ACE测试结果
我们将我们的模型与三个强基线模型进行比较。Jonit模型采用BILOU标记方案对实体进行分割,并设计了一个线性模型来预测图的结构。该方法采用特征矩阵来学习句子的图结构,其学习效果受到了特征矩阵学习能力的限制。SPTree首先利用POS标签识别实体对,然后使用LSTM树对关系进行分类。它将相邻关系转化为依赖关系,并使用树形LSTMs对实体之间的关系进行分类。它是一个单一的关系提取模型,可能会在多个关系句中省略一些关系。文献提出了图LSTM模型,并将其应用于重叠多关系的提取。与以单词为图节点的图LSTM相比,Chunk图LSTM以语义块为图节点,从而减少了节点的数量,降低了图的复杂度。HSM提出了一种分层监督的多任务学习模型。该模型通过监督底层的一组低级任务和顶层的复杂任务,引入了一种归纳偏差。DyGIE为每个跨度计算一个局部上下文化的向量空间表示,然后将全局信息合并到其跨度表示中,以预测实体类型、关系类型。据我们所知,这是ACE2005上最先进的关系提取模型。图LSTM模型使用GloVe嵌入作为初始词表示,而HSM和DyGIE利用了GloVe和ELMo嵌入的连接作为最初的单词表示。为了公平起见,我们使用两种方法来比较这些基线。在ACE2005上的实验结果如表1所示。在使用GloVe嵌入时,我们基于混合推理的组块模型的F1得分为93.9%,块图LSTM模型的实体识别F1得分为85.4%,多关系提取F1得分为62.2%。在使用GloVe和ELMo嵌入时,我们的分块模型的F1得分为95.1%,块图LSTM模型的实体识别F1得分为87.4%,多关系提取F1得分为64.3%。它在ACE2005数据集上的性能超过了最先进的模型,并在F1中对多关系提取带来了大约1.1个百分点的改进。
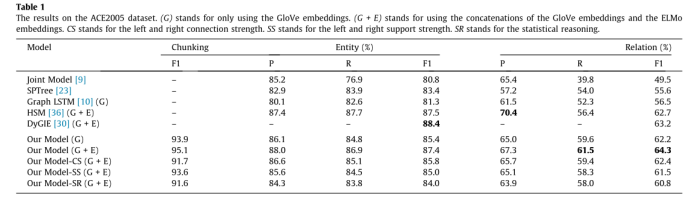
我们还在语料子图上对推理模型进行了烧蚀试验,观察统计推理是否对性能有贡献,哪些静力学对结果贡献最大。从对比第七行和最后一行,我们可以看到,统计推理有益影响分块任务以及提取任务和分块的F1值增加3.5的F1值关系提取3.5。它对神经网络推理进行了补充,提高了系统的整体性能。从第七行和第八行的对比中我们发现,左右连接强度可以提高分块的准确性。第七行和第九行对比表明,左右支持强度可以提高实体识别的性能。当所有静力学都被使用时,模型能达到最优性能。
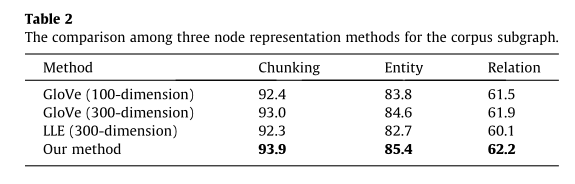
为了评价本文提出的节点表示方法的性能,我们在ACE2005上进行了一组对比实验。在混合推理模型中分别使用了三种不同的节点表示方法。该模型通过在全局词-词共现矩阵上进行训练得到词向量表示。LLE算法是一种节点表示方法,假设每个节点都是嵌入空间中相邻节点的线性组合。我们利用一种新的节点表示方法,其中节点向量包含节点本身和周围节点的信息。在我们的方法中,一个节点向量包括三个部分:100维向量为节点,100维向量左邻组和100维向量的邻集。100维GloVe embeddding向量是连接作为一个节点表示向量(见公式3),如表2所示,前两行用100尺寸和300维的手套词embeddding向量分别,第三行使用300维GloVe embeddding向量的线性组合。结果表明,该方法是有效的。
4.5 GENIA的结果
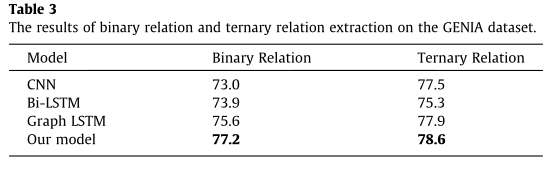
我们的模型在来自新闻和博客的ACE2005数据集上取得了良好的性能。为了评估在其他领域的语料库上的性能,我们在一个生物医学数据集GENIA上进行了实验。我们将我们的模型与在GENIA上复制的LSTM系统、CNN系统和Bi-LSTM系统的图进行比较。如表3所示,我们的块图LSTM模型在多关系提取方面优于之前的模型,在二元关系提取方面提高了1.6个百分点,在三元关系提取方面提高了0.7个百分点。结果表明,我们的模型在生物医学数据集上是有效的。
4.6案例研究
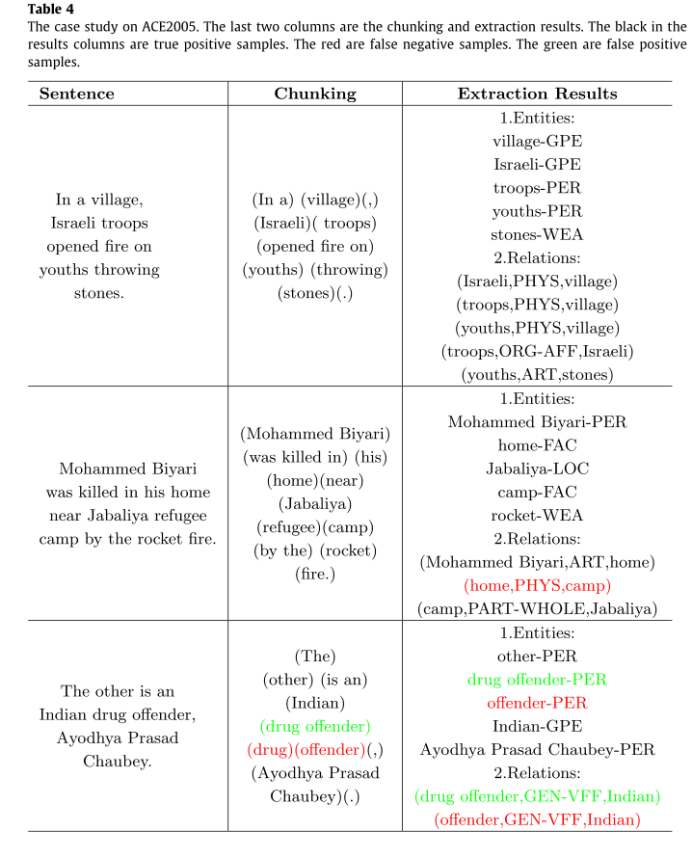
表4显示了我们对ACE2005模型的案例研究。第一句是一个简单的例子。我们的模型可以得到准确的分块和提取结果。因此,我们的模型可以有效地解决多关系提取问题。对于第二种困难情况,虽然我们的模型不能提取出PHYS关系,但在组块和实体识别方面取得了较好的效果。但是,模型在最后一句出现了一些错误。因为分块过程中有错误,所以错误将传播到下游任务。结果表明,误差传播问题会影响模型的性能。解决方法是提高分块模型的精度。
5结论
针对多关系的提取,提出了一种基于关系知识图的混合推理模型。研究了一种利用无标记语料库进行关系提取的新方法。我们提出了块式LSTM,并将其与图式LSTM集成到块式图LSTM中,从而推断出它们之间的关系。图LSTM以单词为图节点,块图LSTM以语义块为图节点。与图LSTM相比,Chunk图LSTM减少了图的节点数,从而降低了图的复杂性。实验结果证明了模型的有效性。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









