







Hive针对的应用场景是OLAP,通常对大数据集进行查询等操作,很多SQL要运行几十分钟到几个小时。
因此我们在使用Hive时,要注意对SQL的性能进行调优,主要包括两点——
- 避免时间复杂度过高的SQL
- 避免数据倾斜问题
针对Hive的性能调优,本文分为4个部分介绍,包括——
- 数据模型相关的知识点
- 特定场景下的优化
- 配置相关的优化
- 常见数据倾斜解决方案
1. 数据模型相关
对于Hive中的表,可以建立为分区表或桶表,了解这两种表,在合适的场景下使用可以提高Hive的性能。
1.1 Partition 分区表
分区表是指表按照某个字段进行划分,比如日期等。
分区表需要在创建表的时候通过PARTITIONED BY指定分区字段,如下为按照年份进行分区,注意分区字段不能跟前面括号中的字段重复。
CREATE TABLE employee(id INT, name STRING)
PARTITIONED BY(year INT);在Hive的数据模型中,每个表在HDFS中表现为所在数据库目录下的一个文件夹,如下图,前面的d表示文件夹。若不是分区表,则内部是一个个子文件,存储表的一部分数据。
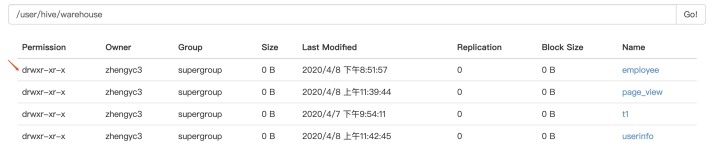
当设置分区后,比如我设置employee表按照年份进行分区,则每个分区又是一个单独的文件夹,如下:
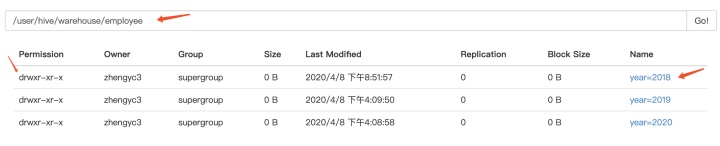
在设置分区后,在查询时通过WHERE子句过滤分区,就可以让Hive只取对应分区的数据进行计算,而不用取整个表的数据,提高计算效率。
1.2 Bucket 桶表
桶表是指表按照某个字段的hash值分配到不同的桶中,与分区表的区别在于同一个桶中用于划分的字段不需要指定取值,且可以有多个取值,通常用于高效采样(Sampling)。
桶表同样需要建表时指定,如下表示按照id分为4个桶,划分字段在前面括号中已经声明。
CREATE TABLE employee2(id INT, name STRING)
CLUSTERED BY(id) INTO 4 BUCKETS;桶表每个分区是一个文件,而不是文件夹,如下:
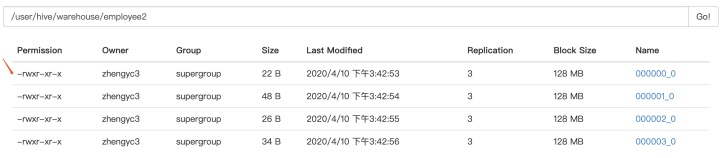
桶表通常用于高效采样,如下采样就可以只取其中一个桶的数据,相较随机采样等方式更高效。
SELECT * FROM employee2 TABLESAMPLE(BUCKET 2 OUT OF 4);2. 场景优化
前面介绍了分区表和桶表,本节主要介绍在Hive使用中几个特殊场景的优化。
2.1 全排序
关于排序,在之前的笔记中有简单介绍。
茵茵的聪聪:《Hive用户指南》- Hive的连接join与排序zhuanlan.zhihu.com 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









