







--------------------------------------------------------------------------------------------------------------
python安装本地文件:
场景:谷歌api要下载googleads-python-lib-master.zip文件到本地,然后d:就进了D盘,然后cd进去安装目录,看到本地有个setup.py文件了吧?然后在cmd运行python setup.py install 即可,如果有py2 py3的参考下下下面的
--------------------------------------------------------------------------------------------------------------
正则:
python re 正则要在完整教程里找答案:
http://www.cnblogs.com/zjltt/p/6955965.html
正则,为什么前面要加r ??
re.findall(r‘’
Python中字符串前面 加上 r 表示原生字符串 .
re.findall返回的是列表,要读取,直接访问list[0]即可,要增加可以list.append('nihao')
re.search返回的不知道是啥玩意儿,list = content.group(0),要这样
--------------------------------------------------------------------------------------------------------------
Python操作mysql:
sqlalchemy手册,都查它
https://www.cnblogs.com/coder2012/p/4741081.html
--------------------------------------------------------------------------------------------------------------
多线程:
多线程超级简单,就像一个函数:
t = threading.Thread(target=def, name='name1'),方法名,所需函数,就完成一个多线程了
#coding=utf-8
import threading
from time import ctime,sleep
def music(func):
for i in range(2):
print "I was listening to %s. %s" %(func,ctime())
sleep(1)
def move(func):
for i in range(2):
print "I was at the %s! %s" %(func,ctime())
sleep(5)
threads = [] #线程为一个list
t1 = threading.Thread(target=music,args=(u'爱情买卖',)) #线程1
threads.append(t1)
t2 = threading.Thread(target=move,args=(u'阿凡达',)) #线程2
threads.append(t2)
if __name__ == '__main__':
for t in threads: #有个循环来运行多个线程
t.setDaemon(True)#后面这些是开关
t.start()
t.join() #join()方法的位置是在for循环外的,必须等待for循环里的两个进程都结束后,才去执行主进程。
print "all over %s" %ctime()lock = threading.Lock()
with lock: #with表示自动打开自动释放锁
# 导入Python标准库中的Thread模块
from threading import Thread
# 创建一个线程
mthread = threading.Thread(target=function_name, args=(function_parameter1, function_parameterN))
# 启动刚刚创建的线程
mthread .start()
#function_name: 需要线程去执行的方法名
#args: 线程执行方法接收的参数,该属性是一个元组,如果只有一个参数也需要在末尾加逗号--------------------------------------------------------------------------------------------------------------
队列:
(作用:多个线程之间进行通信)
https://www.cnblogs.com/yeayee/p/5181193.html
https://www.cnblogs.com/ifyoushuai/p/9387984.html
--------------------------------------------------------------------------------------------------------------
Python mysql存储:
找找保存的const.py文件吧!
python批量上传图片到AWS:https://blog.csdn.net/qq_33811662/article/details/80710268
https://blog.csdn.net/github_25679381/article/details/52943665
https://jingyan.baidu.com/article/e73e26c0b8cc6424acb6a761.html
https://blog.csdn.net/afxcontrolbars/article/details/54634772
====================================================
代理ip
import urllib.request
import random
url = 'http://www.whatismyip.com.tw'
iplist = ['115.32.41.100:80','58.30.231.36:80','123.56.90.175:3128']
proxy_support = urllib.request.ProxyHandler({'http':random.choice(iplist)})
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent','Test_Proxy_Python3.5_maminyao')]
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
print(html)
====================================================
Python3 Re常用方法
常用的功能函数包括:compile、search、match、split、findall(finditer)、sub(subn)
1.compile
re.compile(pattern[, flags])
作用:把正则表达式语法转化成正则表达式对象
flags定义包括:
re.I:忽略大小写
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M:多行模式
re.S:' . '并且包括换行符在内的任意字符(注意:' . '不包括换行符)
re.U: 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
2.search
re.search(pattern, string[, flags])
作用:在字符串中查找匹配正则表达式模式的位置,返回 MatchObject 的实例,如果没有找到匹配的位置,则返回 None。
3.match
re.match(pattern, string[, flags])
match(string[, pos[, endpos]])
作用:match() 函数只在字符串的开始位置尝试匹配正则表达式,也就是只报告从位置 0 开始的匹配情况,
而 search() 函数是扫描整个字符串来查找匹配。如果想要搜索整个字符串来寻找匹配,应当用 search()。
例子:

import re
r1 = re.compile(r'world')
if r1.match('helloworld'):
print 'match succeeds'
else:
print 'match fails'
if r1.search('helloworld'):
print 'search succeeds'
else:
print 'search fails'
###############################
#match fails
#search succeeds
4.split
re.split(pattern, string[, maxsplit=0, flags=0])
split(string[, maxsplit=0])
作用:可以将字符串匹配正则表达式的部分割开并返回一个列表
import re
inputStr = 'abc aa;bb,cc | dd(xx).xxx 12.12';
print(re.split(' ',inputStr))
#################################
#['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', '12.12']
5.findall
re.findall(pattern, string[, flags])
findall(string[, pos[, endpos]])
作用:在字符串中找到正则表达式所匹配的所有子串,并组成一个列表返回
例:查找[]包括的内容(贪婪和非贪婪查找)
6.finditer
re.finditer(pattern, string[, flags])
finditer(string[, pos[, endpos]])
说明:和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并组成一个迭代器返回。
7.sub
re.sub(pattern, repl, string[, count, flags])
sub(repl, string[, count=0])
说明:在字符串 string 中找到匹配正则表达式 pattern 的所有子串,用另一个字符串 repl 进行替换。如果没有找到匹配 pattern 的串,则返回未被修改的 string。
Repl 既可以是字符串也可以是一个函数。
import re
def pythonReSubDemo():
inputStr = "hello 123,my 234,world 345"
def _add111(matched):
intStr = int(matched.group("number"))
_addValue = intStr + 111;
_addValueStr = str(_addValue)
return _addValueStr
replaceStr = re.sub("(?P<number>\d+)",_add111,inputStr,1)
print("replaceStr=",replaceStr)
if __name__ == '__main__':
pythonReSubDemo();
#########################################
#hello 234,my 234,world 345
====================================================
python调试:
使用 PyCharm 进行调试
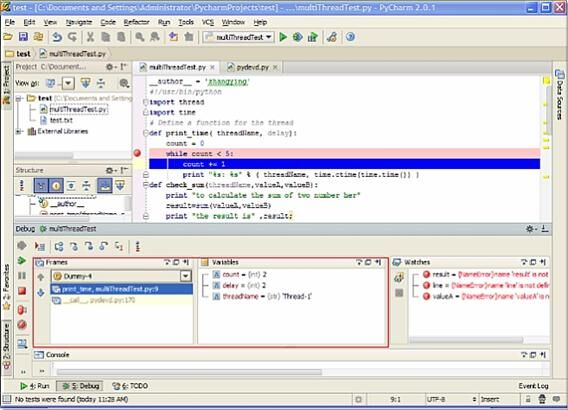
PyCharm 是由 JetBrains 打造的一款 Python IDE,具有语法高亮、Project 管理、代码跳转、智能提示、自动完成、单元测试、版本控制等功能,同时提供了对 Django 开发以及 Google App Engine 的支持。分为个人独立版和商业版,需要 license 支持,也可以获取免费的 30 天试用。试用版本的 Pycharm 可以在官网上下载,下载地址为:http://www.jetbrains.com/pycharm/download/index.html。 PyCharm 同时提供了较为完善的调试功能,支持多线程,远程调试等,可以支持断点设置,单步模式,表达式求值,变量查看等一系列功能。PyCharm IDE 的调试窗口布局如图 1 所示。
图 1. PyCharm IDE 窗口布局
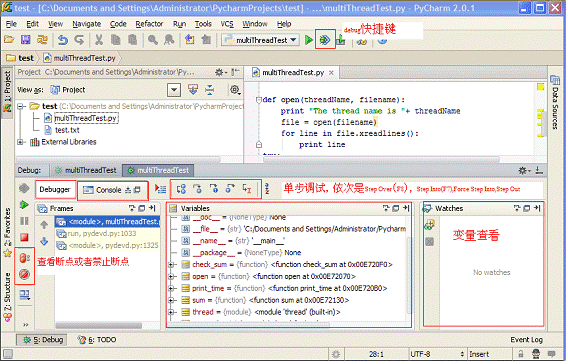
下面结合实例讲述如何利用 PyCharm 进行多线程调试。具体调试所用的代码实例见清单 10。
清单 10. PyCharm 调试代码实例
__author__ = 'zhangying'
#!/usr/bin/python
import thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
count += 1
print "%s: %s" % ( threadName, time.ctime(time.time()) )
def check_sum(threadName,valueA,valueB):
print "to calculate the sum of two number her"
result=sum(valueA,valueB)
print "the result is" ,result;
def sum(valueA,valueB):
if valueA >0 and valueB>0:
return valueA+valueB
def readFile(threadName, filename):
file = open(filename)
for line in file.xreadlines():
print line
try:
thread.start_new_thread( print_time, ("Thread-1", 2, ) )
thread.start_new_thread( check_sum, ("Thread-2", 4,5, ) )
thread.start_new_thread( readFile, ("Thread-3","test.txt",))
except:
print "Error: unable to start thread"
while 1:
# print "end"
pass
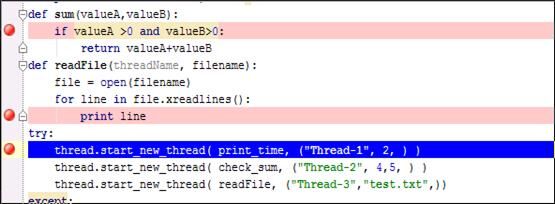
在调试之前通常需要设置断点,断点可以设置在循环或者条件判断的表达式处或者程序的关键点。设置断点的方法非常简单:在代码编辑框中将光标移动到需要设置断点的行,然后直接按 Ctrl+F8 或者选择菜单"Run"->"Toggle Line Break Point",更为直接的方法是双击代码编辑处左侧边缘,可以看到出现红色的小圆点(如图 2)。当调试开始的时候,当前正在执行的代码会直接显示为蓝色。下图中设置了三个断点,蓝色高亮显示的为正在执行的代码。
图 2. 断点设置
表达式求值:在调试过程中有的时候需要追踪一些表达式的值来发现程序中的问题,Pycharm 支持表达式求值,可以通过选中该表达式,然后选择“Run”->”Evaluate Expression”,在出现的窗口中直接选择 Evaluate 便可以查看。
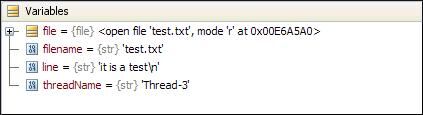
Pychar 同时提供了 Variables 和 Watches 窗口,其中调试步骤中所涉及的具体变量的值可以直接在 variable 一栏中查看。
图 3. 变量查看
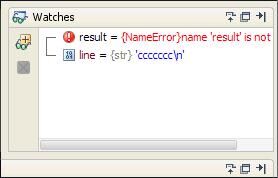
如果要动态的监测某个变量可以直接选中该变量并选择菜单”Run”->”Add Watch”添加到 watches 栏中。当调试进行到该变量所在的语句时,在该窗口中可以直接看到该变量的具体值。
图 4. 监测变量
对于多线程程序来说,通常会有多个线程,当需要 debug 的断点分别设置在不同线程对应的线程体中的时候,通常需要 IDE 有良好的多线程调试功能的支持。 Pycharm 中在主线程启动子线程的时候会自动产生一个 Dummy 开头的名字的虚拟线程,每一个 frame 对应各自的调试帧。如图 5,本实例中一共有四个线程,其中主线程生成了三个线程,分别为 Dummy-4,Dummy-5,Dummy-6. 其中 Dummy-4 对应线程 1,其余分别对应线程 2 和线程 3。
图 5. 多线程窗口
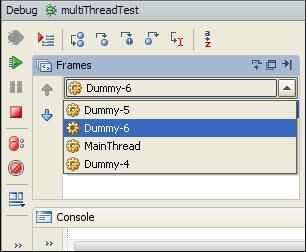
当调试进入到各个线程的子程序时,Frame 会自动切换到其所对应的 frame,相应的变量栏中也会显示与该过程对应的相关变量,如图 6,直接控制调试按钮,如 setp in,step over 便可以方便的进行调试。
图 6. 子线程调试
查看大图。
http://www.07net01.com/2015/08/904875.html
http://www.hackdig.com/?05/hack-10189.htm
https://blog.csdn.net/wjw7869/article/details/50563669
http://www.codeweblog.com/python中实现php的var_dump函数功能/
=====================================================
python遇到的问题:
如果出现这样的错误,一般呢是Python2 与 Python 3 不兼容情况造成的:
例如:
with open(fname, 'rb') as f:
lines = [x.strip() for x in f.readlines()]
for line in lines:
tmp = line.strip().lower()
if 'some-pattern' in tmp: continue
# ... code它会出现下面的错误类型:
TypeError: a bytes-like object is required, not 'str'基于以上错误改正的方式有两种:
with open(fname, 'rb') as f:if b'some-pattern' in tmp: continue(1)在字符串之前添加 b
with open(fname, 'r') as f:(2)将‘rb’读取改为‘r’读取。一般这样问题就解决了,如果出现 编码的错误,可以在打开方式后面加一个编码格式,
with open(fname, 'r',encoding='utf-8') as f:
同时还会出现别的一些问题:比如如何把一个str类型的字符串强制转化为二进制的形式,直接在前面加bin
例子如下:
>>> bin(int('256', 10))
'0b100000000'
>>> str(int('0b100000000', 2))
'256'========================================================
基础语法篇:
print dir 输出模块用法 (Python2,Python3搜索一下)
import base64
print dir(base64)
urllib2 :
get,post,head,put,
get最多请求1024个字节,post没有限制
http://www.jb51.net/article/88452.htm
requests模块用法:(下载文件,使用代理,修改header,post出去,get,cookies,证书等)
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')https://www.cnblogs.com/mzc1997/p/7813801.html
BeautifulSoup (提取网页建议使用)
http://www.cnblogs.com/mzc1997/p/7813819.html
selenium(微博,瀑布流等网站提取内容使用)
http://www.cnblogs.com/mzc1997/p/7814002.html
正则匹配:
https://www.cnblogs.com/tina-python/p/5508402.html
常用函数:
字符串格式化:
它是一个字符串格式化语法(它从C借用)。
请参阅 “格式化字符串”:
Python支持将值格式化为字符串。虽然这可以包括非常复杂的表达式,但最基本的用法是将值插入到
%s占位符的字符串中 。
编辑: 这是一个非常简单的例子:
name = raw_input("who are you?")
print "hello %s" % (name,)该 %s 令牌允许我插入(和潜在的格式)的字符串。请注意, %s 令牌被替换为% 符号后传递给字符串的任何内容 。还要注意,我也在这里使用一个元组(当你只有一个使用元组的字符串是可选的)来说明可以在一个语句中插入和格式化多个字符串。
只是为了帮助您更多,以下是您如何在一个字符串中使用多种格式
"Hello %s, my name is %s" % ('john', 'mike') # Hello john, my name is mike".如果您使用int而不是字符串,请使用%d而不是%s。
"My name is %s and i'm %d" % ('john', 12) #My name is john and i'm 12----------------------------------------------------------------------------------
For循环:
fruits = ['banana', 'apple', 'mango']
for f in fruits:
print f
===============================================
https://www.jianshu.com/p/5f3177943b91
https://www.devtool.top/article/55
===============================================
xampp 安装 mysql-python
在已经安装brew前提下:
brew install mysql-connector-c
pip install MySQL-python
第一篇:
在Pycharm里面怎么切换Python 2.7和Python3.0 ?
Setting-Project: XXXXXX-下面的Porject Interpreter,把安装路径设置好了就可以了。
1.下载python:
https://www.python.org/downloads/
注:选择需要的版本(python2 or python3, 32-bit or 64-bit)
2.安装python:
双击打开安装文件,直接下一步安装即可。
3.配置环境变量:
“右键”属性 —> 高级系统设置 —> 环境变量 —> 系统变量 —> path —> 输入Python的安装路径
配置python2和python3共存:
1.安装python2和python3

2.修改python2目录下python.exe为python2.exe,修改python2目录下pythonw.exe为pythonw2.exe
复制python3目录下python.exe为python3.exe,复制python3目录下pythonw.exe为pythonw3.exe
注:这里因为我自己主要使用python3,所以修改了python2目录,如果主要使用python2的话,可以修改python3目录
3.修改环境变量path
C:\Users\***\AppData\Local\Programs\Python\Python36
C:\Users\***\AppData\Local\Programs\Python\Python36\Scripts
C:\Users\***\AppData\Local\Programs\Python\Python27
C:\Users\***\AppData\Local\Programs\Python\Python27\Scripts
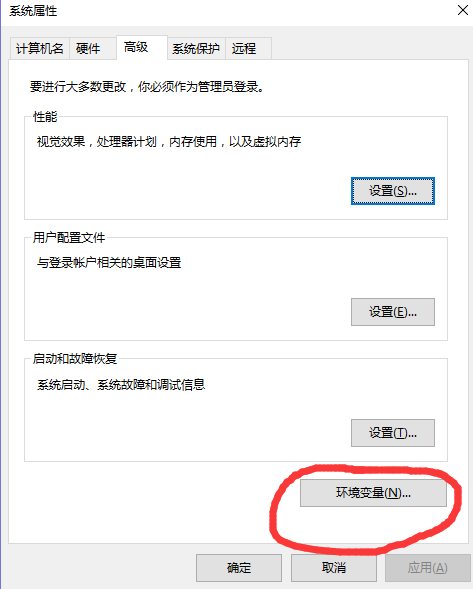
4.命令行键入python -V查看
win+r → cmd → python -V
win+r → cmd → python2 -V
win+r → cmd → python3 -V
============================================================
不知道要不要用到:
方法:将2.7安装到C:\Python27下,将3.6安装到C:\Python36下,在需要使用pthon3 run的.py文件中,添加shebang line来实现。
shebang line >>>> #!/usr/bin/env python3
添加到.py的头部即可
默认情况下没有声明的时候默认使用python2.7,而添加shebang line的.py会调用python3来运行
============================================================
二、调用pip
网上还提供了另外一种调用pip的方法
命令如下:
py -2 -m pip install XXXX
-2 还是表示使用 Python2,-m pip 表示运行 pip 模块,也就是运行pip命令了。
如果是为Python3安装软件,那么命令类似的变成
py -3 -m pip install XXXX#如果是安装本地模块:(先cd进入模块所在的路径)
python setup.py install
#正常是上面这样的,但如果本地同时安装了py2和py3 2个版本,就是这样:
py -3 setup.py install
Python中re模块:
https://www.cnblogs.com/tina-python/p/5508402.html
re模块:正则模块
urlparse模块:域名参数解析模块,
============================================================
Python笔记:
1、在Python里,缩进也会导致程序出错!
1.编码转换——utf-8转Unicode转GBK怎么转???
2.怎么很方便查看一个函数的用法呢???有没有快捷键??
3.我一直想知道,Python执行自动采集的事情。。。。。优先学习采集新闻站更新。。。上线!!
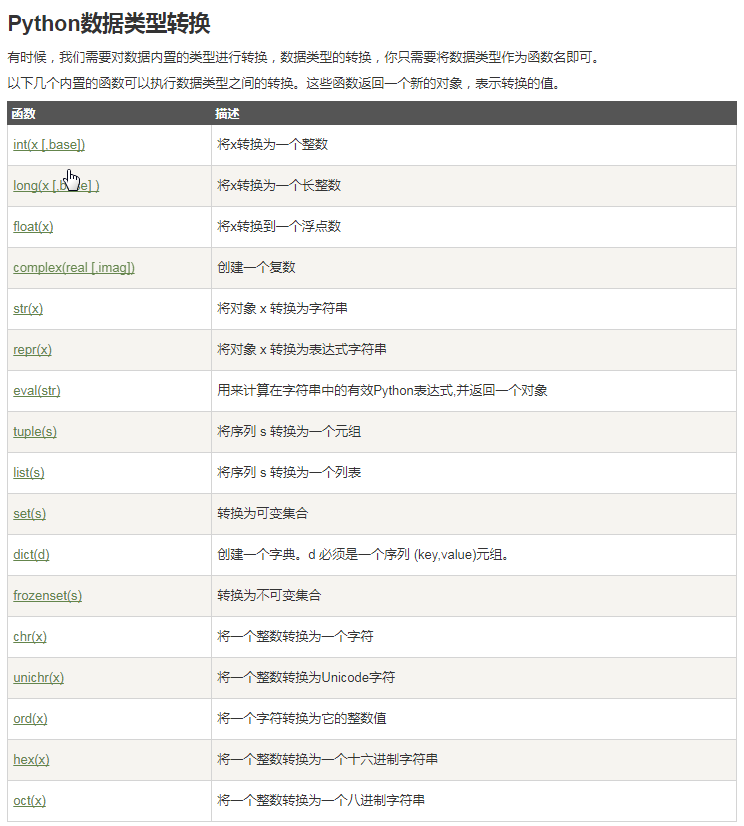
判断语句要注意:1、要写冒号 2、第二行要缩进,不能一起的!!!
循环句也是! 冒号: 缩进!!!
if ( a in list ): print '你好吗'
Python采集【入库】:(先有采集,然后有数据库,然后才能入库,而且还有是mysql数据库)
https://segmentfault.com/a/1190000002549756
爬虫被封的情况:
http://blog.csdn.net/offbye/article/details/52235139
=============================================
Python采集一个网页:
import re
import urllib2
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36"
}
req = urllib2.Request("https://www.sanwen8.com/sanwen/youmeisanwen/", headers=headers)
html = urllib2.urlopen(req).read()
print html
=============================================
Python常用函数:
http://www.runoob.com/python/python-built-in-functions.html (Python内置函数介绍)
append()方法语法:(obj -- 添加到列表末尾的对象)
list.append(obj)
lambda()方法:匿名函数
g = lambda x:x+1
可以这样认为,lambda作为一个表达式,定义了一个匿名函数,上例的代码x为入口参数,x+1为函数体,用函数来表示为:
def g(x):
return x+1
搜索路径:
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 1、当前目录
- 2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
在导入一次:比如hello.py, reload(hello)即可。
reload(module_name)
__name__ 特殊字符串变量__name__指向模块的名字。
__main__
包的概念还是不理解。。。。。。。
raw_input输入:如果是input返回的是电脑运算的一串数字。。。
str = raw_input("请输入:");
fo = open("foo.txt", "wb") 打开文件,打开模式再补脑吧。。
打开,写入,删除,重命名 文件处理file补脑
fo = open("foo.txt", "wb")
fo.write( "www.runoob.com!\nVery good site!\n");
fo.close()
# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )
#删除文件
os.remove(file_name)
#创建新目录
os.mkdir("newdir")
#改变为当前目录
os.chdir("/home/newdir")
#删除目录!!!!
os.rmdir('dirname')
错误类型补脑。。。。。。。
Python mysql 补脑。。。。。
转换为json格式:
#转化为json格式:
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = json.dumps(data)
#把json格式转换为Python的类型
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
============Python安装数据库==================
python-mysql的依赖安装
pip install mysqlclient- 1
windows无法安装的时候:http://www.lfd.uci.edu/~gohlke/pythonlibs/#mysqlclient
或者使用
pip install pymysql - 1
PS: 建议使用pymysql来代替MySQLdb。
在python3中, MySQLdb 已经不能继续使用了。可以使用pymysql或mysqlclient。
--------------------------------------------------------------------------
1、装pycharm-professional-5.0.3
2、装python-3.6.3-amd64
win+R cmd进入命令行,pip install requests
运行命令行 pip install openpyxl
【Python的两种版本切换的情况】
在Python安装好的盘里,找到Python.exe,然后对应分别设置为Python3.exe和Python2.exe。这样在命令行输入Python3和Python2就能任意使用两个版本了。
win+R cmd进入命令行,直接运行以下命令(记得加路径啊!!)
C:\python27\python -m pip install requests
C:\python27\python -m pip install openpyxl
C:\python27\python -m pip install jieba
C:\python27\python -m pip install -- upgrade pip
C:\python27\python C:\Python27\get-pip.py
C:\python27\python -m pip install -U pip
---------------------------------------------------------------------
安装orm,Python连接数据库用的
安装mongodb数据库
或者redis+mysql















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}