







大家知道由于lucene和solr在最新版本在分词方面改动比较大,在solr4.x上使用IK分词,并且设置粗细力度,安装官方的说法是这样设置的:
 结果发现建索引和查询时候的分词力度是一样的,默认是安装细力度分词,解决方案如下:
结果发现建索引和查询时候的分词力度是一样的,默认是安装细力度分词,解决方案如下:
package org.apache.solr.analysis;
import java.io.Reader;
import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory;
import org.wltea.analyzer.lucene.IKTokenizer;
/**
* 解决IK Analyzer 2012FF_hf1 在solr4.x应用时,配置useSmart失效的问题
*
* @author lqin
* @date 2013-12-24
* @email qin.liang@sinovatio.com
* @version 1.0
*
*/
public class IKAnalyzerSolrTokenizerFactory extends TokenizerFactory {
/**
* 构造函数,从参数里面读取配置
* @param args
*/
public IKAnalyzerSolrTokenizerFactory(Map<String, String> args)
{
super(args);
assureMatchVersion();
// 设置分词力度,useSmart=true粗力度,useSmart=false细力度
this.setUseSmart("true".equals(args.get("useSmart")));
}
private boolean useSmart;
public boolean useSmart()
{
return useSmart;
}
public void setUseSmart(boolean useSmart)
{
this.useSmart = useSmart;
}
public void init(Map<String, String> args) {
this.useSmart = "true".equals(args.get("useSmart")) ;
}
@Override
public Tokenizer create(AttributeFactory factory, Reader input)
{
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
}
}
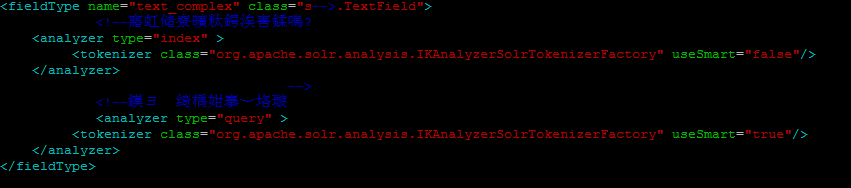
修改配置:















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









