







一、环境准备
1.CDH环境
| LinuxOS | CentOS6.7 |
| Hadoop | 2.6.0+cdh5.11.1+2400 |
| Zookeeper | 3.4.5+cdh5.11.1+111 |
| Hive | 1.1.0+cdh5.11.1+1041 |
| HBase | 1.2.0+cdh5.11.1+319 |
2.素材获取
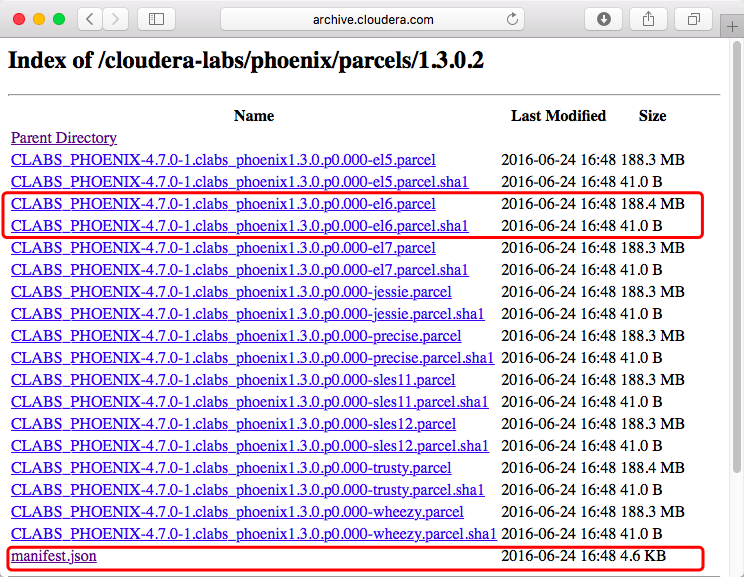
进入Cloudera官网下载Phoenix的Parcel:
http://archive.cloudera.com/cloudera-labs/phoenix/parcels/latest/
二、安装Phoenix
1.安装httpd
安装httpd服务以便后续可以发布Phoenix文件
yum install -y httpd*2.发布parcel
建立Phoenix目录,并拷入之前获取的文件(/var/www/html为httpd默认发布路径)
#建立Phoenix目录
mkdir /var/www/html/Phoenix
#拷贝文件到Phoenix目录
cp CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el6.parcel /var/www/html/Phoenix/
cp CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el6.parcel.sha1 /var/www/html/Phoenix/
cp manifest.json /var/www/html/Phoenix
#更名
mv CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el6.parcel.sha1 CLABS_PHOENIX-4.7.0-1.clabs_phoenix1.3.0.p0.000-el6.parcel.sha拷入文件并更名后文件信息

拷贝入文件后通过网页能够访问
http://47.95.246.68/phoenix/
3.CM-parcel部署
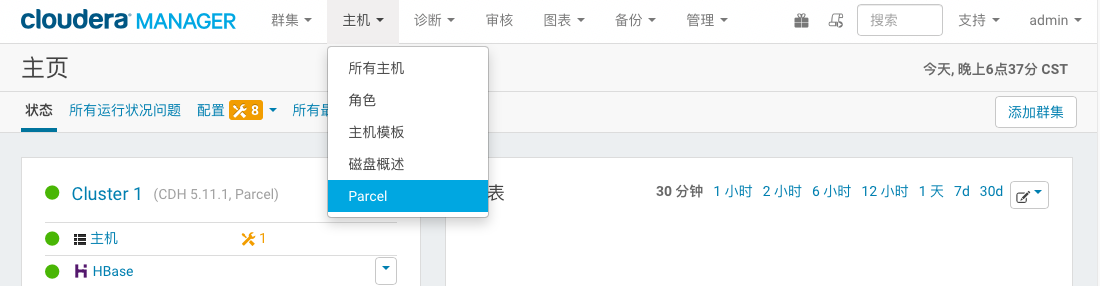
1> 进入CM主页点击《主机 -> Parcel》进入Parcel管理页面
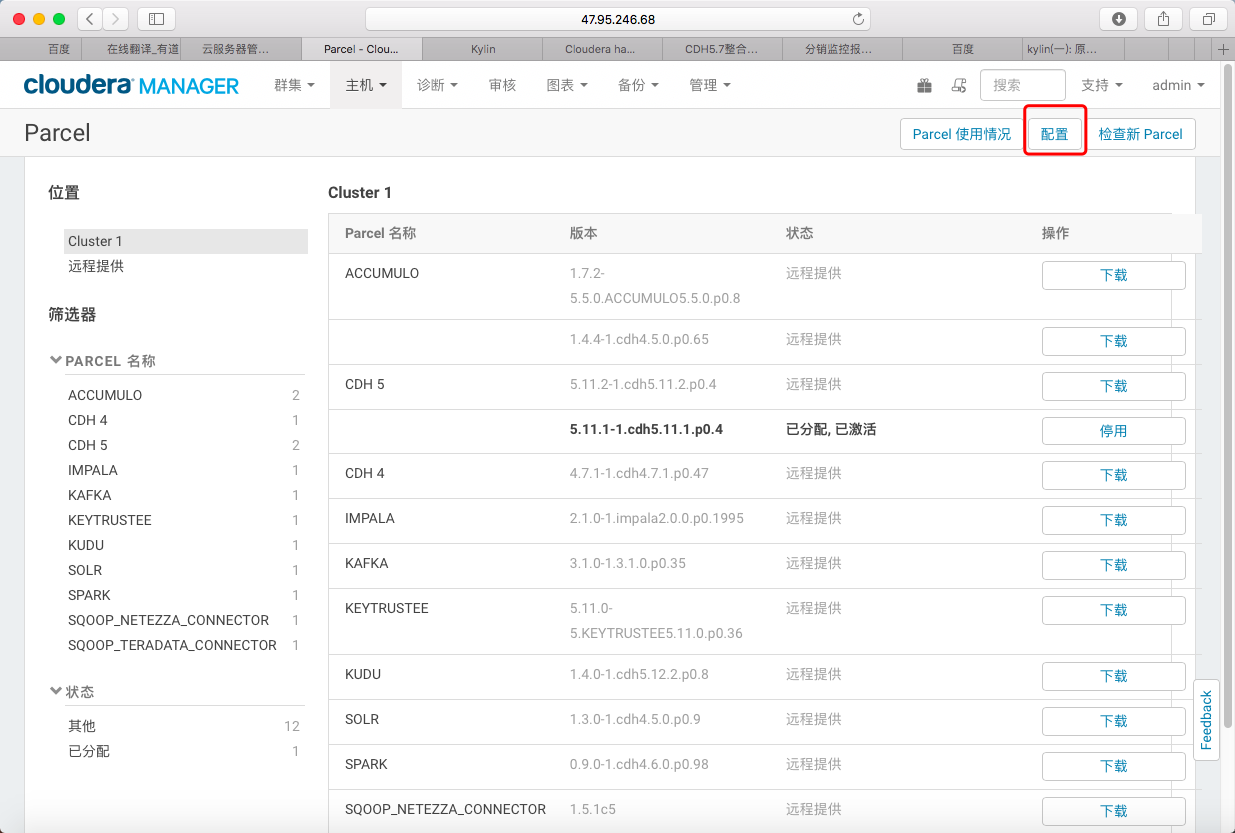
2> 在Parcel管理页面点击《配置》进入Parcel配置
3> 添加Phoenix发布的http地址并保存
http://47.95.246.68/phoenix/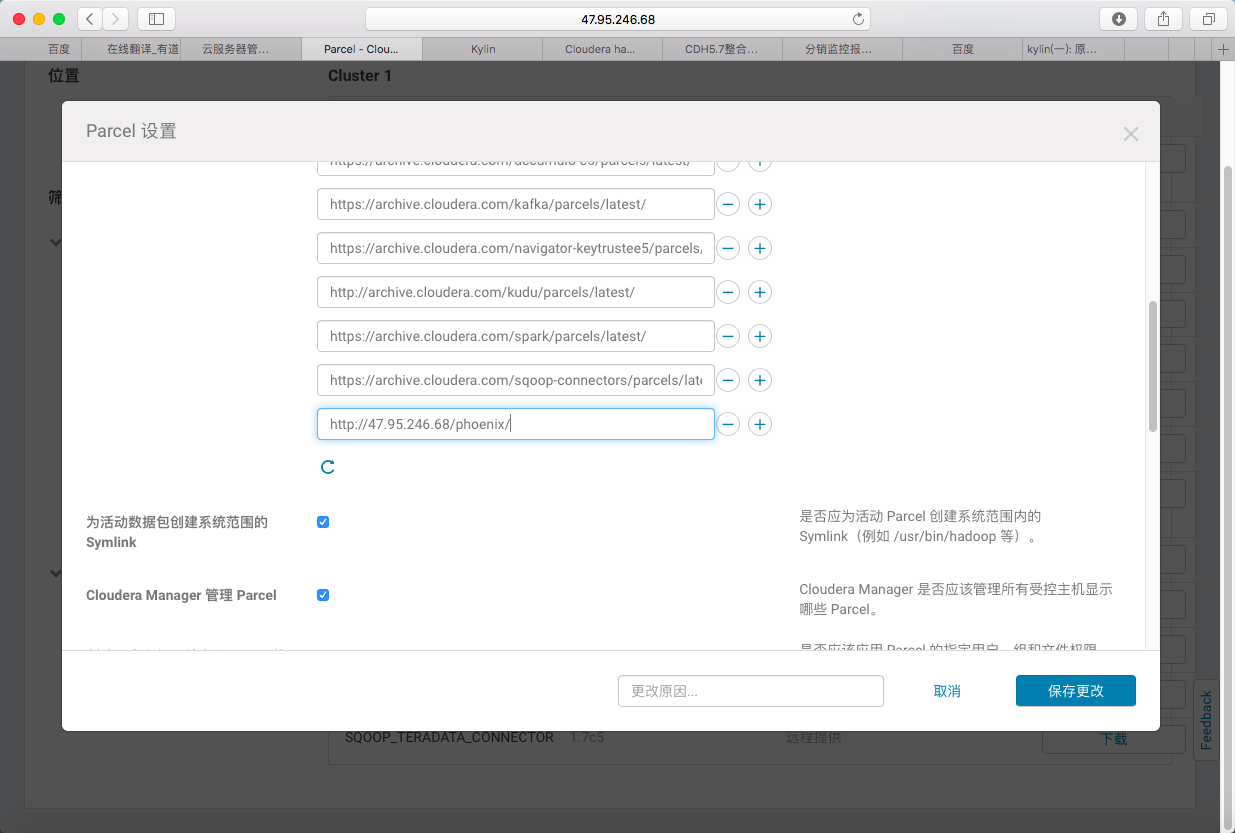
4> 返回发现CM已经识别Phoenix的远程Parcel
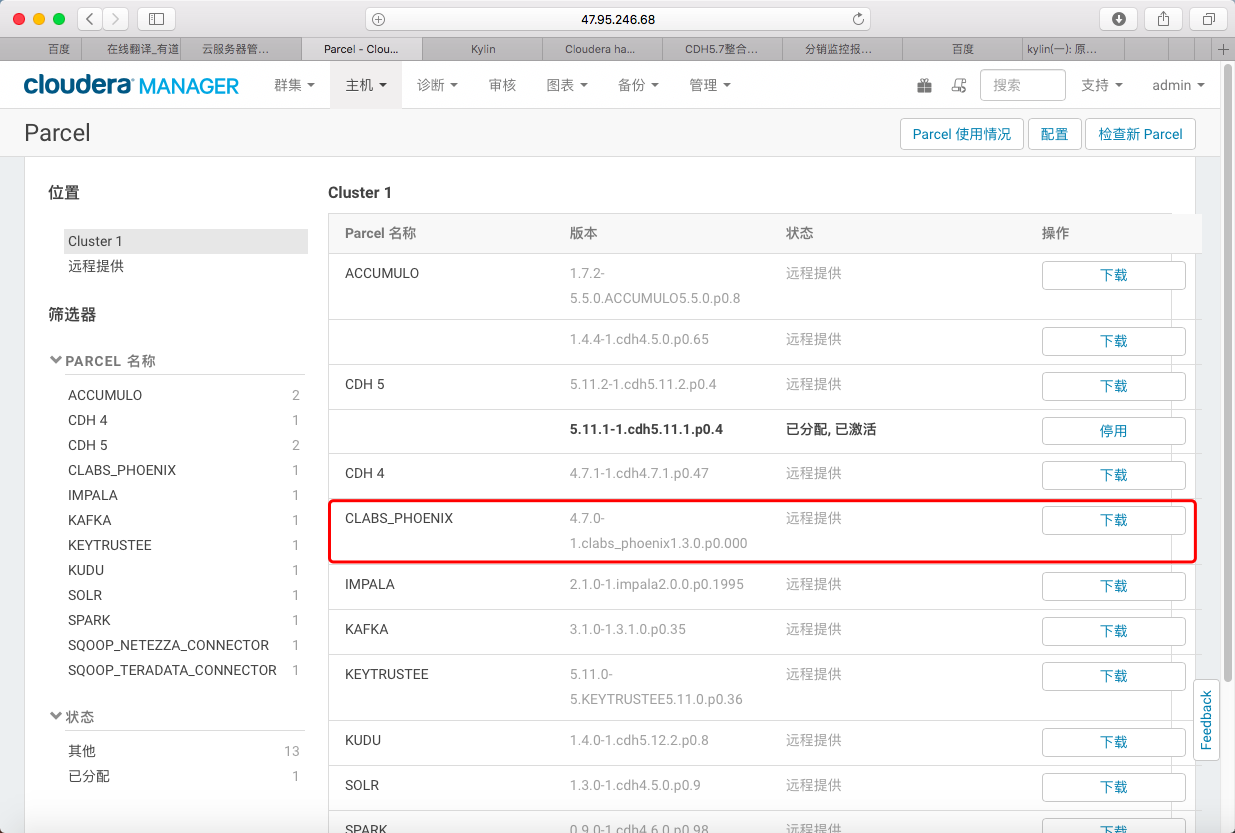
5> 依次点击《下载 -> 分配 -> 激活》完成Parcel布置




4.HBase配置更新
1> 返回CM主页面发现HBase需要重启并更新配置项
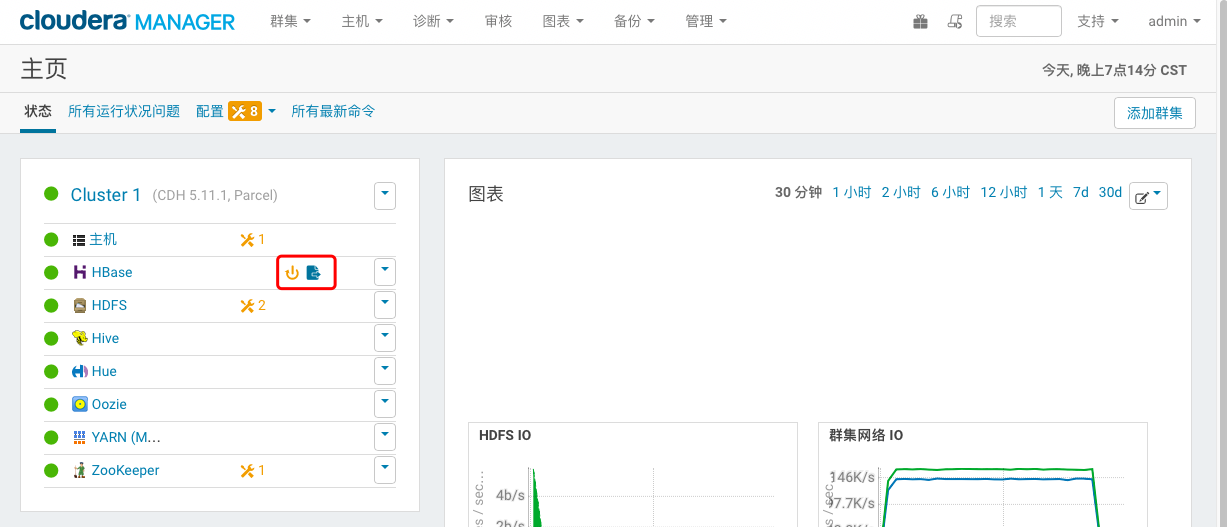
2> 更新过期配置
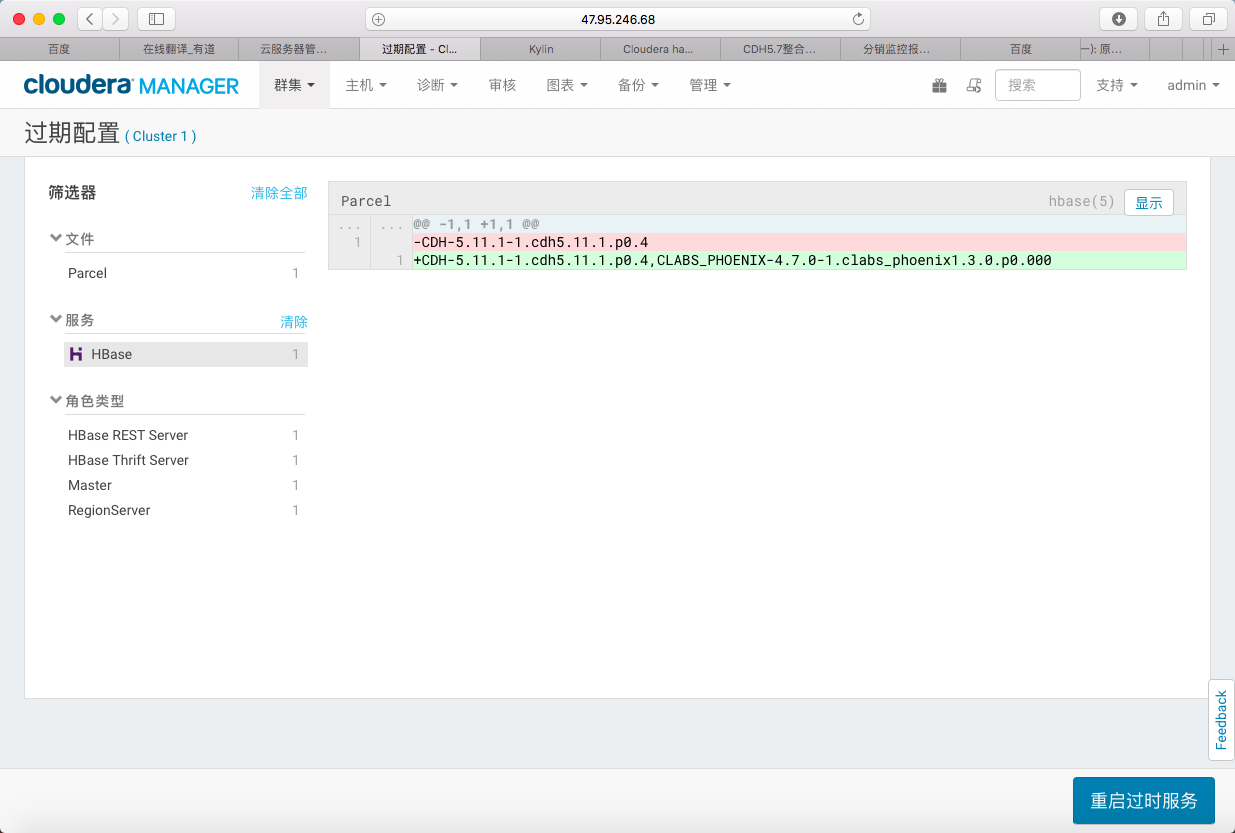
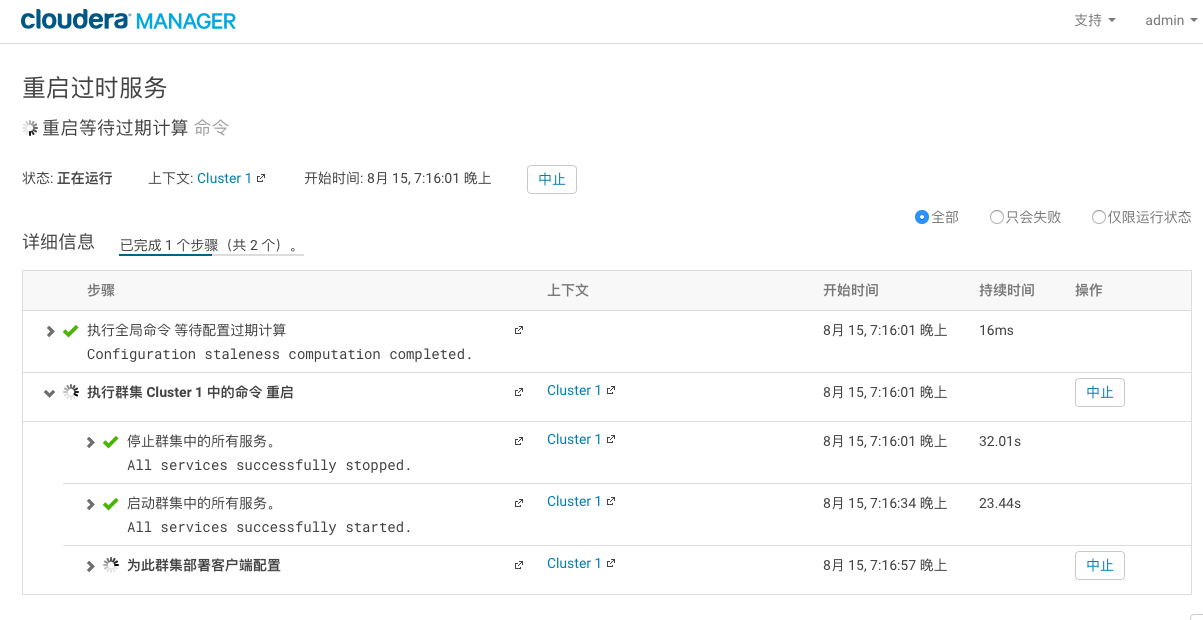
3> 重启过时服务
三、一般使用
1.启动Phoenix
1> 进入Phoenix的bin目录
cd /opt/cloudera/parcels/CLABS_PHOENIX/bin
2> 登陆Phoenix客户端(需要指定Zookeeper)
./phoenix-sqlline.py cdh01:2181:/hbase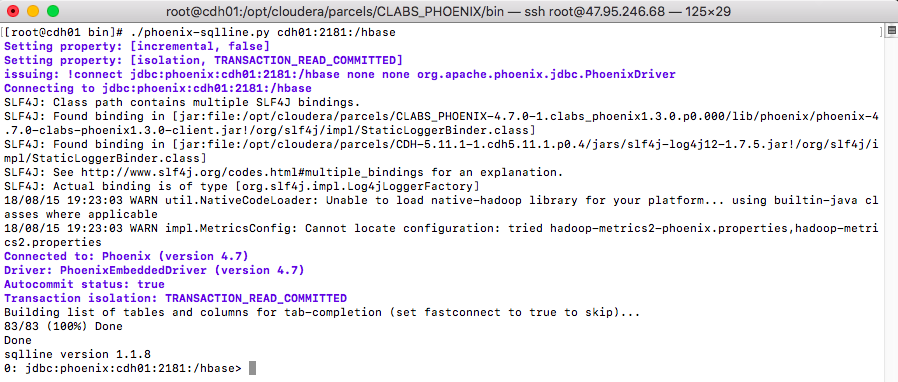
3> 查看表信息

2.create
Phoenix创建测试表
#设置单列为主键
CREATE TABLE tmp_staff
(
hrid varchar not null primary key,
parentid bigint,
departmentid varchar
);
#也可设置多列为联合主键
(当设置联合主键时,Phoenix会把定义的列拼起来作为Hbase的Rowkey)
CREATE TABLE test_staff
(
hrid varchar,
parentid bigint,
departmentid varchar
CONSTRAINT my_pk PRIMARY KEY (departmentid, hrid));
Hbase查看测试表
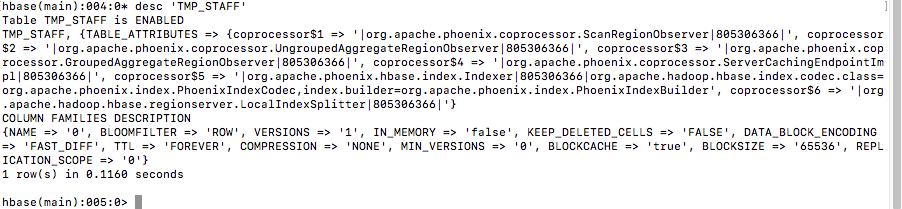
3.alter
Phoenix修改测试表
(特别说明:Phoenix的索引分为可变索引和不可变索引。它们通过对应主表IMMUTABLE_ROWS参数来设定。不可变索引的存储方式是write once, append only,主表数据变化时索引表会追加一条新索引,使用场景十分有限。可变索引的存储方式是write once, multiple edit。主表数据变化时索引表会更新对应索引条目。)
#新增列
ALTER TABLE tmp_table ADD departmentid varcher;
#删除列
ALTER TABLE tmp_table DROP COLUMN 0.departmentid;
#使得表支持可变索引
ALTER TABLE tmp_table SET IMMUTABLE_ROWS = true;Phoenix修改索引
(特别说明:Phoenix不保证完整的事务,所以可能出现索引表与主表不一致的情况。若想自己同步可以使用rebuild命令进行索引重建。同时也要注意,索引重建过程有可能bring down整个hbase集群)
#禁用索引
ALTER INDEX idx_tmp_table ON 0.departmentid DISABLE
#重建索引
ALTER INDEX IF EXISTS idx_tmp_table ON server_metrics REBUILD4.upsert
1> Phoenix测试表插入数据(Phoenix中没有INSERT语法,用UPSERT VALUES、UPSERT SELECT代替)
#插入数据
upsert into tmp_staff values('00021850',1915,'inthotel');
#查询
select * from tmp_staff;
Hbase查看测试表数据

2> Phoenix测试表更新数据(Phoenix中没有update语法,用UPSERT VALUES、UPSERT SELECT代替)
#更新数据
upsert into tmp_staff values('00021850',1915,'xxxxx');
#查询
select * from tmp_staff;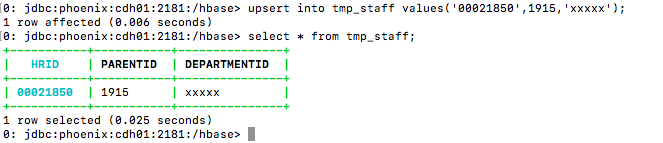
5.delete
Phoenix测试表删除数据
#删除数据
delete from tmp_staff where hrid='00021850';
#查询
select * from tmp_staff;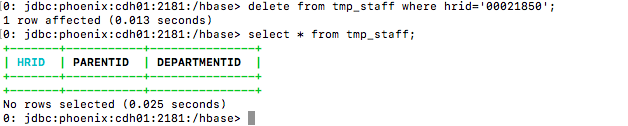
Hbase查看测试表数据

四、数据导入导出
1.bulkload
对于分布在集群上的高吞吐量的加载,可以使用MapReduce加载器。这个加载器首先将所有数据转换为HFiles,然后在HFile创建完成后直接将创建的HFiles提供给HBase。相对于走API导数据方式,速度更快负载更小。可使用的方法有:
org.apache.phoenix.mapreduce.CsvBulkLoadTool
org.apache.phoenix.mapreduce.JsonBulkLoadTool1> 准备CSV文件

#文件上传至HDFS
hadoop fs -put tmp_staff.csv /test2> 执行导入命令
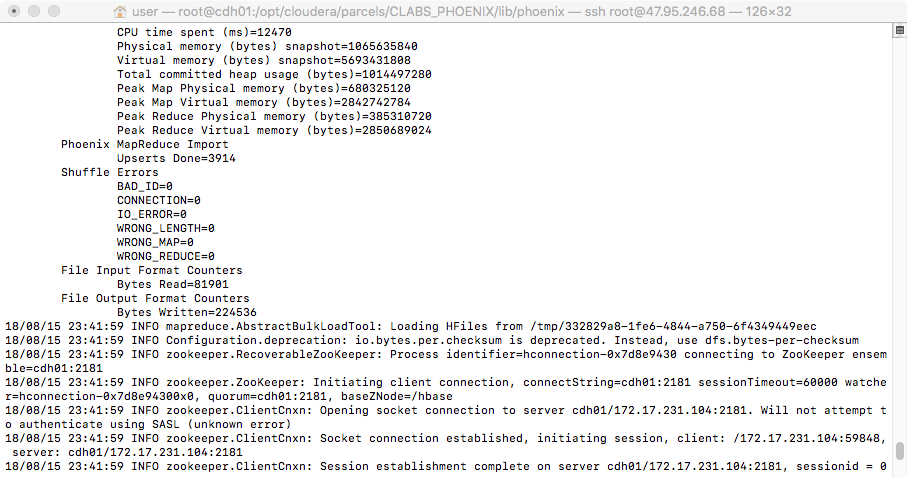
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-1.2.0-cdh5.11.1.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf hadoop jar /opt/cloudera/parcels/CLABS_PHOENIX/lib/phoenix/phoenix-4.7.0-clabs-phoenix1.3.0-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t tmp_staff -i /test/tmp_staff.csv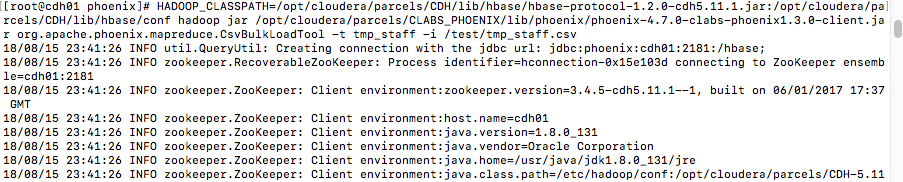
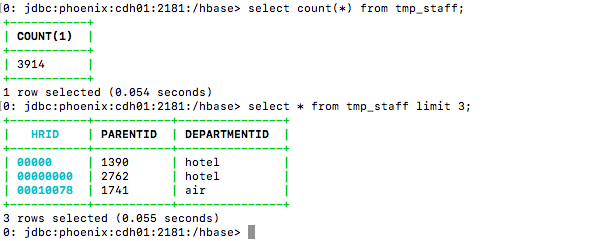
3> Phoenix中查看数据
4> HBase中查看数据

2.pig export
1> 准备导出所需控制文件
REGISTER /opt/cloudera/parcels/CLABS_PHOENIX/lib/phoenix/phoenix-4.7.0-clabs-phoenix1.3.0-client.jar;
rows = load 'hbase://query/SELECT * FROM TMP_STAFF' USING org.apache.phoenix.pig.PhoenixHBaseLoader('cdh01:2181');
STORE rows INTO 'tmp_staff_export.csv' USING PigStorage(',');
2> 执行导出命令
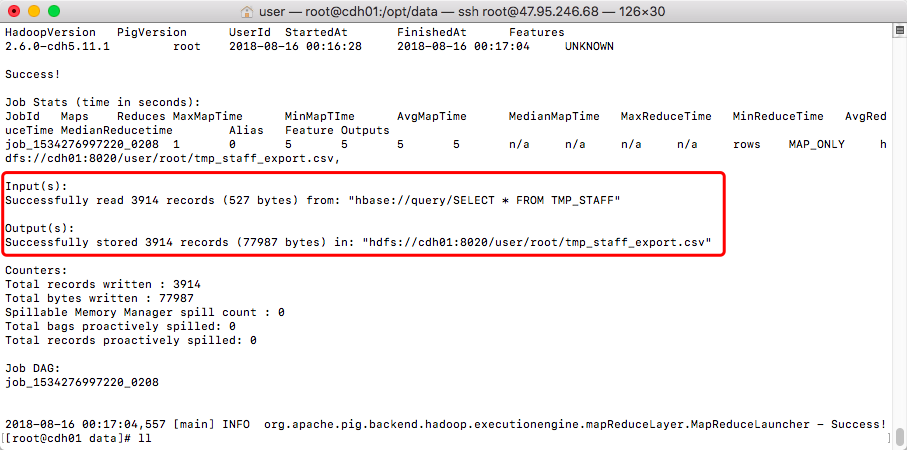
pig -x mapreduce tmp_staff_export.pig3> 导出开始

4> 导出任务成功
五、使用简述
1.优势概述
Phoenix作为应用层与HBase之间的中间件,以下特性使它在大数据量的简单查询场景有着独有的优势
1. 自动编译SQL为原生HBase可并行执行的scan
2. 多种二级索引支持(global、local、cover、func)
3. coprocessor在server端执行,减小服务与客户端传输开销
4. 下推where过滤条件到server端的scan filter上
5. 自动收集统计信息并利用它来优化查询计划(5.x版本将支持CBO)
6. skip scan利用了HBase的SEEK_NEXT_USING_HINT显著提高扫描速度
7. Salting通过对RowKey前添加Hash对表预分region,提升读写并消除热数据
8. 除了HBase的行级事务语义之外,与Tephra集成实现了跨行和跨表事务支持。2.访问方式
一般可以使用以下三种方式访问Phoenix
1. 命令行工具phoenix-sqlline.py等
2. JDBC API
3. SQuirrel3.性能对比
A:数据是5个窄列。regionServer数量:4台 (HBase堆:10GB,处理器:6核@ 3.3GHz Xeon)
#10M and 100M rows
select count(1) from table 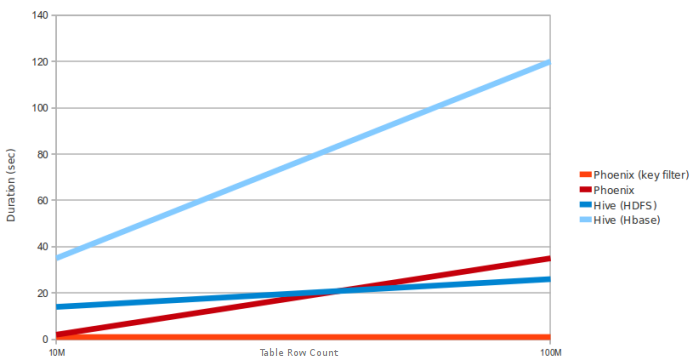
B:数据是3个窄列。region server数:1 (HBase堆:2GB,处理器:2核@ 3.3GHz Xeon)
#1M and 5M rows
select count(1) from table 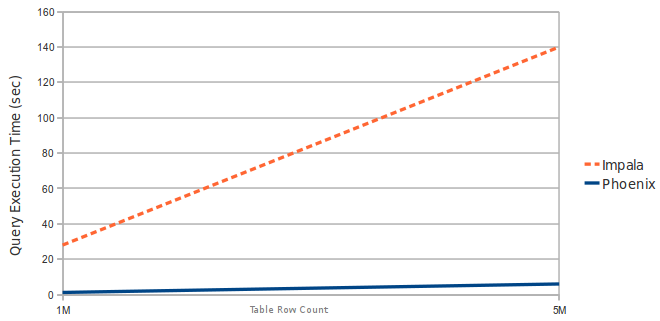















 3103
3103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









