







Vector,ArrayList,LinkedList有何区别?
三者都属于List的子类,方法基本相同。比如都可以实现数据的添加、删除、定位以及都有迭代器进行数据的查找,但是每个类
在安全,性能,行为上有着不同的表现。
Vector是Java中线程安全的集合类,如果不是非要线程安全,不必选择使用,毕竟同步需要额外的性能
开销,底部实现也是数组来操作,再添加数据时,会自动根据需要创建新数组增加长度来保存数据,并拷贝原有数组数据
ArrayList是应用广泛的动态数组实现的集合类,不过线程不安全,所以性能要好的多,也可以根据需要增加数组容量,不过与
Vector的调整逻辑不同,ArrayList增加50%,而Vector会扩容1倍。
LinkedList是基于双向链表实现,不需要增加长度,也不是线程安全的
Vector与ArrayList在使用的时候,应保证对数据的删除、插入操作的减少,因为每次对改集合类进行这些操作时,都会使原有数据
进行移动除了对尾部数据的操作,所以非常适合随机访问的场合。
LinkedList进行节点的插入、删除却要高效的多,但是随机访问对于该集合类要慢的多。
HashMap、Hashtable、ConcurrentHashMap的原理与区别
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length;] 这相当于直接将hash值对数组长度取模(跟0x7FFFFFFF做&操作是为了保证hashcode的值为正数)
HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1) 这有什么精妙之处呢,首先,Hashmap要求数组的size为2的幂乘,比如16,32,64,仔细看,当数组大小为16的时候,tab.length-1=15,在内存中的表示是00001111,将hash值与00001111做&(位与)操作后,会将hash值除了后四位全部抹为0,只保留了后四位,这样的方式完成了跟index = (hash & 0x7FFFFFFF) % tab.length一样的效果,就是取模。但是位运算的效率比取模操作高得多,也就是说HashMap的index计算方式要比Hashtable快得多。(Hashmap的初始size是16,每次扩容按照newsize = oldsize*2)
参考文章:
HashMap的初始值还要考虑加载因子:
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。解决hash冲突的办法:开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列);再哈希法;链地址法;建立一个公共溢出区;Java中hashmap的解决办法就是采用的链地址法。
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
程序猿可以根据实际情况来调整“负载极限”值。
ConcurrentHashMap
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable{
private static final long serialVersionUID = 7249069246763182397L;
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75F;
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
static final int MAXIMUM_CAPACITY = 1073741824;
static final int MAX_SEGMENTS = 65536;
static final int RETRIES_BEFORE_LOCK = 2;
final int segmentMask;
final int segmentShift;
final Segment<K, V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K, V>> entrySet;
transient Collection<V> values;- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
public class Hashtable<K, V> extends Dictionary<K, V>
implements Map<K, V>, Cloneable, Serializable
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, SerializableHashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞时,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
Hashtable是线程安全的,它的方法是同步的,可以直接用在多线程环境中。而HashMap则不是线程安全的,在多线程环境中,需要手动实现同步机制。
Hashtable与HashMap另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
先看一下简单的类图:
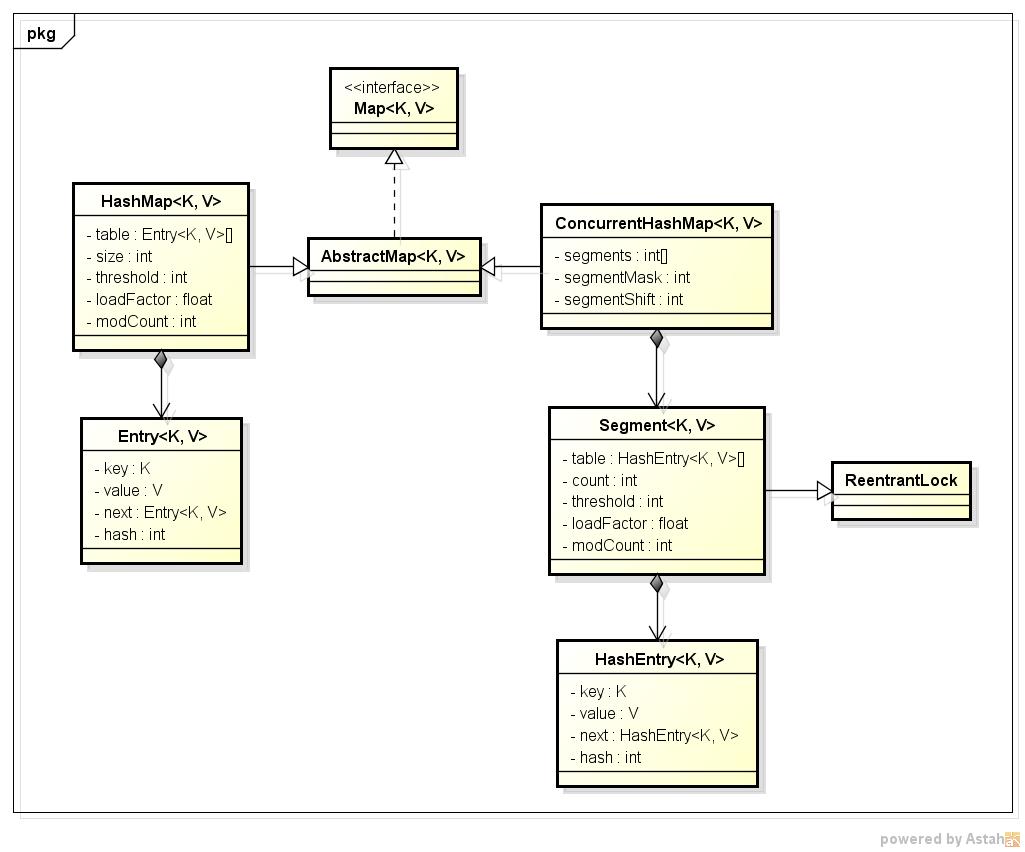
从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
HashSet 与TreeSet和LinkedHashSet的区别
Set接口
Set不允许包含相同的元素,如果试图把两个相同元素加入同一个集合中,add方法返回false。
Set判断两个对象相同不是使用==运算符,而是根据equals方法。也就是说,只要两个对象用equals方法比较返回true,Set就不会接受这两个对象。
HashSet与TreeSet都是基于Set接口的实现类。其中TreeSet是Set的子接口SortedSet的实现类。Set接口及其子接口、实现类的结构如下所示:
|——SortedSet接口——TreeSet实现类
Set接口——|——HashSet实现类
|——LinkedHashSet实现类
HashSet
HashSet有以下特点
不能保证元素的排列顺序,顺序有可能发生变化
不是同步的
集合元素可以是null,但只能放入一个null
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其 hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
通过查看HashSet的源码,可以看出hashSet底层是通过HashMap来实现的,HashSet add的对象,会作为HashMap的key来存储,保证唯一性。
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E, Object> map;
private static final Object PRESENT = new Object();
public boolean add(E paramE){
return (this.map.put(paramE, PRESENT) == null);
}
}
TreeSet
TreeSet的底层实现是TreeMap,当我们在创建一个TreeSet的时候,实际上是new了一个TreeMap,add的时候调用了TreeMap的put方法,来看看TreeMap中的put方法。
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向 TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(To1,To2)方法
Comparable
Comparable可以认为是一个内比较器,实现了Comparable接口的类有一个特点,就是这些类是可以和自己比较的,至于具体和另一个实现了Comparable接口的类如何比较,则依赖compareTo方法的实现,compareTo方法也被称为自然比较方法。如果开发者add进入一个Collection的对象想要Collections的sort方法帮你自动进行排序的话,那么这个对象必须实现Comparable接口。compareTo方法的返回值是int,有三种情况:
1、比较者大于被比较者(也就是compareTo方法里面的对象),那么返回正整数
2、比较者等于被比较者,那么返回0
3、比较者小于被比较者,那么返回负整数
Comparator
Comparator可以认为是是一个外比较器,个人认为有两种情况可以使用实现Comparator接口的方式:
1、一个对象不支持自己和自己比较(没有实现Comparable接口),但是又想对两个对象进行比较
2、一个对象实现了Comparable接口,但是开发者认为compareTo方法中的比较方式并不是自己想要的那种比较方式
Comparator接口里面有一个compare方法,方法有两个参数T o1和T o2,是泛型的表示方式,分别表示待比较的两个对象,方法返回值和Comparable接口一样是int,有三种情况:
1、o1大于o2,返回正整数
2、o1等于o2,返回0
3、o1小于o3,返回负整数
总结
总结一下,两种比较器Comparable和Comparator,后者相比前者有如下优点:
1、如果实现类没有实现Comparable接口,又想对两个类进行比较(或者实现类实现了Comparable接口,但是对compareTo方法内的比较算法不满意),那么可以实现Comparator接口,自定义一个比较器,写比较算法int compare(obj1,obj2)
2、实现Comparable接口的方式比实现Comparator接口的耦合性 要强一些,如果要修改比较算法,要修改Comparable接口的实现类,而实现Comparator的类是在外部进行比较的,不需要对实现类有任何修改。从这个角度说,其实有些不太好,尤其在我们将实现类的.class文件打成一个.jar文件提供给开发者使用的时候。实际上实现Comparator 接口的方式后面会写到就是一种典型的策略模式。
当然,这不是鼓励用Comparator,意思是开发者还是要在具体场景下选择最合适的那种比较器而已















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









