






Smoke Art Cubes to Smoke — MattysFlicks — (CC BY 2.0)
- 原文地址:JavaScript Monads Made Simple
- 原文作者:
Eric Elliott- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:yoyoyohamapi
- 校对者:IridescentMia WJoan
(译注:该图是用 PS 将烟雾处理成方块状后得到的效果,参见 flickr。)
这是 “软件编写” 系列文章的第十一部分,该系列主要阐述如何在 JavaScript ES6+ 中从零开始学习函数式编程和组合化软件(compositional software)技术(译注:关于软件可组合性的概念,参见维基百科
< 上一篇 | << 返回第一篇
在开始学习 Monad 之前,你应当了解过:
- 函数组合:
compose(f, g)(x) = (f ∘ g)(x) = f(g(x)) - Functor 基础:对于
Array.map()操作有清晰的理解
Gilad Bracha 曾说过,“一旦你明白了 monad,你反而就没法向其他人解释什么是 monad 了”,这就好像 Lady Mondegreen 空耳诅咒一样,我们都可以称其为 Lady Monadgreen 诅咒了。(Gilad Bracha 这段话最著名的引用者你不会陌生,他是 Douglas Crockford)。
译注:Mondegreen 指空耳,Lady Modegreen 是该词的来源,当年一个小女孩把 “and laid him on the green” 错听成了 “and Lady Mondegreen”。
Kurt Vonnegut's 在其小说 Cat's Cradle 中写到:“Hoenikker 博士常说,任何无法对一个 8 岁大的孩子解释清楚他是做什么的科学家都是骗子”。
如果你在网上搜索 “Monad”,你会被各种范畴学理论搞得头皮发麻,很多人也貌似 “很有帮助地” 用各种术语去解释它。
但是,别被那些专业术语给唬住了,Monad 其实很简单。我们看一下 Monad 的本质。
一个 Monad 是一种组合函数的方式,它除了返回值以外,还需要一个 context。常见的 Monad 有计算任务,分支任务,或者 I/O 操作。Monad 的 type lift(类型提升),flatten(展平)以及 map(映射)操作使得数据类型统一,从而实现了,即便组合链中存在 a => M(b)这样的类型提升,函数仍然可组合。a => M(b) 是一个伴随着某个计算 context 的映射过程,Monad 通过 type lift,flatten 及 map 完成,但是用户不需要关心实现细节:
- 函数 map:
a => b - 具有 Functor context 的 map:
Functor(a) => Functor(b) - 具备 Monad context,且需要 flatten 的 map:
Monad(Monad(a)) => Monad(b)
但是,“flatten”、“map” 和 “context” 究竟意味着什么?
- map 指的是,“应用一个函数到 a,返回 b”。即给定某输入,返回某输出。
- context 是一个 Monad 组合(包括 type lift,flatten 和 map)的计算细节。Functor/Monad 的 API 用到了 context,这些 API 允许你在应用的某些部分组合 Monad。Functor 及 Monad 的核心在于将 context 进行抽象,使我们在进行组合的时候不需要关注其中细节。在 context 内部进行 map 意味着你可以在 context 内部应用一个 map 函数完成
a => b,而新返回的b又被包裹了相同的 context。如果a的 context 是 Observable,那么b的 context 就也是 Observable,即Observable(a) => Observable(b)。同理有,Array(a) => Array(b)。 - type lift 指的是将一个类型提升到对应的 context 中,值因此被赋予了对应 context 拥有的 API 用于计算,驱动 context 相关计算等等。类型提升可以描述为
a => F(a)。(Monad 也是一种 Functor,所以这里我们用了F表示 Monad) - flatten 指的是去除值的 context 包裹。即
F(a) => a。
上面的说明还是有些抽象,现在看个例子:
const x = 20; // `a` 数据类型的 `x`
const f = n => n * 2; // 将 `a` 映射为 `b` 的函数
const arr = Array.of(x); // 提升 `x` 的类型为 Array
// JavaScript 中对于数组类型的提升可以使用语法糖:`[x]`
// `Array.prototype.map()` 在 `x` 上应用了 map 函数 `f`,
// map 发生的 context 正是数组
const result = arr.map(f); // [40]在这个例子中,Array 就是 context,x 是进行 map 的值。
这个例子没有涉及嵌套数组,但是在 JavaScript 中,你可以通过 .concat() 展开数组:
[].concat.apply([], [[1], [2, 3], [4]]); // [1, 2, 3, 4]你早就用过 Monad 了
无论你对范畴学知道多少,使用 Monad 都会优化你的代码。不知道利用 Monad 的好处的代码就可能让人头疼,如回调地狱,嵌套的条件分支,冗余代码等。
本系列已经不厌其烦的说过,软件开发的本质即是组合,而 Monad 使得组合更加容易。再回顾下 Monad 的实质:
- 函数 map,这要求函数的输入输出是整齐划一的:
a => b - 具有 Functor context 的 map,要求函数的输入输出是 Functor:
Functor(a) => Functor(b) - 具备 Monad context,且需要 flatten 的 map,则允许组合中发生类型提升:
Monad(Monad(a)) => Monad(b)
这些都是描述函数组合的不同方式。函数存在的真正目的就是让你去组合他们,编写应用。函数帮助你将复杂问题划分为若干简单问题,从而能够分而治之的处理这些小问题,在应用中,不同的函数组合,就带来了解决不同问题的方式,从而让你无论面对什么大的问题,都能通过组合进行解决。
理解函数及如何正确使用函数的关键在于更深刻地认识函数组合。
函数组合是为数据流创建一个包含有若干函数的管道。在管道入口,你导入数据,在管道出口,你获得了加工好的数据。但为了让管道工作,管道上的每个函数接受的输入应当与上一步函数的输出拥有同样的数据类型。
组合简单函数非常容易,因为函数的输入输出都有整齐划一的类型。只需要匹配输出类型 b为 输入类型 b 即可:
g: a => b
f: b => c
h = f(g(a)): a => c如果你的映射是 F(a) => F(b),使用 Functor 的组合也很容易完成,因为这个组合中的数据类型也是整齐划一的:
g: F(a) => F(b)
f: F(b) => F(c)
h = f(g(Fa)): F(a) => F(c)但是如果你想要从 a => F(b),b => F(c) 这样的形式进行函数组合,你就需要 Monad。我们把 F() 换为 M() 从而让你知道 Monad 该出场了:
g: a => M(b)
f: b => M(c)
h = composeM(f, g): a => M(c)等等,在这个例子中,管道中流通在函数之间的数据类型没有整齐划一。函数 f 接收的输入是类型 b,但是上一步中,f 从 g 处拿到的类型却是 M(b)(装有 b 的 Monad)。由于这一不对称性,composeM() 需要展开 g 输出的 M(b),把获得的 b 传给 f,因为 f 想要的类型是 b 而不是 M(b)。这一过程(通常称为 .bind() 或者 .chain()) 就是 flatten 和 map 发生的地方。
下面的例子中展现了 flatten 的过程:从 M(b) 中取出 b 并传递给下一个函数:
g: a => M(b) flattens to => b
f: b maps to => M(c)
h composeM(f, g):
a flatten(M(b)) => b => map(b => M(c)) => M(c)Monad 使得类型整齐划一,从而使 a => M(b) 这样,发生了类型提升的函数也可被组合。
在上面的图示中,M(b) => b 的 flatten 操作及 b => M(c) 的 map 操作都在 chain 方法内部完成了。chain 的调用发生在了 composeM() 内部。在应用层面,你不需要关注内在的实现,你只需要用和组合一般函数相同的手段组合返回 Monad 的函数即可。
由于大多数函数都不是简单的 a => b 映射,因此 Monad 是需要的。一些函数需要处理副作用(如 Promise,Stream),一些函数需要操纵分支(Maybe),一些函数需要处理异常(Either),等等。
这儿有一个更加具体的例子。假如你需要从某个异步的 API 中取得某用户,之后又将该用户传给另一个异步 API 以执行某个计算:
getUserById(id: String) => Promise(User)
hasPermision(User) => Promise(Boolean)让我们撰写一些函数来验证 Monad 的必要性。首先,创建两个工具函数,compose() 和trace():
const compose = (...fns) => x => fns.reduceRight((y, f) => f(y), x);
const trace = label => value => {
console.log(`${ label }: ${ value }`);
return value;
};之后,尝试进行函数组合解决问题(根据 Id 获得用户,进而判断用户是否具有某个权限):
{
const label = 'API call composition';
// a => Promise(b)
const getUserById = id => id === 3 ?
Promise.resolve({ name: 'Kurt', role: 'Author' }) :
undefined
;
// b => Promise(c)
const hasPermission = ({ role }) => (
Promise.resolve(role === 'Author')
);
// 尝试组合上面两个任务,注意:这个例子会失败
const authUser = compose(hasPermission, getUserById);
// 总是输出 false
authUser(3).then(trace(label));
}当我们尝试组合 hasPermission() 和 getUserById() 为 authUser() 时,我们遇到了一个大问题,由于 hasPermission() 接收一个 User 对象作为输入,但却得到的是 Promise(User)。为了解决这个问题,我们需要创建一个特别地组合函数 composePromises() 来替换掉原来的compose(),这个组合函数知道使用 .then() 去完成函数组合:
{
const composeM = chainMethod => (...ms) => (
ms.reduce((f, g) => x => g(x)[chainMethod](f))
);
const composePromises = composeM('then');
const label = 'API call composition';
// a => Promise(b)
const getUserById = id => id === 3 ?
Promise.resolve({ name: 'Kurt', role: 'Author' }) :
undefined
;
// b => Promise(c)
const hasPermission = ({ role }) => (
Promise.resolve(role === 'Author')
);
// 组合函数,这次大功告成了!
const authUser = composePromises(hasPermission, getUserById);
authUser(3).then(trace(label)); // true
}稍后我们会讨论 composeM() 的细节。
再次牢记 Monad 的实质:
- 函数 map:
a => b - 具有 Functor context 的 map:
Functor(a) => Functor(b) - 具备 Monad context,且需要 flatten 的 map:
Monad(Monad(a)) => Monad(b)
在这个例子中,我们的 Monad 是 Promise,所以当我们组合这些返回 Promise 的函数时,对于 hasPermission() 函数,它得到的是 Promise(User) 而不是 Promise 中装有的 User 。注意到,如果你去除了 Monad(Monad(a)) 中外层 Monad() 的包裹,就剩下了 Monad(a) => Monad(b),这就是 Functor 中的 .map()。如果我们再有某种手段能够展开 Monad(x) => x 的话,就走上正轨了。
Monad 的构成
每个 Monad 都是基于一种简单的对称性 -- 一个将值包裹到 context 的方式,以及一个取消 context 包裹,将值取出的方式:
- Lift/Unit:将某个类型提升到 Monad 的 context 中:
a => M(a) - Flatten/Join:去除 context 包裹:
M(a) => a
由于 Monad 也是 Functor,因此它们能够进行 map 操作:
- Map:进行保留 context 的 map:
M(a) -> M(b)
组合 flatten 以及 map,你就能得到 chain -- 这是一个用于 monad-lifting 函数的函数组合,也称之为 Kleisli 组合,名称来自 Heinrich Kleisli:
- FlatMap/Chain: flatten 以后再进行 map:
M(M(a)) => M(b)
对于 Monad 来说,.map() 方法通常从公共 API 中省略了。type lift 和 flatten 不会显示地要求.map() 调用,但你已经有了 .map() 所需要的全部。如果你能够 lift(也称为 of/unit) 以及 chain(也称为 bind/flatMap),你就能完成 .map(),即完成 Monad 中值的映射:
const MyMonad = value => ({
// <... 这里可以插入任意的 chain 和 of ...>
map (f) {
return this.chain(a => this.constructor.of(f(a)));
}
});所以,如果你为 Monad 定义了 .of() 和 .chain() 或者 .join() ,你就可以推导出.map() 的定义。
lift 可以由工厂函数、构造方法或者 constructor.of() 完成。在范畴学中,lift 叫做 “unit”。list 完成的是将某个类型提升到 Monad context。它将某个 a 转换到了一个包裹着 a 的 Monad。
在 Haskell 中,很令人困惑的是,lift 被叫做 return,一般我们认为的 return 指的都是函数返回。我仍有意将它称之为 “lift” 或者 “type lift”,并在代码中使用 .of() 完成 lift,这样更符合我们的理解。
flatten 过程通常被叫做 flatten() 或者 join()。多数时候,我们用不上 flatten() 或者join(),因为它们内联到了 .chain() 或者 .flatMap() 中。flatten 通常会配合上 map 操作在组合中使用,因为去除 context 包裹以及 map 都是组合中 a => M(a) 需要的。
去除某类 Monad 可能是非常简单的。例如 Identity Monad,Identity Monad 的 flatten 过程类似它的 .map() 方法,只不过你不用将返回的值提升回 Monad context。Identity Monad 去除一层包裹的例子如下:
{ // Identity monad
const Id = value => ({
// Functor Maping
// 通过将被 map 的值传入到 type lift 方法 .of() 中
// 使得 .map() 维持住了 Monand context 包裹:
map: f => Id.of(f(value)),
// Monad chaining
// 通过省略 .of() 进行的类型提升
// 去除了 context 包裹,并完成 map
chain: f => f(value),
// 一个简便方法来审查 context 包裹的值:
toString: () => `Id(${ value })`
});
// 对于 Identity Monad 来说,type lift 函数只是这个 Monad 工厂的引用
Id.of = Id;但是去除 context 包裹也会与诸如副作用,错误分支,异步 IO 这些怪家伙打交道。在软件开发过程中,组合是真正有意思的事儿发生的地方。
例如,对于 Promise 对象来说,.chain() 被称为 .then()。调用 promise.then(f) 不会立即f()。取而代之的是,then(f) 会等到 Promise 对象被 resolve 后,才调用 f() 进行 map,这也是 then 命名的来由:
{
const x = 20; // 值
const p = Promise.resolve(x); // context
const f = n =>
Promise.resolve(n * 2); // 函数
const result = p.then(f); // 应用程序
result.then(
r => console.log(r) // 结果:40
);
}对于 Promise 对象,.then() 就用来替代 .chain(),但其实二者完成的是同一件事儿。
可能你听到说 Promise 不是严格意义上的 Monad,这是因为只有 Promise 包裹的值是 Promise 对象时,.then() 才会去除外层 Promise 的包裹,否则它会直接做 .map(),而不需要 flatten。
但是由于 .then() 对 Promise 类型的值和其他类型的值处理不同,因此,它不会严格遵守数学上 Functor 和 Monad 对任何值都必须遵守的定律。实际上,只要你知道 .then() 在处理不同数据类型上的差异,你也可以把它当做是 Monad。只需要留意一些通用组合工具可能无法工作在 Promise 对象上。
构建 monadic 组合(也叫做 Kleisli 组合)
让我们深入到 composeM 函数里面看看,这个函数我们用来组合 promise-lifting 的函数:
const composeM = method => (...ms) => (
ms.reduce((f, g) => x => g(x)[method](f))
);藏在古怪 reducer 里面的是函数组合的代数定义:f(g(x))。如果我们想要更好地理解composeM,先看看下面的代码:
{
// 函数组合的算数定义:
// (f ∘ g)(x) = f(g(x))
const compose = (f, g) => x => f(g(x));
const x = 20; // 值
const arr = [x]; // 值的容器
// 待组合的函数
const g = n => n + 1;
const f = n => n * 2;
// 下面代码证明了 .map() 完成了函数组合
// 对 map 的链式调用完成了函数组合
trace('map composes')([
arr.map(g).map(f),
arr.map(compose(f, g))
]);
// => [42], [42]
}这段代码意味着我们可以撰写一个泛化的组合工具来服务于任何能够应用 .map() 方法的 Fucntor,例如数组等:
const composeMap = (...ms) => (
ms.reduce((f, g) => x => g(x).map(f))
);这个函数是 f(g(x)) 另一个表述形式。给定任意数量的、发生类型提升的函数 a -> Functor(b),迭代待组合的函数,它们接受输入 x,并通过 .map(f) 完成 map 和 type lift。.reduce() 方法接受一个两参数函数:一个参数是累加器(本例中是 f,表示组合后的函数),另一个参数是当前值(本例中是当前函数 g)。
每次迭代都返回了一个新的函数 x => g(x).map(f),这个新函数也是下一次迭代中的 f。我们已经证明 x => g(x).map(f) 等同于将 compose(f, g)(x) 的值提升到 Functor 的 context 中。换言之,即等同于对 Functor 中的值应用 f(g(x)),在本例中,这指的是对原数组中的值应用组合后的函数进行 map。
性能警告:我不建议对数组这么做。以这种方式组合函数将要求对整个数组进行多重迭代,假如数组规模很大,这样做的时间开销很大。对于数组进行 map,要么进行简单函数组合
a -> b,再在数组上一次性应用组合后的函数,要么优化.reducer()的迭代过程,要么直接使用一个 transducer。译注:transducer 是一个函数,其名称复合了 transform 和 reducer。transducer 即为每次迭代指明了 tramsform 的 reducer:
const increment = x => x + 1 const square = x => x * x const transducer = R.map(R.compose(square, increment)) const data = [1, 2, 3] const initialData = [0] const accumulator = R.flip(R.append) R.transduce(transducer, accumulator, initialData, data) // => [0, 4, 9, 16]上述代码相当于:
const increment = x => x + 1 const square = x => x * x const transform = R.compose(square, increment) const data = [1, 2, 3] const initialData = [0] data.reduce((acc, curr) => acc.concat([transform(curr)]), initialData) // => [0, 4, 9, 16]参考资料: ramda
.transduce()。
对于同步任务,数组的映射函数都是立即执行的,因此需要关注性能。然而,多数的异步任务都是延迟执行的,并且这部分任务通常需要应对异常或者空值这样的令人头痛分支状况。
这样的场景对 Monad 再合适不过了。在组合链中,当前 Monad 需要的值需要上一步异步任务或者分支完成时才能获得。在这些情景下,你无法在组合外部拿到值,因为它们被一个 context 包裹住了,组合过程是 a => Monad(b) 而不是 a => b。
无论何时你的一个函数接收了一些数据,触发了一个 API,返回了对应的值,另一个函数接收了这些值,触发了另一个 API,并且返回了这些数据的计算结果,你会想要使用 a => Monad(b) 来组合这些函数。由于 API 调用是异步的,你会需要将返回值包上类似 Promise 或者 Observable 这样的 context。换句话说,这些函数的签名会是 a -> Monad(b) 以及 b -> Monad(c)。
组合 g: a -> b, f: b -> c 类型的函数是很简单的,因为输入输出是整齐划一的。h: a -> c 这个变化只需要 a => f(g(a))。
组合 g: a -> Monad(b), f: b -> Monad(c) 就稍微有些困难。h: a -> Monad(c) 这个变化不能通过 a => f(g(a)) 完成,因为 f() 需要的是 b,而不是 Monad(b)。
让我们看一个更具体的例子,我们组合了一系列异步任务,它们都返回 Promise 对象:
{
const label = 'Promise composition';
const g = n => Promise.resolve(n + 1);
const f = n => Promise.resolve(n * 2);
const h = composePromises(f, g);
h(20)
.then(trace(label))
;
// Promise composition: 42
}怎么才能写一个 composePromises() 对异步任务进行组合,并获得预期输出呢?提示:你之前可能见到过。
对的,就是我们提到过的 composeMap() 函数?现在,你只需要将其内部使用的 .map() 换成.then() 即可,Promise.then() 相当于异步的 .map()。
{
const composePromises = (...ms) => (
ms.reduce((f, g) => x => g(x).then(f))
);
const label = 'Promise composition';
const g = n => Promise.resolve(n + 1);
const f = n => Promise.resolve(n * 2);
const h = composePromises(f, g);
h(20)
.then(trace(label))
;
// Promise composition: 42
}稍微有些古怪的地方在于,当你触发了第二个函数 f,传给 f 的不是它想要的 b,而是Promise(b),因此 f 需要去除 Promise 包裹,拿到 b。接下来该怎么做呢?
幸运的是,在 .then() 内部,已经拥有了一个将 Promise(b) 展平为 b 的过程了,这个过程通常称之为 join 或者 flatten。
也许你已经留意到了 composeMap() 和 composePromise() 的实现几乎一样。因此我们创建一个高阶函数来为不同的 Monad 创建组合函数。我们只需要将链式调用需要的函数混入一个柯里化函数即可,之后,使用方括号包裹这个链式调用需要的方法名:
const composeM = method => (...ms) => (
ms.reduce((f, g) => x => g(x)[method](f))
);现在,我们能针对性地为不同的 Monad 创建组合函数:
const composePromises = composeM('then');
const composeMap = composeM('map');
const composeFlatMap = composeM('flatMap');Monda 定律
在你开始创建你的 Monad 之前,你需要知道所有的 Monad 都要满足的一些定律:
- 左同一律:
unit(x).chain(f) ==== f(x)(译注:将x提升到 Monad context 后,使用f()进行 map,等同于直接对x直接使用f进行 map) - 右同一律:
m.chain(unit) ==== m(译注:Monad 对象进行 map 操作的结果等于原对象 ) - 结合律:
m.chain(f).chain(g) ==== m.chain(x => f(x).chain(g))
同一律(Identity Law)
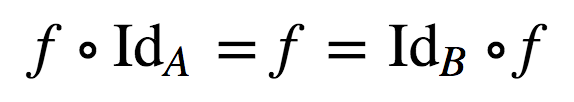 左同一律及右同一律
左同一律及右同一律
一个 Monad 也是一个 Functor。一个 Functor 是两个范畴之间一个态射(morphism):A -> B,其中箭头符号即描述了态射。除了对象间显式的态射,每一个范畴中的对象也拥有一个指向自己的箭头。换言之,对于范畴中的每一个对象 X,存在着一个箭头 X -> X。该箭头称之为同一(identity)箭头,通常使用一个从自身出发并指回自身的弧形箭头表示。
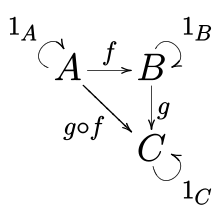 同一态射
同一态射
结合律(Associativity)
结合律意味着我们不需要关心我们组合时在哪里放置括号。如果我们是在做加法,加法有结合律: a + (b + c) 等同于 (a + b) + c。这对于函数组合也同样适用: (f ∘ g) ∘ h = f ∘ (g ∘ h)。
并且,这对于 Kleisli 组合仍然适用。对于这种组合,你应该从前往后地看,把组合运算chain 当作是 after 即可:
h(x).chain(x => g(x).chain(f)) ==== (h(x).chain(g)).chain(f)Monda 的定律证明
接下来我们证明同一 Monad 满足 Monad 定律:
{ // Identity monad
const Id = value => ({
// Functor Maping
// 通过将被 map 的值传入到 type lift 方法 .of() 中
// 使得 .map() 维持住了 Monand context 包裹:
map: f => Id.of(f(value)),
// Monad chaining
// 通过省略 .of() 进行的类型提升
// 去除了 context 包裹,并完成 map
chain: f => f(value),
// 一个简便方法来审查 context 包裹的值:
toString: () => `Id(${ value })`
});
// 对于 Identity Monad 来说,type lift 函数只是这个 Monad 工厂的引用
Id.of = Id;
const g = n => Id(n + 1);
const f = n => Id(n * 2);
// 左同一律
// unit(x).chain(f) ==== f(x)
trace('Id monad left identity')([
Id(x).chain(f),
f(x)
]);
// Id Monad 左同一律: Id(40), Id(40)
// 右同一律
// m.chain(unit) ==== m
trace('Id monad right identity')([
Id(x).chain(Id.of),
Id(x)
]);
// Id Monad right identity: Id(20), Id(20)
// 结合律
// m.chain(f).chain(g) ====
// m.chain(x => f(x).chain(g)
trace('Id monad associativity')([
Id(x).chain(g).chain(f),
Id(x).chain(x => g(x).chain(f))
]);
// Id monad associativity: Id(42), Id(42)
}总结
Monad 是组合类型提升函数的方式:g: a => M(b), f: b => M(c)。为了做到,Monad 必须在应用函数 f() 之前,展平 M(b) 取出 b 交给 f()。换言之,Functor 是你可以进行 map 操作的对象,而 Monad 是你可以进行 flatMap 操作的对象:
- 函数 map:
a => b - 具有 Functor context 的 map:
Functor(a) => Functor(b) - 具备 Monad context,且需要 flatten 的 map:
Monad(Monad(a)) => Monad(b)
每个 Monad 都是基于一种简单的对称性 -- 一个将值包裹到 context 的方式,以及一个取消 context 包裹,将值取出的方式:
- Lift/Unit:将某个类型提升到 Monad 的 context 中:
a => M(a) - Flatten/Join:去除 context 包裹:
M(a) => a
由于 Monad 也是 Functor,因此它们能够进行 map 操作:
- Map:进行保留 context 的 map:
M(a) -> M(b)
组合 flatten 以及 map,你就能得到 chain -- 这是一个用于 monad-lifting 函数的函数组合,也称之为 Kleisli 组合。
- FlatMap/Chain: flatten 以后再进行 map:
M(M(a)) => M(b)
Monads 必须满足三个定律(公理),合在一起称之为 Monad 定律:
- 左同一律:
unit(x).chain(f) ==== f(x) - 右同一律:
m.chain(unit) ==== m - 结合律:
m.chain(f).chain(g) ==== m.chain(x => f(x).chain(g)
每天撰写 JavaScript 代码的时候,你或多或少已经在使用 Monad 或者 Monad 类似的东西了,例如 Promise 和 Observable。Kleisli 组合允许你组合数据流逻辑时不用操心组合中的数据类型,也不用担心可能发生的副作用,条件分支,以及其他一些组合中去除 context 包裹时的细节,这些细节全部都藏在了 .chain() 操作中。
这一切都让 Monad 在简化代码中扮演了重要角色。在阅读文本之前,兴许你还不明白 Monad 内部到底做了什么就已经从 Monad 中受益颇丰,现在,你对 Monad 底层细节也有了一定认识,这些细节也并不可怕。
回到开头,我们不用再惧怕 Lady Monadgreen 的诅咒了。
通过一对一辅导提升你的 JavaScript 技巧
DevAnyWhere 能帮助你最快进阶你的 JavaScript 能力:
- 直播课程
- 灵活的课时
- 一对一辅导
- 构建真正的应用产品
Eric Elliott 是 “编写 JavaScript 应用” (O’Reilly) 以及 “跟着 Eric Elliott 学 Javascript” 两书的作者。他为许多公司和组织作过贡献,例如 Adobe Systems、Zumba Fitness、The Wall Street Journal、ESPN 和 BBC 等 , 也是很多机构的顶级艺术家,包括但不限于Usher、Frank Ocean 以及 Metallica。
大多数时间,他都在 San Francisco Bay Area,同这世上最美丽的女子在一起。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









