






回到二分搜索树内容,更加高级的话题,平衡二叉树。
我们之前实现的那个二叉树在最差情况下会退化成链表,在现有二分搜索树基础上添加一定的机制,使得二分搜索树可以维持平衡二叉树性质。AVL树就是一种经典的平衡二叉树。
两个发明人首字母缩写: G. M. Adelson-Velsky和 E.M.Landis 1962年的论文首次提出
通常认为AVL树时一种最早的可以自平衡二分搜索树结构
什么是平衡二叉树?
一棵满二叉树一定是一棵平衡二叉树,之前在二分搜索树部分,具体的推导二分搜索树平均的时间复杂度时,基于满二叉树进行的推导。显然满二叉树可以让整棵树的高度最低。
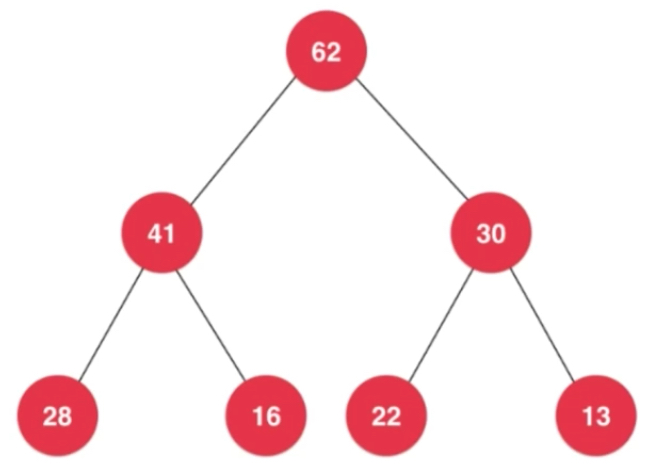
除了叶子节点,其他节点都有左右两孩子。通常不会正好这么巧的填满,堆: 完全二叉树,空缺部分在右下角,完全二叉树中叶子节点深度值相差不会超过1,叶子节点不在最后一层,就在倒数第二层。
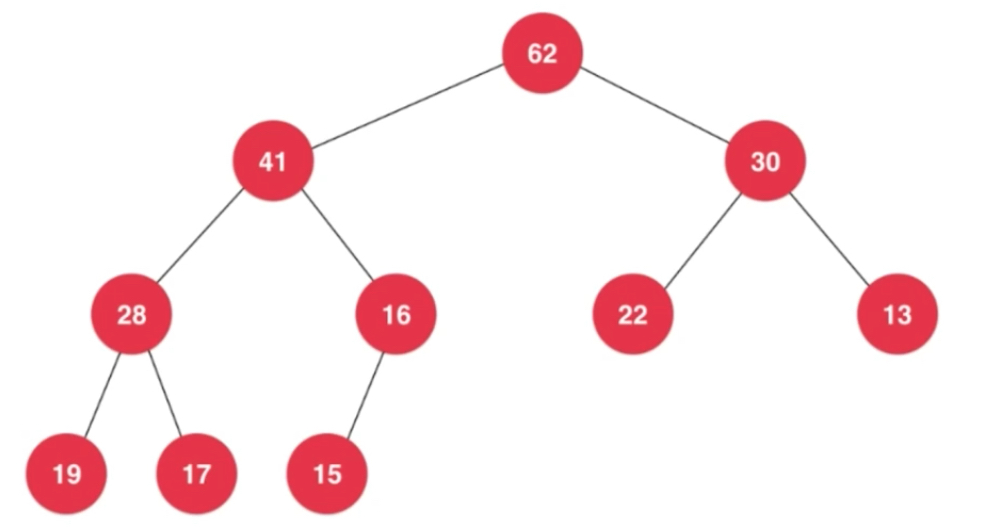
线段树: 也是一种平衡二叉树
空出来的节点不一定在右下角,但是叶子节点深度值相差不会超过1,叶子节点不在最后一层,就在倒数第二层。
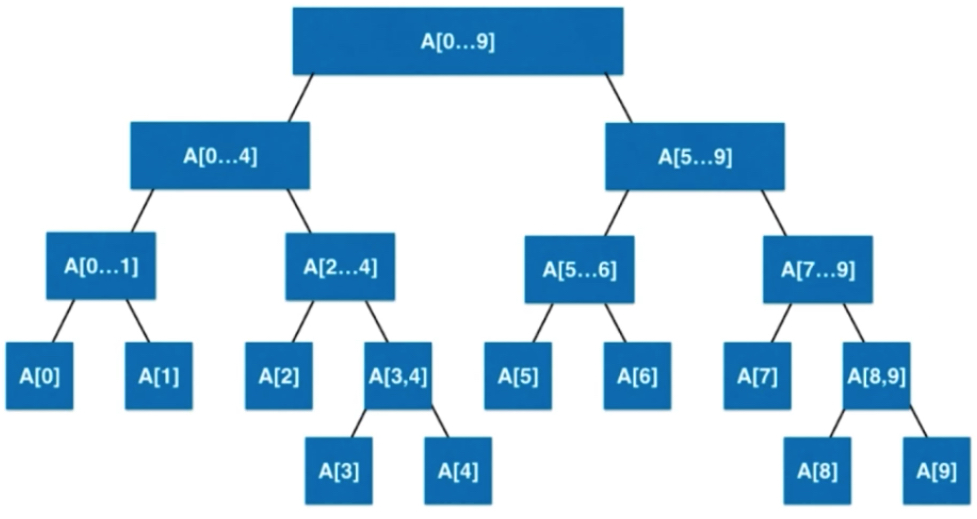
上面的这几种平衡二叉树叶子节点深度值不超过1是比较理想的平衡二叉树。
平衡二叉树定义
对于任意一个节点,左子树和右子树的高度差不能超过1
堆和线段树可以保证叶子节点高度不超过1,而平衡二叉树的定义宽泛,导致可能看起来树没有那么平衡。
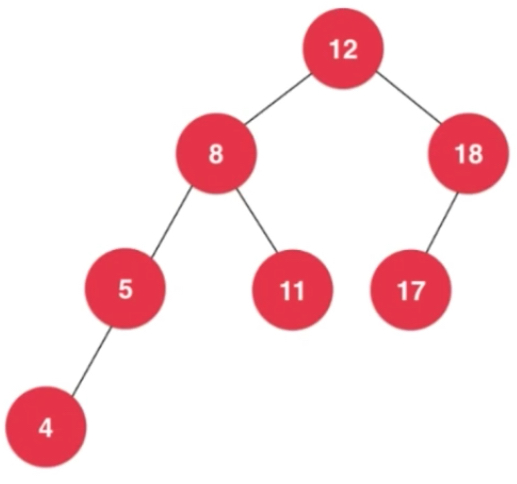
如上图,满足平衡二叉树,不满足堆,也不是完全二叉树。平衡二叉树的高度和节点数量之间的关系也是O(logn)的
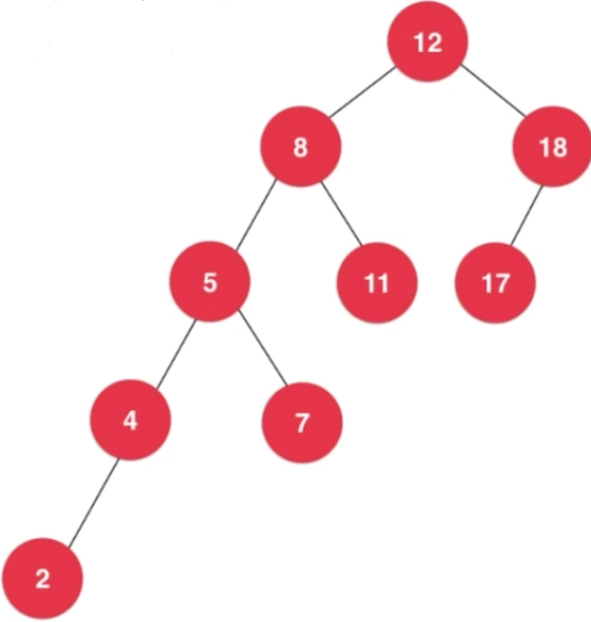
如果按之前二叉树的添加值的方式,添加2,7节点之后,整棵树已经不满足平衡二叉树的要求了。我们需要向右填补偏斜。每一个节点都要记录标注节点的高度。
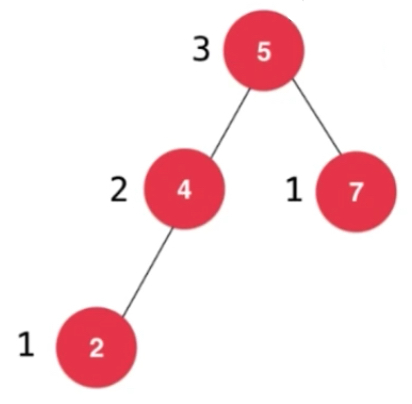
最高的子树高度+1
平衡因子
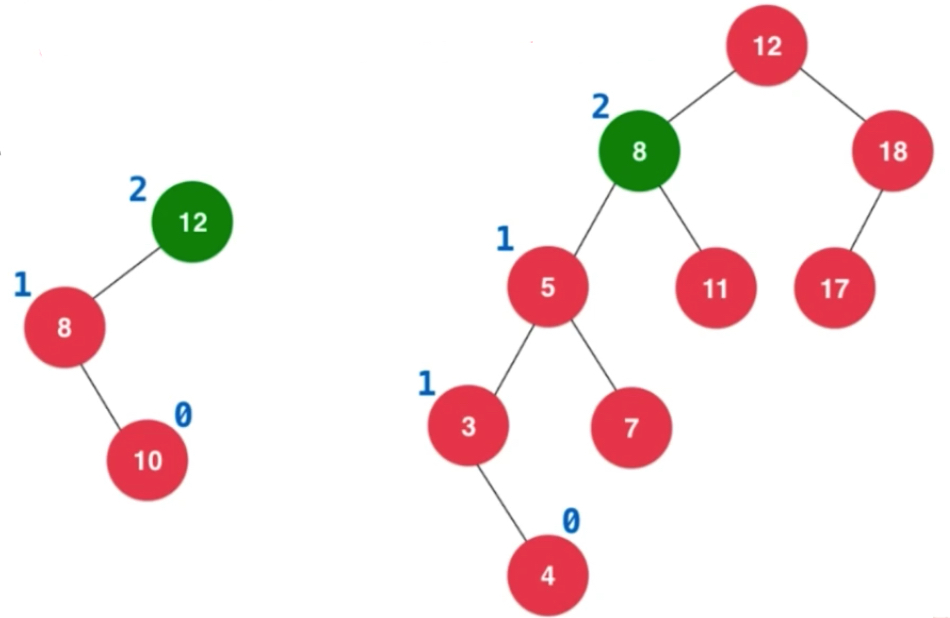
计算平衡因子: 每一个节点左右子树高度差,左子树高度减去右子树高度。叶子节点的平衡因子为0,如下图为标注的平衡因子,8的平衡因子为2,意味着8的左右子树高度差已经超过1了,这棵树已经不是平衡二叉树了。平衡因子绝对值大于等于2,就不是。
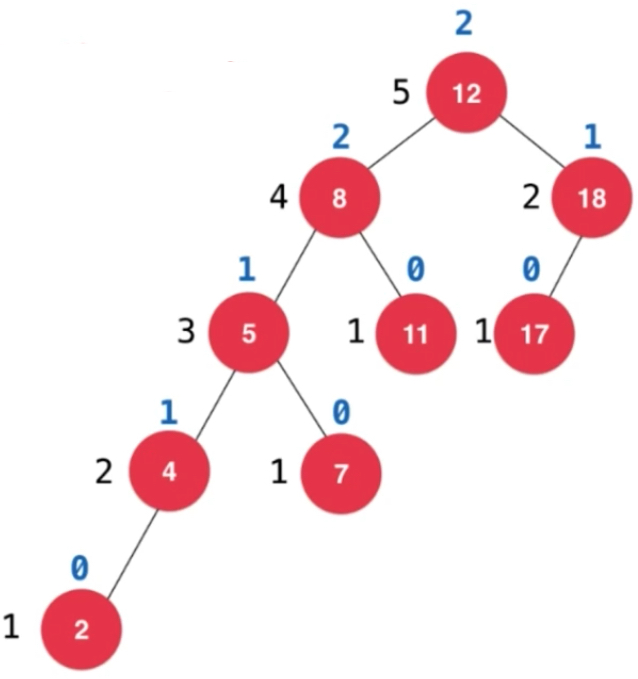
我们现在的这棵树相当于有两个节点8和12破坏了平衡二叉树的性质。借助平衡因子看要不要对节点进行特殊操作。
计算节点的高度和平衡因子
private class Node {
public K key; // 节点key
public V value;
public Node left, right; // 左子树,右子树引用
public int height; // 节点高度
/**
* 默认的节点构造函数
*
* @param key
* @param value
*/
public Node(K key, V value) {
this.key = key;
this.value = value;
left = null;
right = null;
height = 1;
}
}
添加节点高度值,初始化构造时置为1。
/**
* 获得节点node的高度
* @param node
* @return
*/
private int getHeight(Node node){
if (node == null)
return 0;
return node.height;
}
添加节点时维护高度值。
添加更新height的操作。
/**
* 计算节点node的平衡因子
*
*/
private int getBalanceFactor(Node node){
if (node == null)
return 0;
return getHeight(node.left) - getHeight(node.right);
}
/**
* 返回插入新的键值对后二分搜索树的根
*
* @param node
* @param key
* @param value
* @return
*/
private Node add(Node node, K key, V value) {
if (node == null) {
size++;
return new Node(key, value);
}
// 上面条件不满足,说明还得继续往下找左右子树为null可以挂载上的节点
if (key.compareTo(node.key) < 0)
// 如果e小于node.e,那么继续往它的左子树添加该节点,这里插入结果可能根发生了变化。
node.left = add(node.left, key, value); // 新节点赋值给node.left,改变了二叉树
else if (key.compareTo(node.key) > 0)
// 大于,往右子树添加。
node.right = add(node.right, key, value);
// 如果相等
else
node.value = value;
// 更新height
node.height = 1 + Math.max(getHeight(node.left),getHeight(node.right));
return node;
}
int balanceFactor = getBalanceFactor(node);
if (Math.abs(balanceFactor) >1 )
System.out.println("unbalanced: "+ balanceFactor);
添加元素时除了对于height的更新还应该对于平衡因子进行判断。
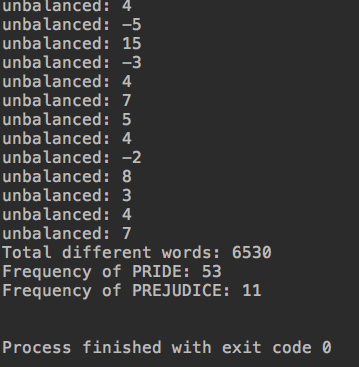
可以看到有很多不平衡的,虽然我们之前二分搜索树性能已经不错了。二分搜索树高度不平衡,有很大优化空间。
检查二分搜索树性质和平衡性
AVL树是对于二分搜索树的改进,必须也要满足二分搜索树的条件。
/**
* 判断该二叉树是否是一棵二分搜索树
* @return
*/
public boolean isBST(){
ArrayList<K> keys = new ArrayList<>();
inOrder(root, keys);
// 判断是否是一个升序数组
for(int i = 1 ; i < keys.size() ; i ++)
if(keys.get(i - 1).compareTo(keys.get(i)) > 0)
return false;
return true;
}
/**
* 二分搜索树中序遍历
* @param node
* @param keys
*/
private void inOrder(Node node, ArrayList<K> keys){
if(node == null)
return;
inOrder(node.left, keys);
keys.add(node.key);
inOrder(node.right, keys);
}
判断当前树还否是二分搜索树,性质: 二分搜索树的中序遍历元素是否是顺序排列的。
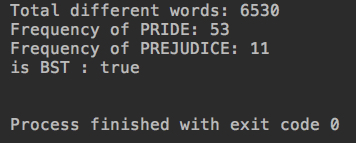
System.out.println("is BST : " + map.isBST());
辅助函数,是否是一个平衡二叉树
/**
* 判断该二叉树是否是一棵平衡二叉树
* @return
*/
public boolean isBalanced(){
return isBalanced(root);
}
/**
* 判断以Node为根的二叉树是否是一棵平衡二叉树,递归算法
* @param node
* @return
*/
private boolean isBalanced(Node node){
if(node == null)
return true;
int balanceFactor = getBalanceFactor(node);
if(Math.abs(balanceFactor) > 1)
return false;
return isBalanced(node.left) && isBalanced(node.right);
}
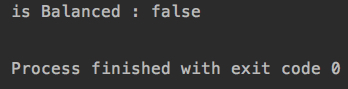
System.out.println("is Balanced : " + map.isBalanced());
AVL旋转操作的基本原理
AVL树的左旋转和右旋转;在什么时候维护平衡
二分搜索树中插入节点,寻找正确插入位置。
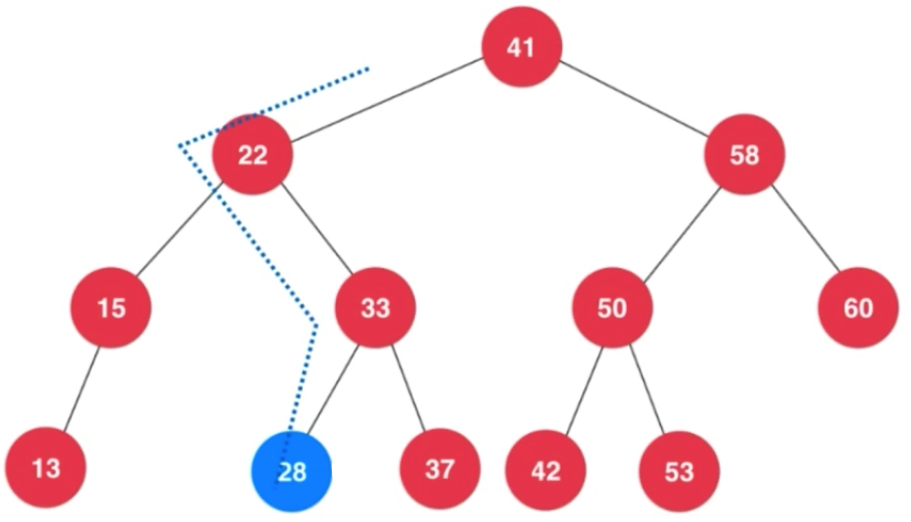
因为我们新插入的这个节点才有可能导致二分搜索树不满足平衡性,因此不平衡性只有可能发生在我们从该节点一路往上找,直到父亲节点。新插入节点破坏平衡性,反映在它的父亲节点以及祖先节点上。因为插入它,会更新它的父亲及祖先节点,这时就有可能更新之后大于1。
从空开始,加入12,加入8
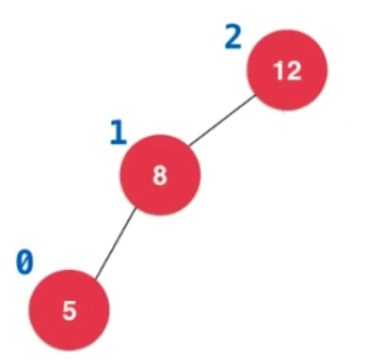
此时再添加5,就会一路向上更新平衡因子,造成12的平衡因子已经变成了2
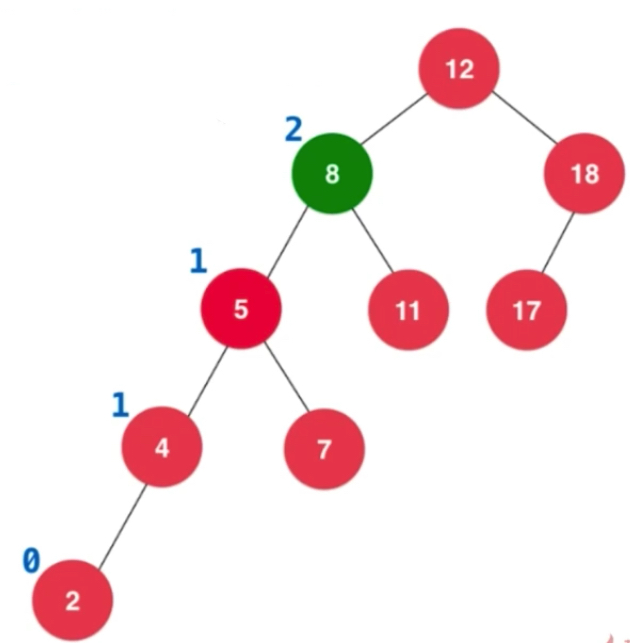
加入2之后,向上更新平衡因子,造成8的平衡因子大于1了。插入的元素在不平衡的节点的左侧的左侧
加入节点后,沿着节点向,上维护平衡性。
// 平衡维护
if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0)
; // 实现平衡维护,下一小节进行具体实现:)
此时要进行的操作是右旋转。y节点已经不满足平衡二叉树的性质了,且左子树高度高于右子树,左孩子的情况也是同样的左子树大于右子树。整体向左倾斜。
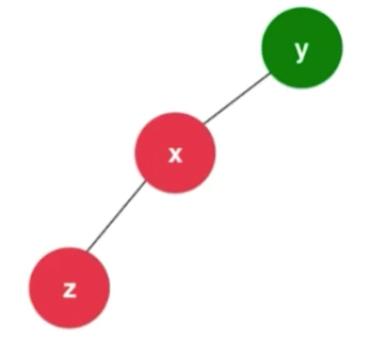
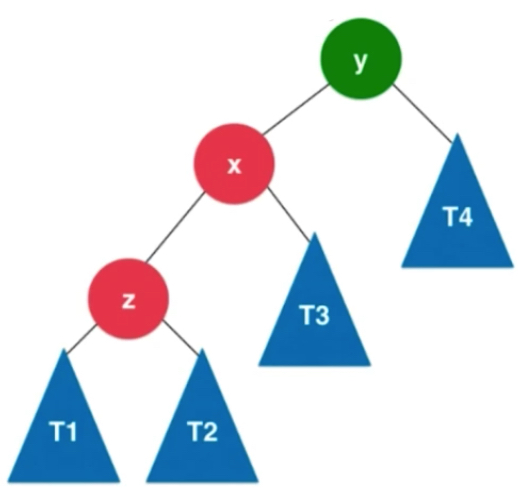
满足条件的是y和x的左子树都大于右子树。T1 <z< T2<x< T3<y< T4 使得y保持平衡性,
右旋转过程: x的右子树变成以y为根的子树。T3先扔一边,x的右子树变为y连带着t4
x.right = y
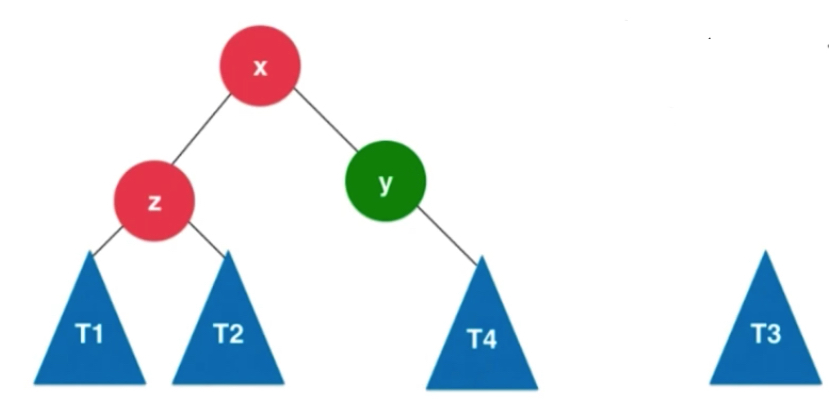
y.left = T3
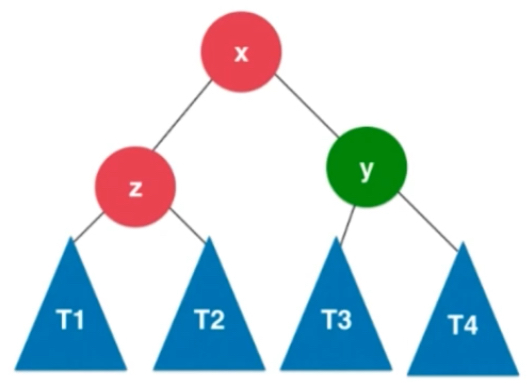
此时让x变成这棵树的新的根节点,就成为右旋转。相当于y顺时针的转到了x的右边,新的二叉树是满足二分搜索树的,也是满足平衡二叉树的。
T1 <z< T2<x< T3<y< T4的关系,可以看出仍然保持二分搜索树
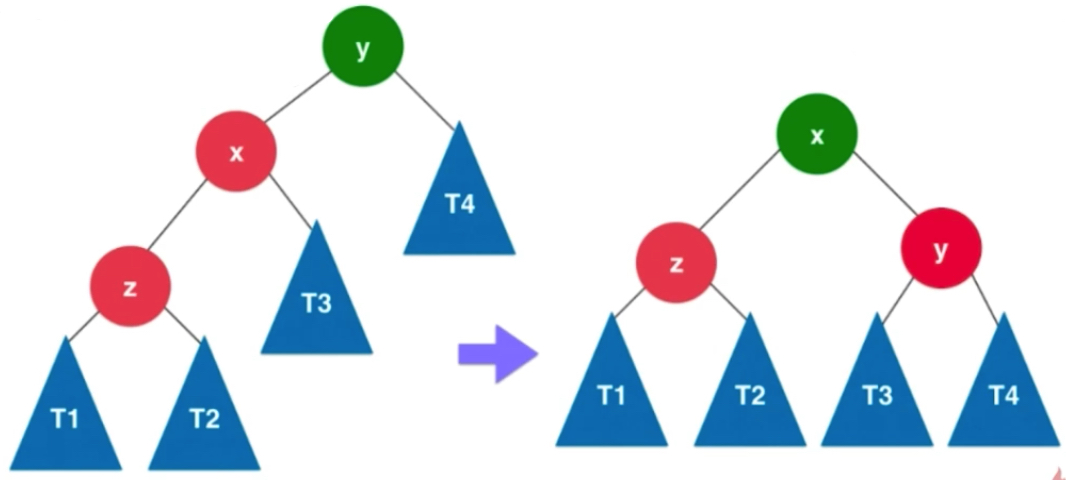
由于左侧中y是不平衡的节点,x和z为根的是平衡的,不然从加入节点不断向上回溯,找到的第一个不平衡节点就不应该是y了。所以对于以z为根的二叉树,它是平衡的二叉树,变到右边依然是平衡的。如果z保持了平衡性,t1和t2的高度差不会超过1。假设t1 和t2中最大的高度值为h,相应z这个节点的高度值就是h+1,右侧z1也是h+1。由于x也是保持平衡的,并且x的平衡因子是>=0的,左子树的高度是大于等于右子树的高度的,因为x也是平衡的,所以它的平衡因子最大为1,它的平衡因子要么是0,要么是1。对应就是t3这棵树的高度要么是h,要么是h+1。x的高度就是h+2。y节点打破了平衡,也就是它的左右子树的高度差是大于1的,但是最大也就是2了,因为y原本平衡,一个节点加入y,只有一个只会从1变2,因此t4为h。y左右子树高度差最多为1.y的可能取值时h+2 或h+1 此时y,z来看x,x也是平衡的。
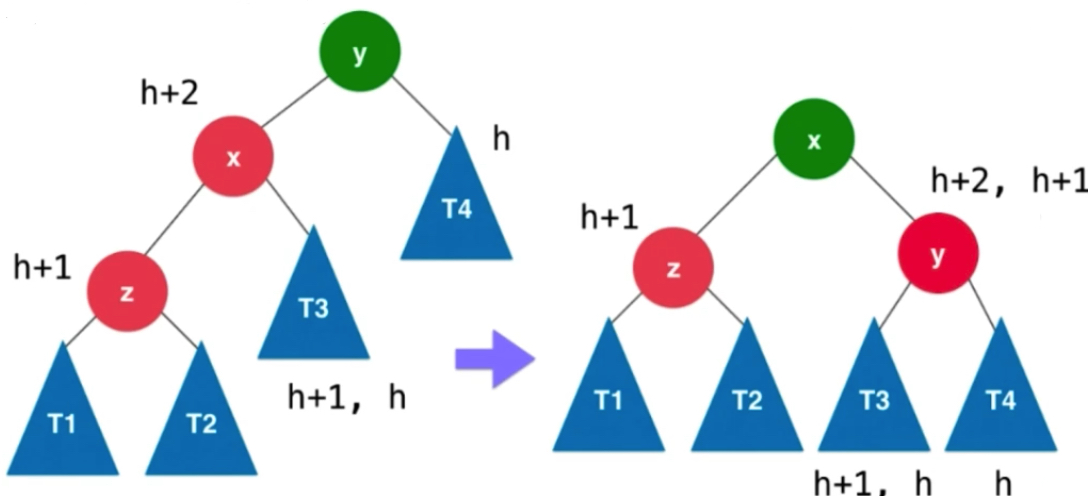
可以看到左边转到右边,从x角度来看,X节点依然平衡,整棵树依然平衡。
左旋转和右旋转的实现。
左旋转: 插入的元素在不平衡的节点的右侧的右侧
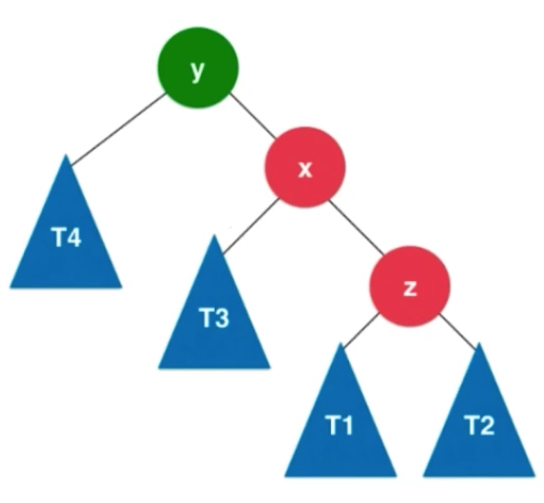
x.left = y;
y.right = T3;
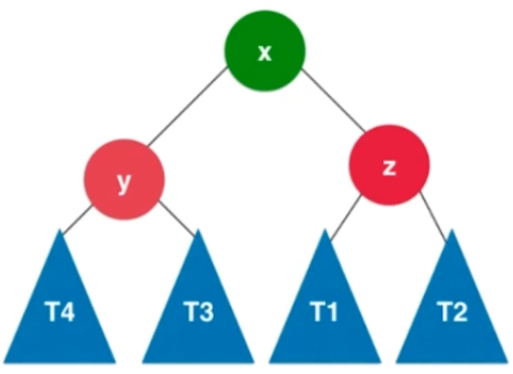
// 对节点y进行向右旋转操作,返回旋转后新的根节点x
// y x
// / \ / \
// x T4 向右旋转 (y) z y
// / \ - - - - - - - -> / \ / \
// z T3 T1 T2 T3 T4
// / \
// T1 T2
private Node rightRotate(Node y) {
Node x = y.left;
Node T3 = x.right;
// 向右旋转过程
x.right = y;
y.left = T3;
// 更新height
y.height = Math.max(getHeight(y.left), getHeight(y.right)) + 1;
x.height = Math.max(getHeight(x.left), getHeight(x.right)) + 1;
return x;
}
// 对节点y进行向左旋转操作,返回旋转后新的根节点x
// y x
// / \ / \
// T1 x 向左旋转 (y) y z
// / \ - - - - - - - -> / \ / \
// T2 z T1 T2 T3 T4
// / \
// T3 T4
private Node leftRotate(Node y) {
Node x = y.right;
Node T2 = x.left;
// 向左旋转过程
x.left = y;
y.right = T2;
// 更新height
y.height = Math.max(getHeight(y.left), getHeight(y.right)) + 1;
x.height = Math.max(getHeight(x.left), getHeight(x.right)) + 1;
return x;
}
先更新y的高度值。
// 平衡维护
if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0)
return rightRotate(node);
if (balanceFactor < -1 && getBalanceFactor(node.right) <= 0)
return leftRotate(node);
return node;
LR 和 RL
插入的元素在不平衡的节点的左侧的左侧; 右侧的右侧。
如上图所示就不是简单的左旋转或者右旋转可以解决的。
LL 和 RR 是我们上一小节处理的。
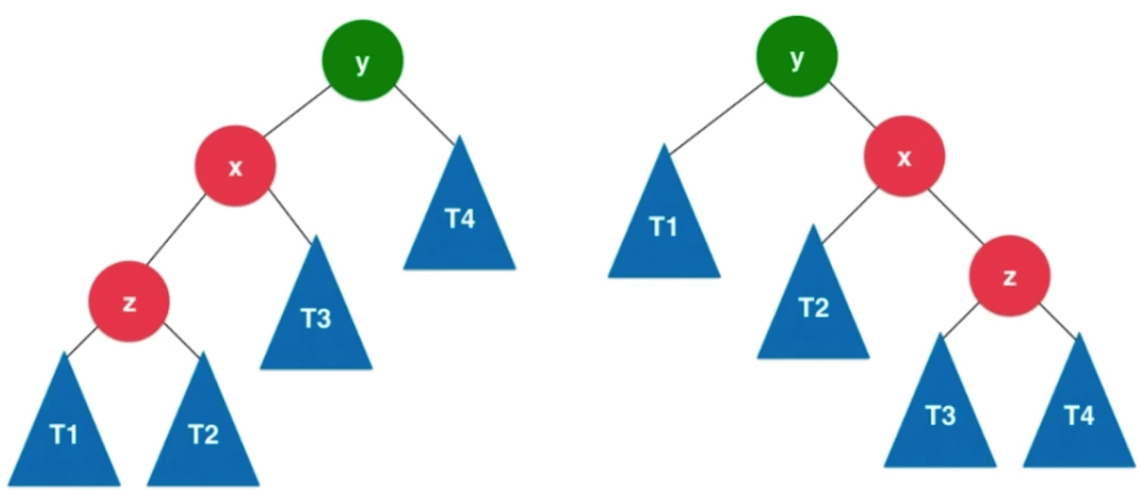
左左 LL 右右 RR
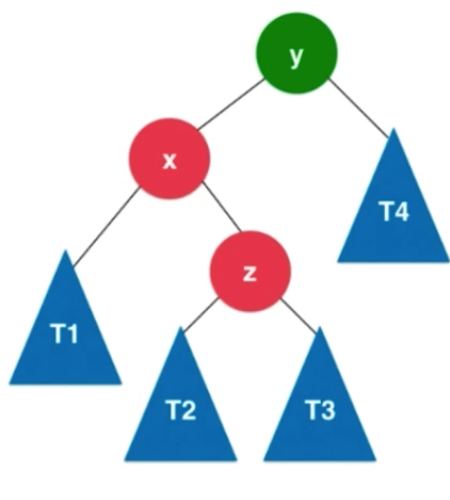
先插入元素在左孩子的右侧。首先对x进行左旋转,转化为了LL的情况,再对y进行右旋转。
RL
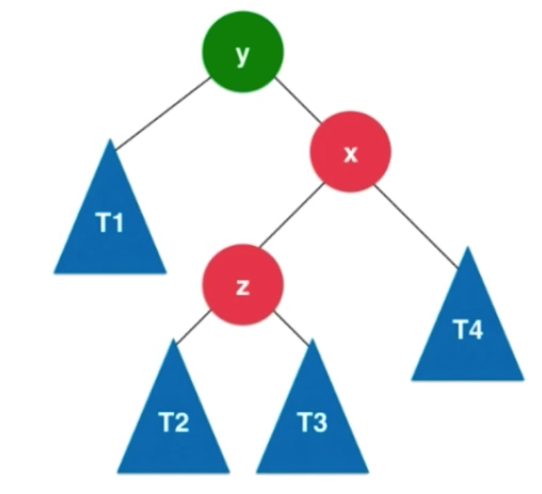
首先对x进行右旋转,转化成了RR的情况,Y节点进行左旋转。
if (balanceFactor > 1 && getBalanceFactor(node.left) < 0) {
node.left = leftRotate(node.left);
return rightRotate(node);
}
if (balanceFactor < -1 && getBalanceFactor(node.right) > 0) {
node.right = rightRotate(node.right);
return leftRotate(node);
}
运行结果:
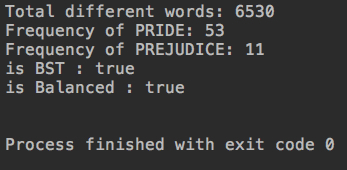
保持平衡,不会退化成链表
package cn.mtianyan;
import java.util.ArrayList;
import java.util.Collections;
public class Main {
public static void main(String[] args) {
System.out.println("Pride and Prejudice");
ArrayList<String> words = new ArrayList<>();
if(FileOperation.readFile("pride-and-prejudice.txt", words)) {
System.out.println("Total words: " + words.size());
Collections.sort(words);
// Test BST
long startTime = System.nanoTime();
BST<String, Integer> bst = new BST<>();
for (String word : words) {
if (bst.contains(word))
bst.set(word, bst.get(word) + 1);
else
bst.add(word, 1);
}
for(String word: words)
bst.contains(word);
long endTime = System.nanoTime();
double time = (endTime - startTime) / 1000000000.0;
System.out.println("BST: " + time + " s");
// Test AVL Tree
startTime = System.nanoTime();
AVLTree<String, Integer> avl = new AVLTree<>();
for (String word : words) {
if (avl.contains(word))
avl.set(word, avl.get(word) + 1);
else
avl.add(word, 1);
}
for(String word: words)
avl.contains(word);
endTime = System.nanoTime();
time = (endTime - startTime) / 1000000000.0;
System.out.println("AVL: " + time + " s");
}
System.out.println();
}
}
运行结果:
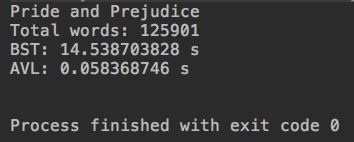
可以在排过序的极端情况下,AVL 比BST退化成的链表性能优秀了太多太多。
// Collections.sort(words);
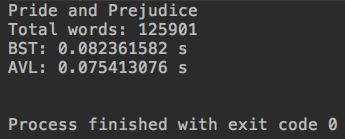
如果是没有排序的正常情况,AVL比BST只是略高,两者处于同一水准。
AVL树中删除元素维护自平衡
添加新节点,回溯向上更新父辈平衡因子,导致不平衡。对于AVL的删除,删除的子树根节点出发。
private Node remove(Node node, K key){
if( node == null )
return null;
Node retNode;
if( key.compareTo(node.key) < 0 ){
node.left = remove(node.left , key);
// return node;
retNode = node;
}
else if(key.compareTo(node.key) > 0 ){
node.right = remove(node.right, key);
// return node;
retNode = node;
}
else{ // key.compareTo(node.key) == 0
// 待删除节点左子树为空的情况
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
// return rightNode;
retNode = rightNode;
}
// 待删除节点右子树为空的情况
else if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
// return leftNode;
retNode = leftNode;
}
// 待删除节点左右子树均不为空的情况
else{
// 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点的位置
Node successor = minimum(node.right);
//successor.right = removeMin(node.right);
successor.right = remove(node.right, successor.key);
successor.left = node.left;
node.left = node.right = null;
// return successor;
retNode = successor;
}
}
if(retNode == null)
return null;
// 更新height
retNode.height = 1 + Math.max(getHeight(retNode.left), getHeight(retNode.right));
// 计算平衡因子
int balanceFactor = getBalanceFactor(retNode);
// 平衡维护
// LL
if (balanceFactor > 1 && getBalanceFactor(retNode.left) >= 0)
return rightRotate(retNode);
// RR
if (balanceFactor < -1 && getBalanceFactor(retNode.right) <= 0)
return leftRotate(retNode);
// LR
if (balanceFactor > 1 && getBalanceFactor(retNode.left) < 0) {
retNode.left = leftRotate(retNode.left);
return rightRotate(retNode);
}
// RL
if (balanceFactor < -1 && getBalanceFactor(retNode.right) > 0) {
retNode.right = rightRotate(retNode.right);
return leftRotate(retNode);
}
return retNode;
}
for(String word: words){
map.remove(word);
if(!map.isBST() || !map.isBalanced())
throw new RuntimeException();
}
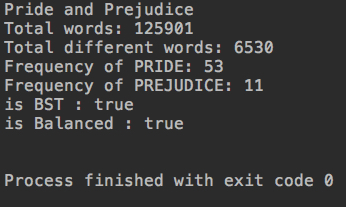
并没有抛出异常。
更多AVL树的相关问题
基于AVL树的set和map。
package cn.mtianyan.map;
import cn.mtianyan.AVLTree;
public class AVLMap<K extends Comparable<K>, V> implements Map<K, V> {
private AVLTree<K, V> avl;
public AVLMap(){
avl = new AVLTree<>();
}
@Override
public int getSize(){
return avl.getSize();
}
@Override
public boolean isEmpty(){
return avl.isEmpty();
}
@Override
public void add(K key, V value){
avl.add(key, value);
}
@Override
public boolean contains(K key){
return avl.contains(key);
}
@Override
public V get(K key){
return avl.get(key);
}
@Override
public void set(K key, V newValue){
avl.set(key, newValue);
}
@Override
public V remove(K key){
return avl.remove(key);
}
}
AVLMap<String, Integer> avlMap = new AVLMap<>();
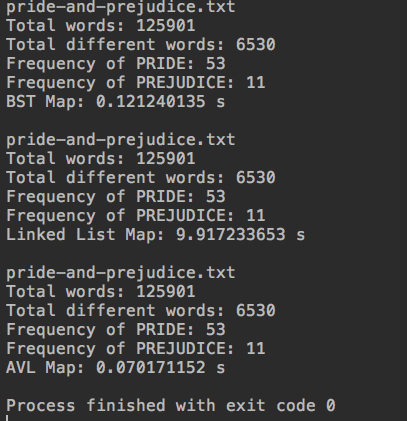
double time3 = testMap(avlMap, filename);
System.out.println("AVL Map: " + time3 + " s");
运行结果:
此处暂时略去使用一个AVL树包装一个集合。
AVL树的优化: 更新后高度相等,不用维护平衡。
AVL树的局限性: 平均性能红黑树更快。就像平均来讲快速排序是比归并排序更快的,两者都是O(logn).红黑树旋转次数更少,因此理论性能更好。
下一章我们将开始介绍红黑树。














 52
52











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









