






我了解的不够深入,但是你这个测试代码不能反应问题,我自己试了一下
import 的逻辑据我所知是这样的
如果当前引入的包已经被引入过了,那么不会重新引入,而是将其地址复制到当前作用域当中
py2的简单测试
In [1]: import time
In [2]: id(time)
Out[2]: 46466960
In [3]: def impt():
...: import time as t
...: print id(t)
...:
In [4]: impt()
46466960
逆序再来一次
In [1]: def impt():
...: import time as t
...: print id(t)
...:
In [2]: impt()
7866256
In [3]: import time
In [4]: id(time)
Out[4]: 7866256
可以看到,哪怕是在函数内部作用域先进行import,再在外部import,结果还是一样没有进行重复引入.
写成循环重复调用impt,得到的结果也是一样,每次打印的都是同一个内存地址.
然后我们试一下跨文件:
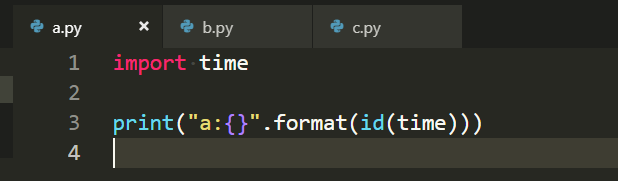
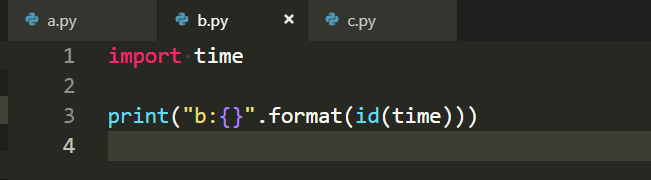
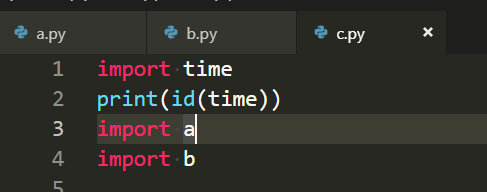
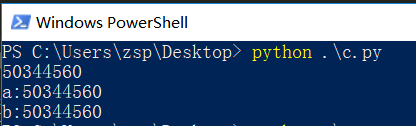
贴图片了,可以看到不同文件没什么影响.
通过这个测试我认为,import操作相当于将包引入到解释器当中,下次引入第一步是检查而不是重新引入,这在python交互模式的时候也可以感受到,比如numpy这样大一些的包,第一次引入的时候有一个可以感受到的延迟,再次引入就没有了,因为这次检测到这个包已经存在于这里了,只需要复制内存地址就可以了.
复制地址这个操作还是需要一点时间的,在循环里会有一点点点点点性能损失.
放在文件头位置相当于初始化时加载,放在函数内部可以做到懒加载...
以上















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









