







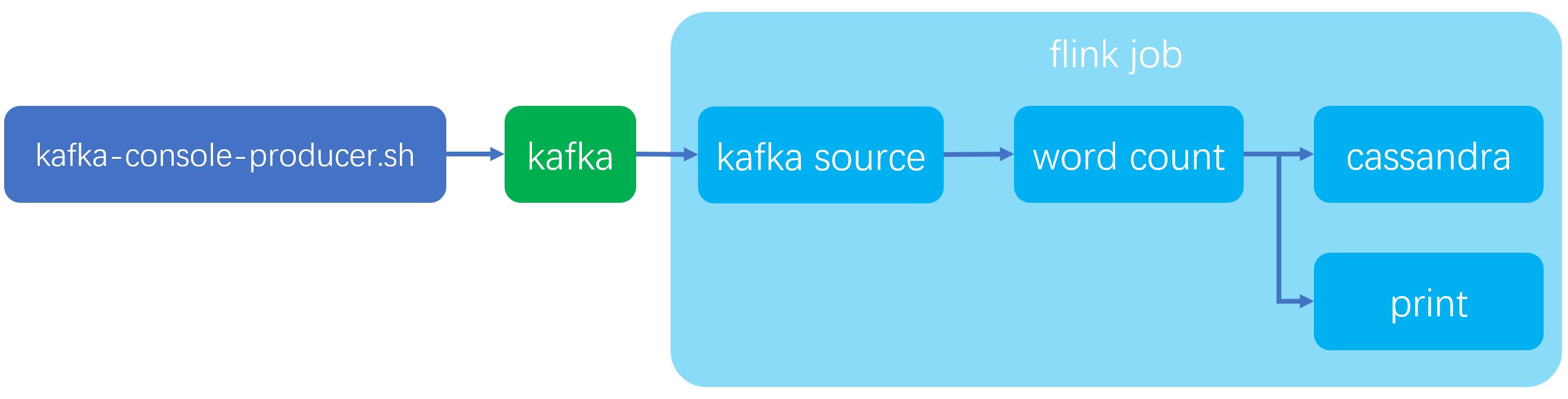
本文是《Flink的sink实战》系列的第三篇,主要内容是体验Flink官方的cassandra connector,整个实战如下图所示,我们先从kafka获取字符串,再执行wordcount操作,然后将结果同时打印和写入cassandra:
前文链接
- 《Flink的sink实战之一:初探》
- 《Flink的sink实战之二:kafka》
软件版本
本次实战的软件版本信息如下:
- cassandra:3.11.6
- kafka:2.4.0(scala:2.12)
- jdk:1.8.0_191
- flink:1.9.2
- maven:3.6.0
- flink所在操作系统:CentOS Linux release 7.7.1908
- cassandra所在操作系统:CentOS Linux release 7.7.1908
- IDEA:2018.3.5 (Ultimate Edition)
关于cassandra
本次用到的cassandra是三台集群部署的集群,如果您想快速部署集群可以参考《ansible快速部署cassandra3集群》
准备cassandra的keyspace和表
先创建keyspace和table:
- cqlsh登录cassandra:
cqlsh 192.168.133.168- 创建keyspace(3副本):
CREATE KEYSPACE IF NOT EXISTS example WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3'};- 建表:
CREATE TABLE IF NOT EXISTS example.wordcount ( word text, count bigint, PRIMARY KEY(word) );准备kafka的topic
- 启动kafka服务;
- 创建名为test001的topic,参考命令如下:
./kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 1 --topic test001- 进入发送消息的会话模式,参考命令如下:
./kafka-console-producer.sh --broker-list kafka:9092 --topic test001- 在会话模式下,输入任意字符串然后回车,都会将字符串消息发送到broker;
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):

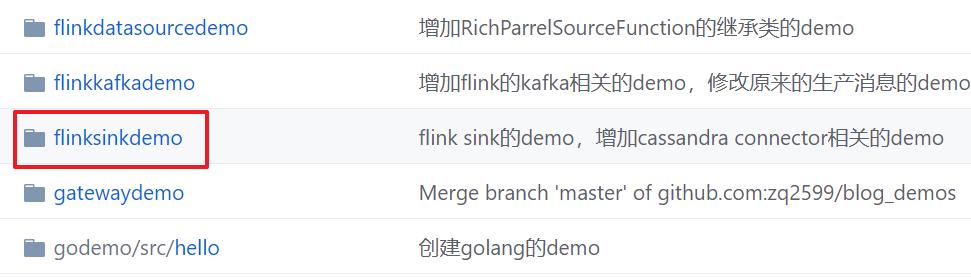
这个git项目中有多个文件夹,本章的应用在flinksinkdemo文件夹下,如下图红框所示:
两种写入cassandra的方式
flink官方的connector支持两种方式写入cassandra:
- Tuple类型写入:将Tuple对象的字段对齐到指定的SQL的参数中;
- POJO类型写入:通过DataStax,将POJO对象对应到注解配置的表和字段中&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









