







本文大部分转至:http://blog.csdn.net/skywalker_only/article/details/27547515
Hive到0.13.0版本为止已经支持越来越多的数据类型,像传统数据库中的VCHAR、CHAR、DATE以及所特有的复合类型MAP、STRUCT等。hive中的数据类型可以分为数值类型、字符串类型、日期时间类型、复合类型以及其它类型,下面分别予以介绍。
数值类型
Hive中的数值类型与Java中的数值类型很相似,区别在于有些类型的名称不一样,可以概括为如下的表格: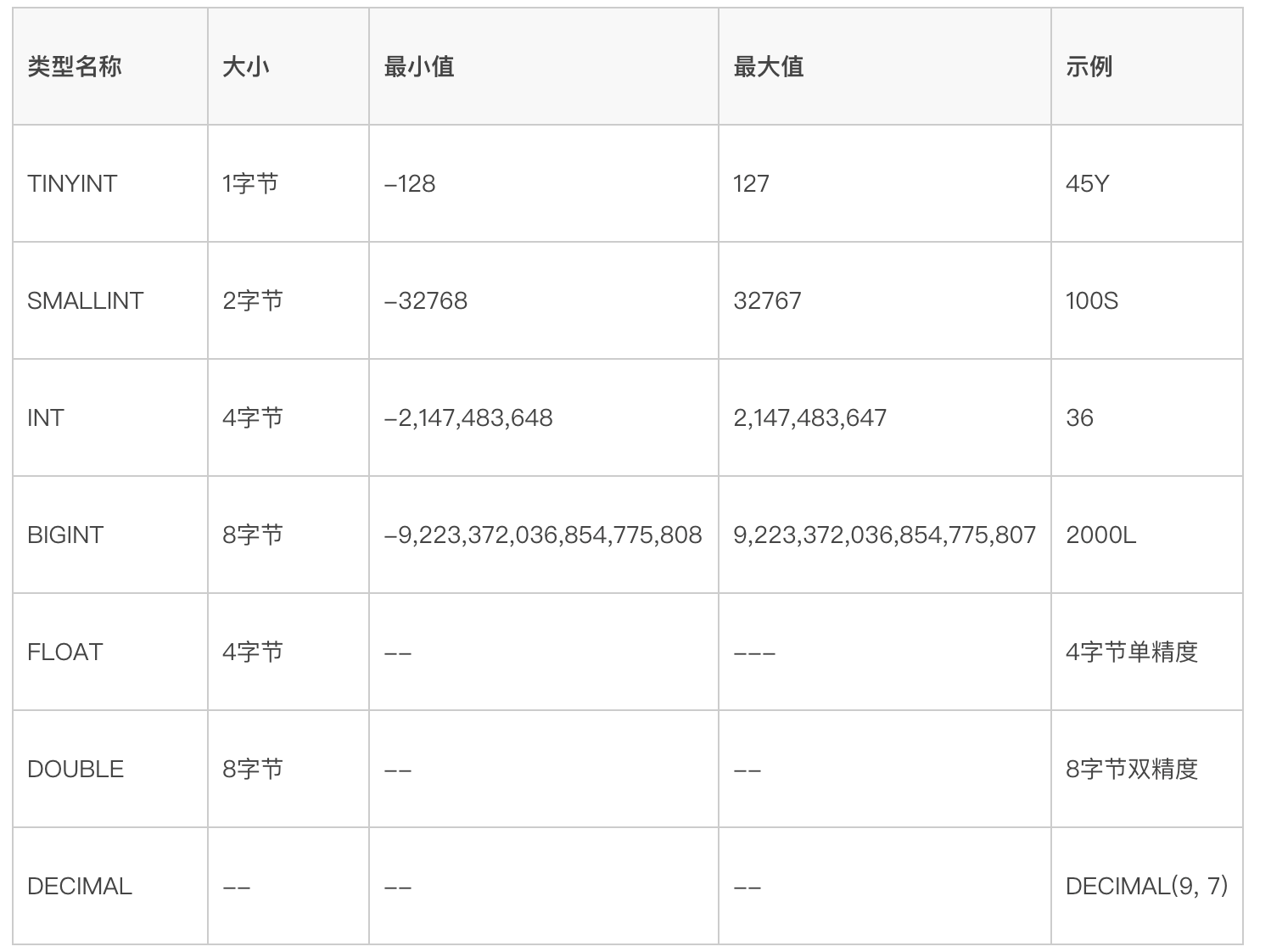
默认情况下,整数常量被当做INT处理,除非整数常量超出了INT类型的取值范围或者在整数常量跟着Y、S、L等后缀,则常量将会作为TINYINT、SMALLINT和BIGINT处理。Hive中的浮点数常量默认被当做DOUBLE类型。
DECIMAL类型是在Hive-0.11.0版本中引入的,在Hive-0.13.0版本中做了改进。Hive中的DECIMAL基于Java中的BigDecimal,BigDecimal用于表示任意精度的不可修改的十进制数字。所有常规数字操作符(如+、-、*、/)和相关的UDFs(如Floor、Ceil、Round等)用于处理DECIMAL类型,可以转换DECIMAL为其它数值类型或者将其它基本类型转换为DECIMAL。DECIMAL类型支持科学计数法,所以不管数据集中是否包含1E+44或者4000或者二者的组合,都可以使用DECIMAL表示。Hive-0.11.0和Hive-0.12.0固定了DECIMAL类型的精度并限制为38位数字,从Hive-0.13.0开始可以指定DECIMAL的规模和精度,当使用DECIMAL类型创建表时可以使用DECIMAL(precision,scale)语法。例如:
create table decimal_test (d decimal); 可以使用LazySimpleSerDe和LazyBinarySerDe读写包含DECIMAL类型的表,如:
alter table decimal_1 set serde 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe';
alter table decimal_1 set serde 'org.apache.hadoop.hive.serde2.lazy.LazyBinarySerDe'; 可以使用cast在DECIMAL和其它基本类型,如INT、DOUBLE、BOOLEAN之间转换,如:
Select cast(d asboolean) from decimal_test; DECIMAL类型比DOUBLE类型为浮点数提供了精确的数值和更广的范围,DECIMAL类型存储了数值的精确地表示,而DOUBLE类型存储了非常接近数值的近似值。当DOUBLE类型的近似值精度不够时可以使用DECIMAL类型,比如金融应用,等于和不等于检查以及舍入操作,当数值超出了DOUBLE类型的范围(大约-10308 to 10308)或者非常接近于0(-10-308 to 10-308)时,也可以使用DECIMAL类型。
字符串类型
字符串常量使用单引号或者双引号表示,Hive使用C语言风格对字符串进行转义。Hive-0.12.0版本引入了VARCHAR类型,VARCHAR类型使用长度指示器(1到65355)创建,长度指示器定义了在字符串中允许的最大字符数量。如果一个字符串值转换为或者被赋予一个varchar值,其长度超过了长度指示器则该字符串值会自动被截断。目前还没有通用的UDF可以直接用于VARCHAR类型,可以使用String UDF代替,VARCHAR将会转换为String再传递给UDF。Hive-0.13.0版本引入了CHAR类型,CHAR类型与VARCHAR类型相似,但拥有固定的长度,也就是如果字符串长度小于指示器的长度则使用空格填充。CHAR类型的最大长度为255。使用VARCHAR、CHAR创建表的例子如下:
CREATE TABLE test(c CHAR(10), vc VARCHAR(30)); 日期/时间类型
Hive支持带可选的纳秒级精度的UNIX timestamp。Hive中的timestamp与时区无关,存储为UNIX纪元的偏移量。Hive提供了用于timestamp和时区相互转换的便利UDF:
to_utc_timestamp和 from_utc_timestamp。
Timestamp类型可以使用所有的日期时间UDF,如month、day、year等。文本文件中的Timestamp必须使用yyyy-mm-dd hh:mm:ss[.f...]的格式,如果使用其它格式,将它们声明为合适的类型(INT、FLOAT、STRING等)并使用UDF将它们转换为Timestamp。Timestamp支持的类型转换为:
1.整数类型:转换为秒级的UNIX时间戳。
2.浮点数类型:转换为带小数精度的UNIX时间戳。
3.字符串类型:适合java.sql.Timestamp格式"YYYY-MM-DD HH:MM:SS.fffffffff"(9位小数精度)。
Hive中DATE类型的值描述了特定的年月日,以YYYY-MM-DD格式表示,例如2014-05-29。DATE类型不包含时间,所表示日期的范围为0000-01-01 to 9999-12-31。DATE类型仅可与DATE、TIMESTAMP、STRING类型相互转化,如下表所示:
| 类型转换 | 结果 |
| cast(date as date) | 相同的日期。 |
| cast(timestamp as date) | 基于本地时区确定timestamp的年月日作为值返回。 |
| cast(string as date) | 如果字符串的格式为'YYYY-MM-DD', 则对应的年月日返回。如果字符串不是该格式, 则返回NULL。 |
| cast(date as timestamp) | 基于本地时区,返回日期对应午夜时间。 |
| cast(date as string) | 日期被转换为'YYYY-MM-DD'格式的字符串。 |
实际操作:
create table bi.Etest01
( a Date,
b string,
c timestamp
)
row format delimited
fields terminated by ','
;在往这个被创建的表中insert 日期类型的数据时,发现,a只能接收'yyyy-mm-dd'类型的值,否则为NULL,
b可以接收任意类型的值,c只能接收'yyyy-mm-dd hh:mm:ss....'类型的值,否则为NULL.
复杂数据类型
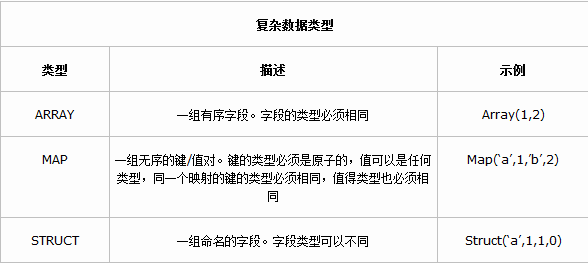
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而STRUCT 与 C语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
复杂数据类型的声明必须使用尖括号指明其中数据字段的类型。定义三列,每列对应一种复杂的数据类型,如下所示。
CREATE TABLE complex(
col1 ARRAY< INT>,
col2 MAP< STRING,INT>,
col3 STRUCT< a:STRING,b:INT,c:DOUBLE>
)Structs: Structs内部的数据可以通过逗号(.)来存取,例如,表中某列a1的类型为Struct{b int; c int},我们可以通过a1.b来访问域b;
Map(K-V对):访问指定域可以通过{"指定域名称"}进行,例如,一个Map A包含了一个group->gid的KV对,gid的值可以通过A['group']来获取;
Arrays:array的数据为相同类型,例如,假如array A 中元素['a','b','c'],则A[1]的值为'b';
类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型, 但是 Hive 不会进行反向转化,例如,某表达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
隐式类型转换规则如下:
1、任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT,INT 可以转换成 BIGINT。
2、所有整数类型、FLOAT 和 String 类型都可以隐式地转换成 DOUBLE。
3、TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
4、BOOLEAN 类型不可以转换为任何其它的类型。可以使用 CAST 操作显示进行数据类型转换,例如 CAST(‘1’ AS INT) 将把字符串’1’ 转换成整数 1;如果强制类型转换失败,如执行 CAST(‘X’ AS INT),表达式返回空值 NULL。















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









