







倘若不断的向数据库的某个表插入数据,那么这个表的记录会越来越多,当这个表的记录总数达到某个值时,要对这个很大的表做查询操作,会随着记录总数不断的增大,查询的时间呈现数量级增多,为了解决这个问题,我们对数据量比较大的表进行转储操作。
转储操作的思路如下:
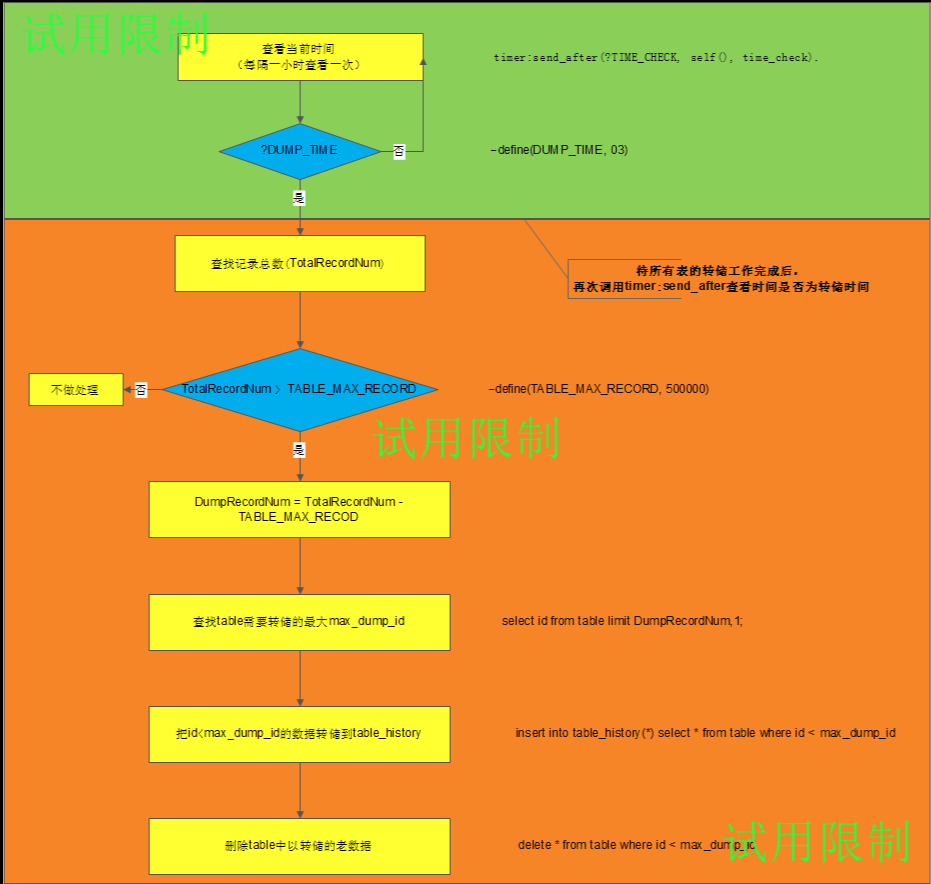
数据的转储工作在夜间进行,由于没有找到erlang里面某个函数可以定时到某个时间调用处理函数,所以就采用了timer:send_after()隔一个小时去查看一下当前时间是几点,若到了转储的时间就对需要转储的table进行转储,当转储操作完成后,再次调用timer:send_after()来查看时间。
大致的代码如下:
%%%=========================================================================
%%% File : mysql_dump_task.erl
%%% Author : lvhuizhen
%%% Description : if the mysql table record number is bigger than the
%%% limit value, we will dump some old data to history table.
%%% Created : 2016/3/16
%%%==========================================================================
-module(mysql_dump_task).
-behaviour(gen_server).
-export([init/1,
terminate/2,
code_change/3,
handle_call/3,
handle_cast/2,
handle_info/2]).
-export([start_link/0]).
%%
-define(TIME_CHECK, 60*60*1000).
-define(DUMP_TIME, 3).
%%
-define(MAX_SERVER_WARNING_REPAIRED, 500000).
-record(state,{}).
%%--------------------------------------------------------------------------
%% API
%%--------------------------------------------------------------------------
start_link() ->
gen_server:start_link(?MODULE, [], []).
init([]) ->
lager:info("[mysql_record_dump Task] Start init!~n"),
lager:info("[mysql_record_dump Task]timer: ~p~n", [calendar:now_to_local_time(erlang:now())]),
timer:send_after(60*1000 self(), time_check),
{ok, #state{}}.
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Request, _From, State) ->
Reply = ok,
{reply, Reply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info( time_check, State ) ->
time_check(),
{noreply, State};
handle_info(_Info, State) ->
{noreply, State}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
time_check() ->
lager:info("[mysql_record_dump]timer: ~p~n", [calendar:now_to_local_time(erlang:now())]),
{{_,_,_},{Hour,_,_}} = calendar:now_to_local_time(erlang:now()),
case Hour of
?DUMP_TIME ->
lager:info("[mysql_record_dump Task] Hour is: ~p~n", [Hour]),
server_warning_repaired_dump(),
terminal_warning_repaired_dump(),
timer:send_after(?TIME_CHECK, self(), time_check);
_ ->
timer:send_after(?TIME_CHECK, self(), time_check)
end.
server_warning_repaired_dump() ->
lager:info("[mysql_dump_task] server_warning_repaired_dump ~n"),
{ok, RecordNum} = gen_server:call(mysql_task,{get_table_record_num, "server_warning_repaired"}, infinity),
lager:info("[mysql_dump_task] server_warning_repaired table RecordNum is ~p~n", [RecordNum]),
if RecordNum > ?MAX_SERVER_WARNING_REPAIRED ->
DumpRecordNum = RecordNum - ?MAX_SERVER_WARNING_REPAIRED,
lager:info("[mysql_dump_task] server_warning_repaired need dump record num : ~p~n", [DumpRecordNum]),
gen_server:cast(mysql_task,{dump_table_record, "server_warning_repaired", ?MAX_SERVER_WARNING_REPAIRED-1});
true ->
lager:warning("[mysql_dump_task] server_warning_repaired not need dump ~p~n")
end.
terminal_warning_repaired_dump() ->
lager:info("[mysql_dump_task] terminal_warning_repaired_dump ~n"),
{ok, RecordNum} = gen_server:call(mysql_task,{get_table_record_num, "terminal_warning_repaired"}, infinity),
lager:info("[mysql_dump_task] terminal_warning_repaired table RecordNum is ~p~n", [RecordNum]),
if RecordNum > ?MAX_SERVER_WARNING_REPAIRED ->
DumpRecordNum = RecordNum - ?MAX_SERVER_WARNING_REPAIRED,
lager:warning("[mysql_dump_task] terminal_warning_repaired need dump record num : ~p~n", [DumpRecordNum]),
gen_server:cast(mysql_task,{dump_table_record, "terminal_warning_repaired", ?MAX_SERVER_WARNING_REPAIRED-1});
true ->
lager:warning("[mysql_dump_task] terminal_warning_repaired not need dump ~p~n")
end.经测试:当需要转储的数据量比较大,而且索引比较多的时候,会发现转储的时间比较久,大概需要几分钟。
但是,但是一个表中创建很多不合理的索引,是不合理的行为。所以不是索引越多越好,索引比较多时,会加重插入,删除,更新的负担。
创建在warning_repaired表上创建了两个索引,转储大概50万的数据量,发现转储的时间为1分钟左右。
转储代码如下:
-spec dump_table_record(atom(), string(), integer()) ->{ok, success}|{error,string()}.
dump_table_record(PoolId, Table, DumpRecordNum) ->
DumpMaxIdSQL = "SELECT id From " ++ Table ++ " ORDER BY id DESC limit " ++ integer_to_list(DumpRecordNum) ++ ",1;",
lager:info("[table_record_dump_handler]The SQL is : ~p~n", [DumpMaxIdSQL]),
{result_packet, _, _, DumpMaxId, _} = emysql:execute(PoolId, list_to_binary(DumpMaxIdSQL)),
lager:info("[table_record_dump_handler] The DumpMaxId Result is : ~p~n", [DumpMaxId]),
case DumpMaxId of
[] ->
{error, "not get dump max id"};
[[undefined]] ->
{error, "not get dump max id"};
[[DumpMaxIdValue]] ->
INSERTSQL = "INSERT INTO " ++ Table ++"_history" ++ " SELECT * FROM " ++ Table
++ " WHERE id <" ++ integer_to_list(DumpMaxIdValue) ++ ";",
DELECTSQL = "DELETE FROM " ++ Table ++ " WHERE id < " ++ integer_to_list(DumpMaxIdValue) ++ ";",
SQL = "BEGIN;" ++ INSERTSQL ++ DELECTSQL ++ "COMMIT;",
Result = emysql:execute(PoolId,list_to_binary(SQL)),
lager:info("The SQL is : ~p~n", [SQL]),
lager:info("The Result is : ~p~n",[Result]),
%% [{ok_packet,1,0,0,11,0,[]},
%% {ok_packet,2,9,18,11,0,
%% "&Records: 9 Duplicates: 0 Warnings: 0"},
%% {ok_packet,3,9,0,11,0,[]},
%% {ok_packet,4,0,0,2,0,[]}]
case Result of
[{ok_packet,_,_,_,_,_,_},{ok_packet,_,_,_,_,_,_},{ok_packet,_,_,_,_,_,_},{ok_packet,_,_,_,_,_,_}] ->
{ok,success};
_ ->
{error,"dump faild!"}
end
end.下面是测试14点时,一张70万的表中转储20万的数据的打印日志,server_warning_repaired表中创建了两个索引。
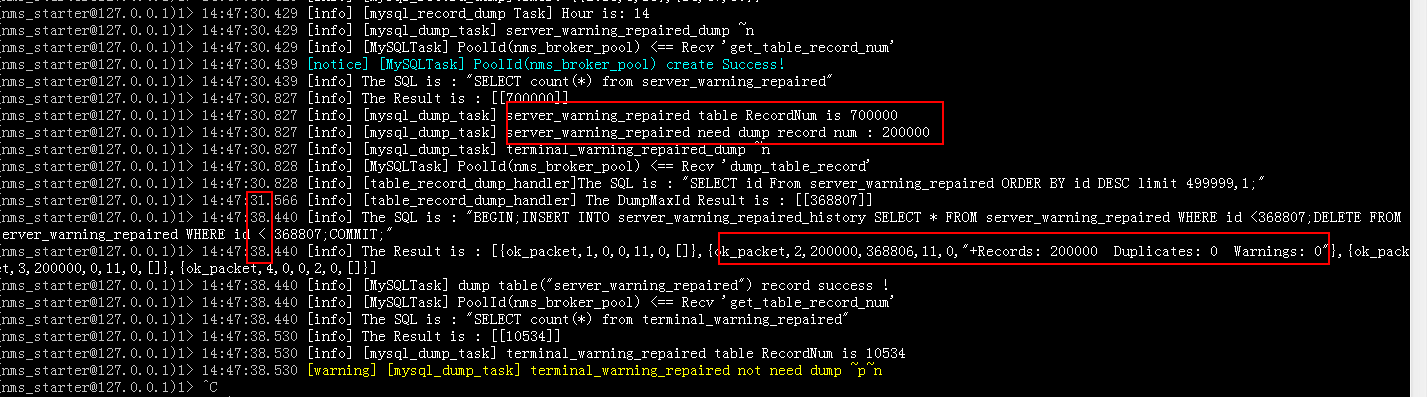
可以看出大约花费了6s的时间,这个时间还是可以忍受的。















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









