







中文乱码一直是程序处理中不可避免的问题,既然绕不过就想办法解决它!
通俗逻辑:
- 源文件编码格式,'ascii,utf-8,gbk';
- python读取格式设置,encoding=‘utf-8’;
- 在程序处理中通过encode(‘utf-8’),decode(‘utf-8’),或者u''.join();
- 文件输出(txt,excel,csv等)编码设置;
当然,我们还会用到,# -*-coding:utf-8 -*- 在第一,二行进行标识。
但是我们还是会遇到问题,比如说,中文输出时遇到乱码(一万个那啥啊.......)没办法,只能找解决办法。
- 遇到问题:
- 读取txt,经过处理,输出csv,csv遇到乱码。
- 解决办法:
df.to_csv("data.csv",encoding="utf_8_sig") # 直接利用"utf_8_sig",才能在excel中显示中文
- 解决思路:见下表
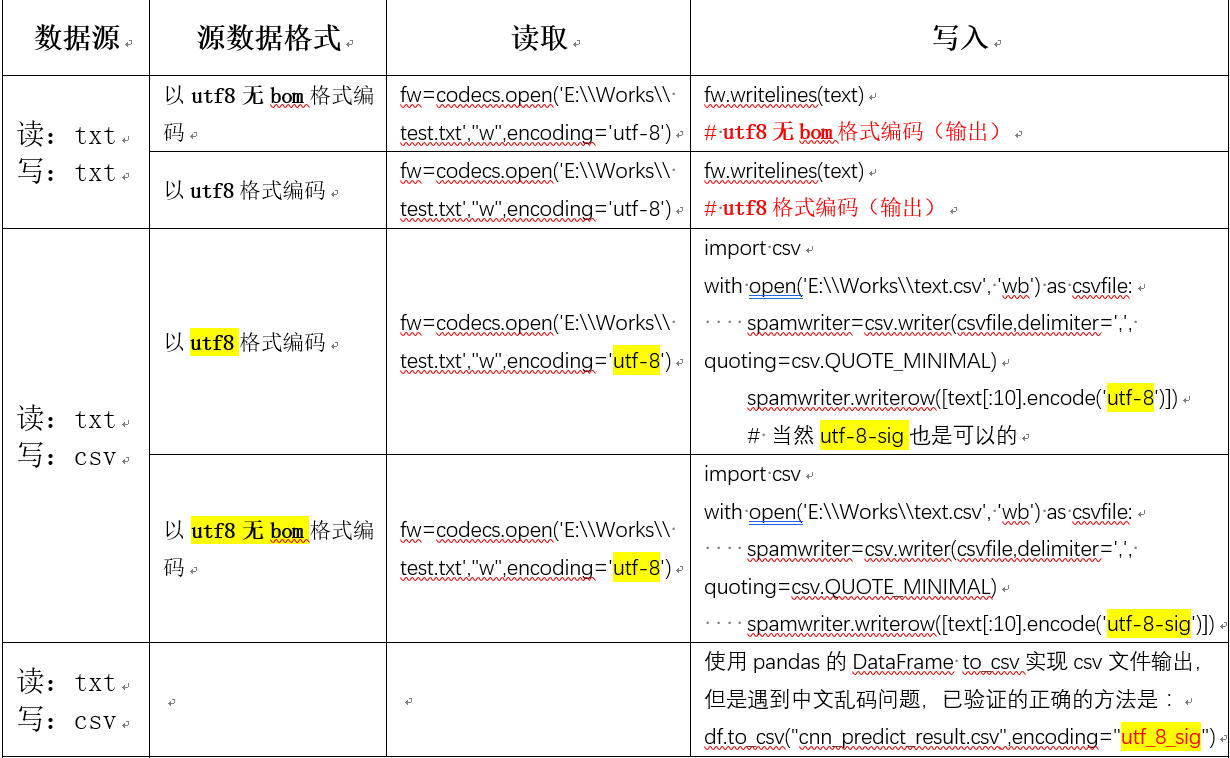


- 总结:
0. 开源的编辑器实在是恶心的要死
- 考虑到很多时候我们需要对数据处理结果进行进一步操作,统一起见,应该将整个过程用utf-8进行规范化
- 总的来说:就中文处理来说。
- 原始数据txt尽量使用无bom格式进行存储。
- Excel数据输出时候,编码格式用GBK或UTF-8-SIG















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









