







kafka启动后,再接收到消息后,会将数据,写在log.Dirs路径下的目录内。
日志文件由两部分组成:
00000000000000000000.index 索引文件
00000000000000000000.log 内容文件
当log内容文件大小够1G的时候,会进行切分,产生第二个index和log文件,且第一个内容文件的命名以offset值来部分命名:
000000000000077894.index
000000000000077894.log
在kafka的设计中,将offset值作为了文件名的一部分。
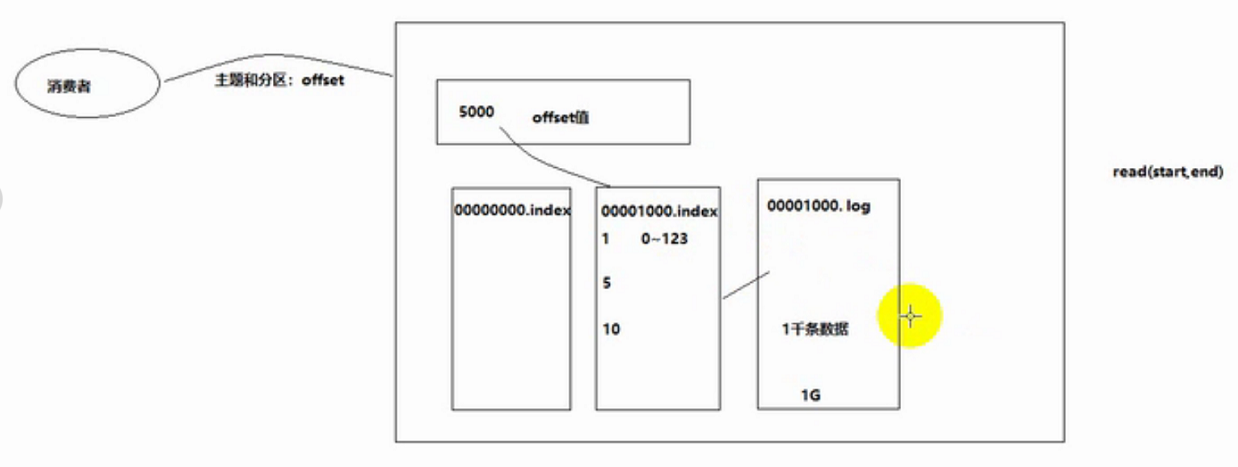
如上图,当通过offset查找一条数据时,index文件存着log内容的索引,且每一条索引有自己的作用范围,这样有个好处就是查找某条数据时,可以很快速的找到索引,再由索引去找到数据,而不用遍历所有数据。缺点是要保证index和log文件,都正常写入。
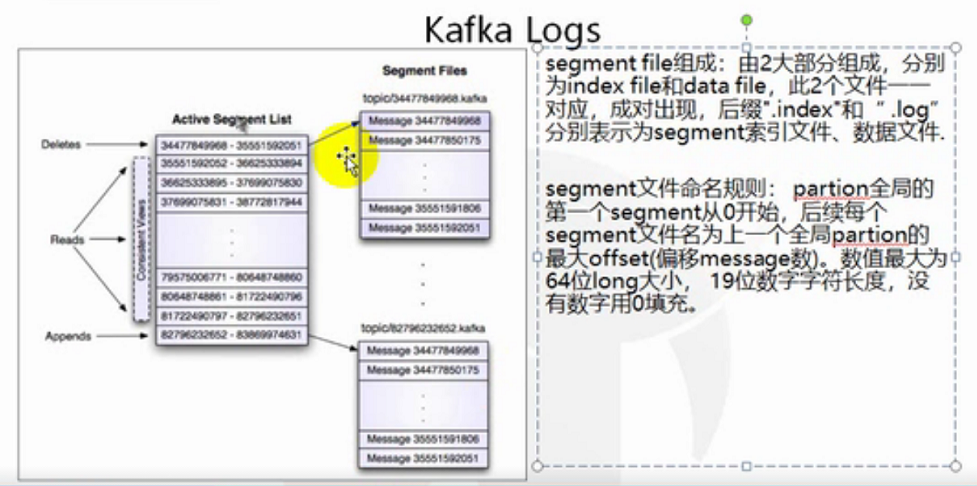
我们将一组文件 index和log称之为segment file,分别表示为segment索引文件和内容文件。
而且有一个active segment list 这么一个东西,它维护所有的segment文件,当有生产者添加消息或者消费者消费消息时,可以通过active segment list和offset,迅速找到分区的segment文件,进行读写。
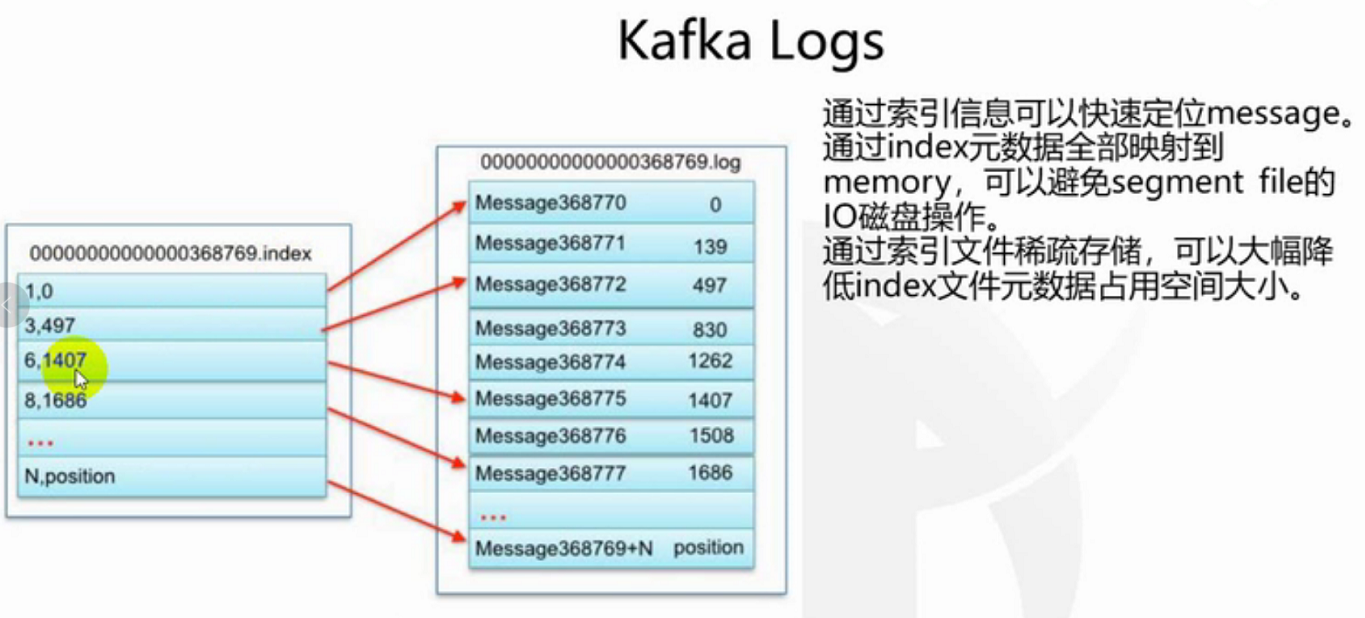
稀疏索引:我们需要为数据创建索引,但范围不是为每一条创建索引,而是为某一个区间创建。
好处是减少索引值数量。
缺点是找到索引区间之后,还得进行第二次处理。

crc32,当消息发送过来时,crc32根据消息内容生成一串数字,过段时间,如果消息内容发生变化,比如被杀毒软件杀掉了,导致内容损坏了,不完整了,crc32就会变化,所以校验crc32可以防止脏数据。

因为数据是存储在磁盘上的,不处理会造成磁盘不足的现象。
kafka对日志文件的清理方式:delete和compact,删除操作的阈值有两种:过期的时间(默认7天,公司可以设置的更长一些)和分区内日志文件字节的大小。
如果在server.properties文件中设置,将在没有特殊指定参数的topic中,所有topic都生效。
如果是在topic的配置中加入,那只对该topic有效。 创建topic时,追加--config参数,设置删除条件。
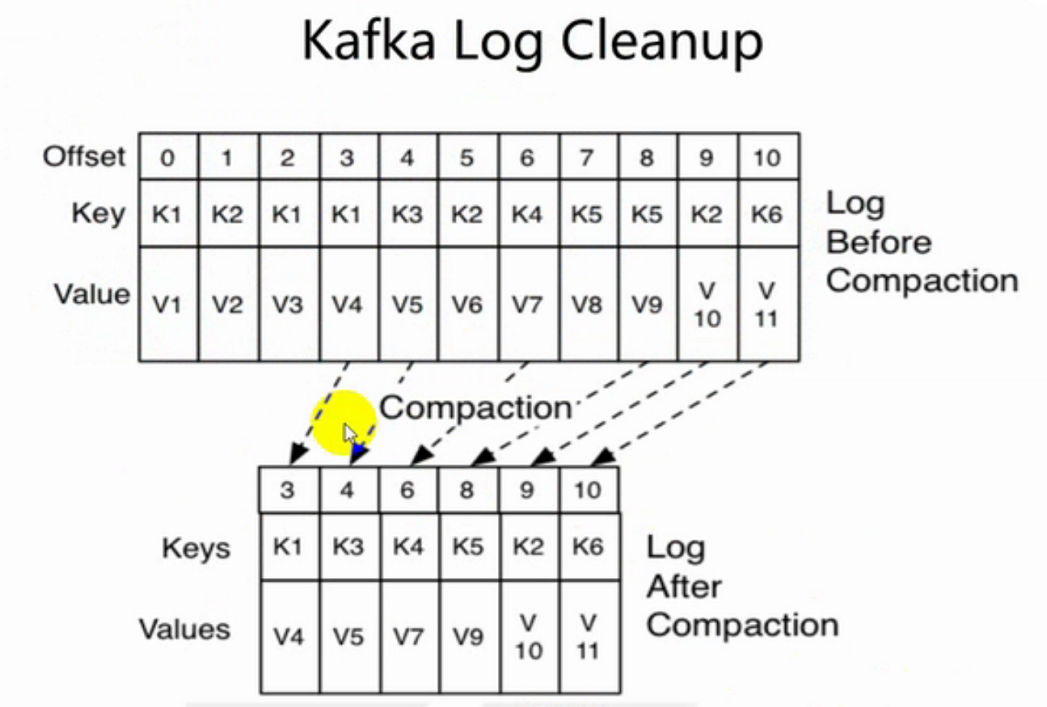
合并策略:当多条数据的key相同,我们只保留offset值最大的消息记录。既当消息的key一样时,只保留最新的消息记录。















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









