







文档和域(document、filed)
- 索引过程,将原始数据转换成Lucene能识别的 document和filed
- 搜索过程,被搜索对象为域值
Lucene 索引过程
- 分析过程,将域文本处理成大量语汇单元
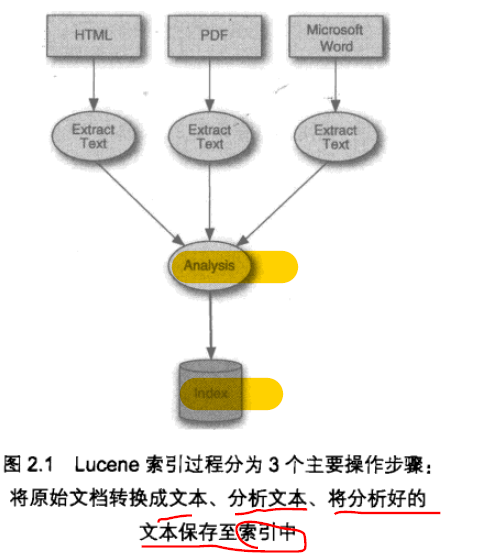
- 提取文本、创建文档
- 分析文档
- 分析文本,先将其转换成语汇单元串
- 也包括一系列可选操作:比如去除无意义词语,改变词语的状态等
- IndexWriter 的 addDocument
- 分析文本,先将其转换成语汇单元串
- 向索引添加文档
- 倒排索引存储结构,有效利用磁盘空间
- 将语汇单元作为查询关键字,而不是整个文档
- 索引段
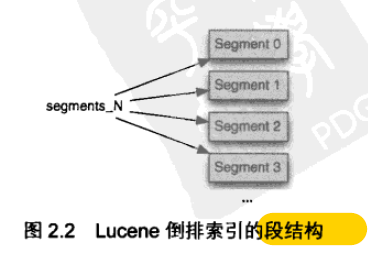
- Lucene 索引都包含一个或多个段
- 每个段都是独立索引
- 是整个文档索引的子集
- 每当write刷新缓存区增加的文档、挂起目录、删除操作,都会新增加一个段
- 搜索索引时,每个段独立访问,结果合并返回
- 每个段包含多个文件
- 格式为 _x.<ext>
- .<ext>为扩展名,表示对应的索引的某个部分
- 压缩成单一文件:_X.cfs
- 特殊文件:段文件 _<N>
- 指向所有激活的段
- Lucene 先打开它,再去打开他指向的段
- <N> 代表整数,修改一次索引 加1
- 段集聚太多
- 周期性合并一些段成新的段(然后删掉老的多个段)
基本索引操作
- 向索引中添加文档
- 删除索引文档


- 优化删除,强制合并索引段
- 更新索引文档
- Lucene无法做到更新操作
- 只能删除整个文档,再向索引中添加新文档


域选项
- Filed 类是索引其间很重要的类
- 控制着被索引的域值
- 域选项 包括:域索引选项、域存储选项、域项向量选项
- 域索引选项
- 域存储选项
- 域项向量选项
- 是否进行向向量计算
- 计算匹配度
- 是否进行向向量计算


- 域选项组合
- 域排序选项
- 多值域
- 一个域包括多个值(比如多个作者)




对文档和域进行加权
- 加权可以在索引其间完成
- 也可以在搜索其间完成
- 搜索阶段加权更加动态,更消耗CPU
- 比如:可以询问用户是否对最近修改过的文档进行加权
- 加权要小心
- 特别是未通知用户的加权,会使得结果变得很诡异
- 文档加权
- 默认所有文档的加权因子都是 1.0
- setBoost(float )
- 域加权操作
- 加权文档会,对所有的域进行加权
- 也可以单独对某个域加权
- 较短的域有隐含加权,这是Lucene 评分算法有关(之前博客已经提到过)
- 加权因子可能需要实验获得而最佳值
- 注意,改变 加权因子,需要删除文档在添加
- 当然 update 方法也有同样效果
- 高级操作,使用时要小心
- Lucene 评分机制包含大量因子,加权因子仅仅是其中一个
- 注意,改变 加权因子,需要删除文档在添加
- 加权基准(Norms)
- 索引期间,文档域的锁有加权被合并成一个浮点数
- setNorm 是高级方法,需要程序自己计算自己的 Norms
- 经常面临搜索其间高内存
- 索引一半,关闭norms ,仍然需要重建索引
- 段合并会导致norms扩散
索引数字
- 一种是:数字包含在将要索引的文本中
- 需要将其作为单独的语汇单元处理
- 选择不丢弃数字的分析器即可
- 另一种场景:一些域仅仅包含数字
- 数字域值进行索引:支持精确匹配、范围搜索、数字排序
- NumericFiled
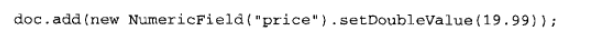
- 每个数字索引用特里结构索引
- Trie(特里结构,字典树)
- 只接受单一数值
- 多数值可能导致排序不确定
- 高级参数:precisionStep
- 控制间隙,间隙越小,特里括号越多,会增大索引尺寸
- 索引日期和时间
- 转换成数字
- 转换成数字

域截取
- 索引时需要限制需要索引的文档
- 比如二进制文档(比如很大的视频),错误分类
- 比如有时仅仅需要对部分文档进行索引
- setMaxFiledLength
- 谨慎使用,可能会导致有的东西找不到
近实时搜索
- Lucene重要功能(实时搜索)
- 及时索引,及时搜索

- 该方法实时刷新缓存区,新增或删除文档
- indexWriter 马上刷新缓存,不等内存满了在刷新
优化索引
- 就是将多个段合并成一个或少量段
- 提高搜索速度,不是索引速度
- IndexWriter 4个索引优化方法
- 消耗大量CPU和I/O资源
- 是一次性大量系统开销换取搜索速度变快
- 如果优化伴随大量搜索请求,权衡使用优化
- 由于旧段在commit 前 不会被删除
- 所以 要预留大约三倍的磁盘空间
- 优化后,占用磁盘空前会比优化之前少

FSDirectory 的几个子类::


- 所有子类写操作都共享代码
- FSDirectory.open 会自动匹配调取子类
- RAMDirectory 读写都在内存
- 两个directory 之间 静态拷贝

- 盲目覆盖、没有锁机制
并发、安全和锁
- 线程安全和多虚拟机安全
- 远程文件系统访问索引
- 本机保存修改本地索引,其他机器通过远程文件系统搜索该索引
- 效果很差
- 最好的方法是把本地索引复制到各个计算机
- Solr 商业化搜索引擎,很好的支持该策略
- 本机保存修改本地索引,其他机器通过远程文件系统搜索该索引



索引锁机制
- Lucene 采用基于文件的锁
- 允许你修改锁实现方法:Directory.setLockFactory
- 将任何 LockFactory 的子类设置为自己的实现锁
- 通常不用担心程序在使用哪个锁
- 多台机器、多虚拟机才会用到自己实现的锁
- 以便轮流进行索引操作

调试索引:
- 输出调试信息到标准输出

高级索引概念
- IndexReader 删除文档
- Lucene 只允许 一个写操作
- IndexReader 删除文档时,需要关闭 IndexWriter
- 因此,程序交叉完成添加、删除会极大的影响吞吐
- 更好的办法是将添加和删除 批量交给IndexWriter
- IndexReader 删除文档时,需要关闭 IndexWriter
- 回收被删除文档所用过的磁盘空间
- bit 数组记录被删除索引文档(速度很快)
- 这些文档数据依然占用磁盘空间
- 段合并时才会回收
- optimize 会触发段合并,导致回收(合并所有段)
- expungeDeletes 会使被挂起删除操作相关文档合并段(合并相关文档,开销相对小,但也很大)
- 段合并时才会回收
- 缓冲和刷新
- 新文档添加到Lucene 索引或 挂起一个删除操作
- 这些操作首先被缓存到内存中
- 主要为了降低磁盘 IO
- 这些操作会以新段周期性的保存至Directory 中
- 这些操作首先被缓存到内存中
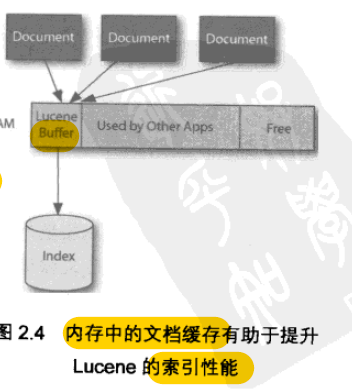
- IndexWriter 三种可能触发刷新


- 默认 RAM 缓存是16M
- 发生刷新时:
- writer 会在Directory 创建新段和被删除文件
- 这些文件对于新打开的IndexReader 不可见、不可用
- 直到writer commit、close
- 新打开的reader 才能看到
- 刷新是释放缓存的更改操作
- 提交是让更改在索引中可见
- writer 会在Directory 创建新段和被删除文件
- 新文档添加到Lucene 索引或 挂起一个删除操作
- 索引提交
- 调用 commit 方法之一会创建新的索引提交
- commit ()
- commit (Map<String,String>) 将提交的map 以元数据形式不透明提交
- 新打开的IndexReader、IndexSearch 只会看到上次提交后的索引
- 近实时搜索功能除外
- 该功能下,不用向磁盘提交即可搜索
- 近实时搜索功能除外
- 提交操作开销大,频繁降低索引吞吐量
- rollBack()
- 删除当前IndexWriter 上下文,在上一次提交前的所有更改操作
- 提交的步骤:

- 上次提交的旧索引文件,会到新提交完成后才删除
- 两次提交间距太长时间,消耗磁盘空间比 频繁提交更多
- 两阶段提交:
- Lucene 提供了 prepareCommit() 、prepareCommit(Map<String,String>)
- 这俩方法会完成上述的步骤1、2
- 大多数完成步骤3
- 但是不能使新的segment_N 对reader 可见
- prepareCommit 后,必须调用 rollback 或commit
- 此时,commit 执行的很快
- Lucene 提供了 prepareCommit() 、prepareCommit(Map<String,String>)
- 索引删除策略
- IndexDeletionPolicy
- 负责通知IndexWriter 何时删除旧的提交
- 默认策略是每次提交先删除旧的提交
- KeepOnlyLastCommitDeletionPolicy
- IndexDeletionPolicy
- 管理多个索引提交
- 回滚到很久以前版本
- Lucene 实现了事务
- 一次仅能打开一个事务


- 硬件崩溃,索引不会毁坏,回滚到上次提交
- 一些情况下,请禁止底层 I/O 的写缓存
- 调用 commit 方法之一会创建新的索引提交
- 合并段
- 带来的好处:
- 段合并策略
- 两种策略都是 LogMergePolicy 的子类
- LogByteSizeMergePolicy
- 根据该段包含所有文件的总字节数
- LogDocMergePolicy
- 根据段中文档数量
- 差别较大,最好使用第一种
- 二者都不会删除文档
- 可以继承 MergePolicy 实现自己的段合并策略
- 举例可以实现基于时间的合并策略(非搜索高峰期执行)

- 是否进行合并,取决于

- mergeFactor 的值为0的段大小的平方 等于为1段尺寸大小
- 小于 minMergeMB ,降级为更低级别的段
- 大于或等于mergeFactor级别 设定的段尺寸,进行段合并
- 级别越高,合并的频率越低
- 超过最大值(maxMergeMB、maxMergeDocs)
- 永久不被合并
- mergeFactor 值设置的越大,合并频率也越低
- 是否进行合并,取决于
- LogByteSizeMergePolicy
- 在进行 optmize、explungDeletes 时,
- 会对要被合并的段进行选择
- 合并策略可自定义
- 比如:跳过超出某个大段的合并
- 对包含10% 被删除文档的段合并
- 比如:跳过超出某个大段的合并
- 随着时间推移,
- 出现少量很大的段
- 少量比 mergeFactor 更小的段
- 段的数量与段尺寸的对数成正比
- 这样比较有利于段数量维持在较低的值
- 较少段合并
- 提高吞吐量
- 两种策略都是 LogMergePolicy 的子类
- MergerScheduler
- 选取后,开始实行合并
- ConcurrentMergerScheduler
- 执行后台线程进行合并
- SerialMergerScheduler
- 调用者合并
- 可以自己实现合并方法,继承MergerScheduler
- 自己实现是非常高级的用法
- 带来的好处:

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









