







第 一章 概览
1.索引组件
将文本转化为快速搜索的格式,叫索引。包括的步骤
1.获取内容(Lucene并不实现)
·内容获取必须是以增量方式运行,即只访问上次运行后内容有改变的;
·活动的,持续运行的后台服务,能实时获取新文档或改变信息
·基于权限,需为文档增加访问控制列表,已验证用户的合法性
2.建立文档
·文档的主要带值的域:标题,正文,摘要,作者和链接
·正文较大时,需建立额外的域存放(如日期,地点)
·插入权值,对域或文档进行加权
3.文档分析
语汇单元化,词干提取器,文档索引
4.搜索组件
从索引查找单词,从而找到包含单词的文档。
5.建立查询
通过查询解析器,将用户文本处理成查询对象
6.搜索查询
检查索引
搜索理论模型:
·纯布尔模型:匹配文档与评分无关,无序
·向量空间模型:每个独立的项作为维度,查询语句与文档相关性由向量间距离得到
·概率模型:全概率方法计算匹配度
7.展现结果
2.索引用到的主要的类
1.IndexWriter(写索引)
负责创建索引或打开已有索引,以及向索引中修改被索引文档信息。它只提供针对索引文件的写入,不可读取。
2.Directory
描述了Lucene索引的存放位置。是抽象类,其子类负责具体制定索引的存储路径。
3.Analyzer(分析器)
IndexWriter不能直接索引文本,需先由Analyzer将文本分割成独立的单词。Analyzer主要负责从文档中提取词汇单元。
4.Document
一个包含多个Field对象的容器
5.Field
每个域包括一个域名和对应的域值,以及一组选项。
3.搜索过程核心类
·IndexSearcher
利用Directory实例来获取索引,以只读的方式发开索引。
·Term搜索的基本单元
·Query查询类
·TermQuery:是Query的子类,提供最基础的查询
·TopDocs:容器指针,指向前N个排名的搜索结果
第二章 构建索引
1.索引段
Lucene中采用倒排,即查询哪些文章包含单词X
2.基本的索引操作
2.1 添加
//创建IndexWriter
new IndexWriter(directory,new Analyzer(),IndexWriter.MaxFieldLength.UNLIMITED);//最后一个参数指示索引文件中所有的词汇单元
//添加文档
Document doc = new Document();
doc.add(new Field("id",value,Field.Store.YES,Index.NOT_ANALYZED));
writer.addDocument(doc);
//创建searcher,chaxun
IndexSearcher searcher = new IndexSearcher(directory);
Term t = new Term(filename,searchString);
Query query = new TermQuery[t];
searcher.search(query,1).totalHits;
i2.2 删除文档
writer.deleteDocuments(new Term(“”ID,documentID));
删除操作不会立即执行,需调用writer的commit()或close()方法
2.3域
- 域索引选项(Field.Index.*)
·Index.ANALYZED
使用分析器将域值分解成独立的词汇单元流,并使每个词汇单元能被搜索(适用于正文,标题,摘要)
·Index.NOT_ANALYZED
对域进行索引,但不对String值进行分析。实际上是将域值作为单一词汇单元(适用于URL,人名,日期)
Index.ANALYZED_NO_NORMS
是Index.Analysis的变体,不存储index-time boost
2.域存储选项
Store.YES
存储域值,原始字符串保存在索引中,并且可以恢复(URL,标题,数据库主键)
Store.NO
不存储域值,通常跟Index.ANALYZED共同来索引大的文本域值
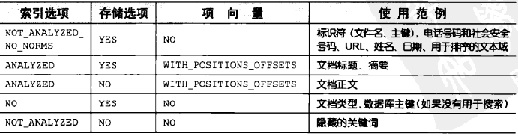
3.域排序选项
对于要排序的域,一般是只包含一个词汇单元。并且如果未对域进行加权操作,索引中也不能带有norm选项。因此,格式是Index.NOT_ANALYZED_NOT_NORMS(如果分析器只生成一个词汇单元,也可以用analyzed)
加权操作
加权操作可以在索引期间完成,同时也可以在搜索期完成。
String lowerDomain = getSenderDomain.toLowerCase();
if(isImportant(lowerDomain)){
doc.setBoost(1.5F) // 员工域加权因子
}加权基准(Norms)
·将文档中域的所有加权,再加上域的长短加权,计算出域或文档的单一字节。作为域或文档的一部分信息存储
·可以用setNorm对其进行修改
·norms在搜索期会带来高内存用量。因为norms的全部数组需要加载至RAM。
·norms并不支持松散存储,因此只要有一个文档域中包含了norms,那么随后的段合并操作,每个文档都会占用一个字节的norms空间
域截取
对于大的文档,需要添加控制RAM和硬盘空间使用量的安全机制,通常会对域进行截取(比如取其前200个单词)再进行索引。,调用IndexWriter的setMaxFieldLength()方法。
Directory子类

可以使用静态的FSDirectory.open方法,该方法可以根据当前的系统来选择最合适的directory子类。
并发,线程安全与锁机制
1.任意数量的IndexReader可以打开一个索引。利用这一点,可以用多个线程或者进程来并行搜索同一个索引
2.当建立IndexWriter,系统会分配锁,只有IndexWriter被关闭时才会释放。
3.IndexReader可以在IndexWriter修改时打开,但只有writer提交或者自己被重新打开时才能知道索引修改情况。
4.IndexReader/IndexWriter是线程友好的,多个线程可以共享同一个reader/writer
第三章 为应用程序添加搜索功能

简单查询的实现
public void testTerm() throws Exception{
Directory dir = getBookIndexDirectory();
IndexSearcher seacher = new IndexSearcher(dir);
//查询
Term t = new Term("subject","ant");
Query query = new TermQuery(t);
TopDocs docs = searcher.search(query,10);
//确认存在
assertEquals("Ant in Action",1,docs.totalHits);
//先关闭查询,再关闭文件
searcher.close();
dir.close();
}
public static void getBookIndex但在实际情况中,一般不关闭,因为searcher的创建花费很大















 7454
7454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









